
-
▼ Why ? What ?
-
▼ 데이터베이스 (Database)
-
Database (DB)
-
데이터베이스 시스템(Database System)이 왜 필요한가?
-
▼ DBMS (Database Management System)
-
DBMS
-
스키마(Schema) & 인스턴스(Instance)
-
DB를 다루기 위한 언어 - SQL (Structure Query Language)
-
Storage Manager
-
Query Processor
-
▼ Relation Model & RDBMS (+ NoSQL)
-
데이터 모델 (Data model)
-
관계형 모델 (Relational Model)
-
관계형 DBMS (RDBMS)
-
NoSQL
▼ Why ? What ?
이번에 처음으로 팀원들과 웹 개발 프로젝트를 진행하게 되어서 데이터베이스 뭔지, 그리고 Database는 어떻게 관리해야 하는 것인지에 대해 제대로 공부를 시작해보려고 한다.
(+) "Database" 강의에서 배운 Relational model에 대한 내용도 추가적으로 정리했다 !
▼ 데이터베이스 (Database)
Database (DB)
- 데이터를 조회하고 저장하는 프로그램
데이터베이스 시스템(Database System)이 왜 필요한가?
- 데이터의 중복성(redundancy)과 비일관성(inconsistency)을 해결 !
➜ 용량을 최소화할 수 있고 데이터를 효율적으로 다룰 수 있다.
( 이런 시스템을 유지하기 위한 규칙이 존재하긴 한다. ) - 데이터에 접근(access)하는 데 있어서 발생하는 어려움을 해결 !
➜ 애플리케이션이나 웹을 통해 여러 시스템들(사람들)이 데이터를 공유하고 사용할 수 있게 해준다. - 대량의 파일과 형식들로 인해 발생하는 데이터들의 고립(isolation)을 해결 !
- 가장 중요한 무결성(Integrity) 문제를 해결 !
➜ 데이터 연산에 제약(constraints)을 걸어서 해결한다.
ex) 뱅킹 데이터베이스 시스템에서 제약(account balance > 0)을 걸어 데이터 연산 이후에 잔액이 0원 이상일 경우에만 수행될 수 있도록 한다.
- 무결성(Integrity) ?
➜ 데이터의 정확성(중복이나 누락 X), 일관성(Consistency), 유효성
- 무결성(Integrity) ?
- 데이터베이스가 왜 필요한지 이해하기 위해선 트랜잭션(Transaction)과 ACID에 대해 아는 것은 필수적이다 !
ACID (참고자료) - [DB] 데이터베이스 트랜잭션(Transaction) & ACID — Uykm_Note (tistory.com)
[DB] 데이터베이스 트랜잭션(Transaction) & ACID
▼ Why ? What ? "Database" 강의시간에 배운 트랜잭션(Transaction)과 ACID는 데이터베이스를 다루기 전에 꼭 알고 있어야 하는 개념이기 때문에 따로 더 공부하고 정리해두려고 한다. ▼ DB Transaction 트랜
ukym-tistory.tistory.com
Database Architecture
- 데이터베이스 시스템 구조의 종류
- 중앙 집중식 데이터베이스 (Centralized database)
➜ 중앙 컴퓨터에 데이터의 대부분이 저장되며 다른 위치의 사용자가 단말 장치에 의해 접근이 가능한 데이터베이스 시스템. - 분산 데이터베이스 (Distributed Database)
➜ 네트워크를 통해 연결된 여러 개의 컴퓨터에 분산되어 있는 데이터베이스 시스템. - Client-Server
➜ 하나의 서버가 다수의 클라이언트에 연결되어 있는 데이터베이스 시스템. - 병렬 데이터베이스 (Parallel database)
➜ 단일 물리적 데이터베이스를 "공유"하는 여러 인스턴스를 실행하는 데이터베이스 시스템.
- 중앙 집중식 데이터베이스 (Centralized database)
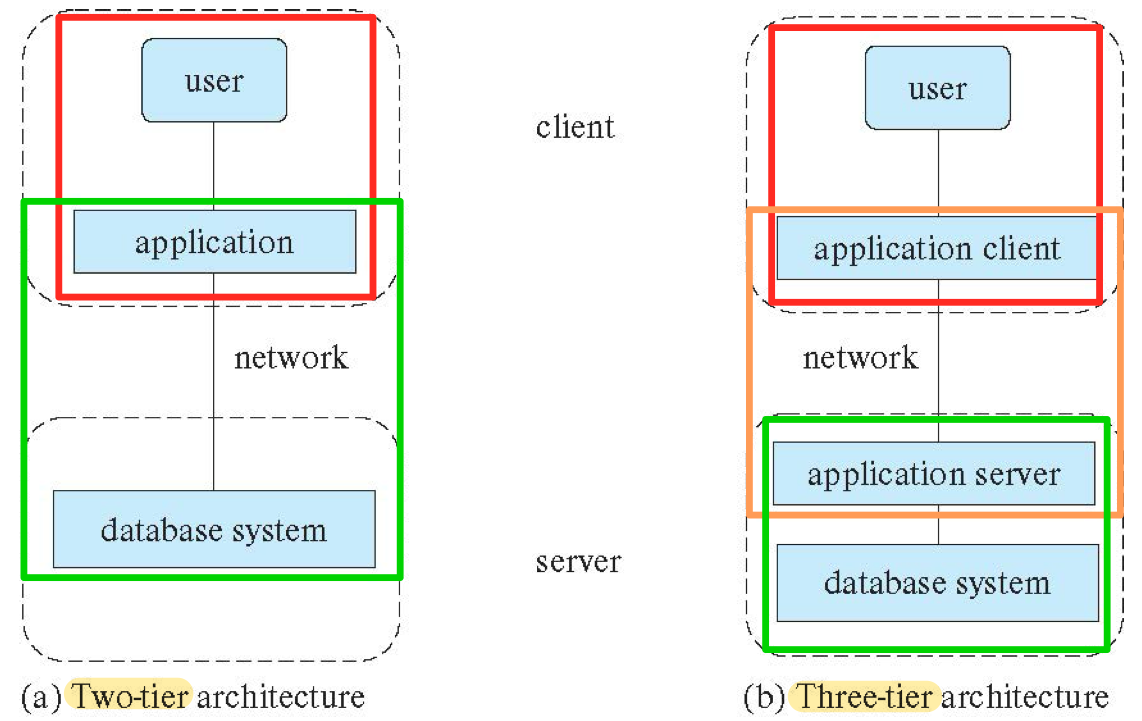
- Two-tier architecture & Three-tier architecture
▼ DBMS (Database Management System)
DBMS
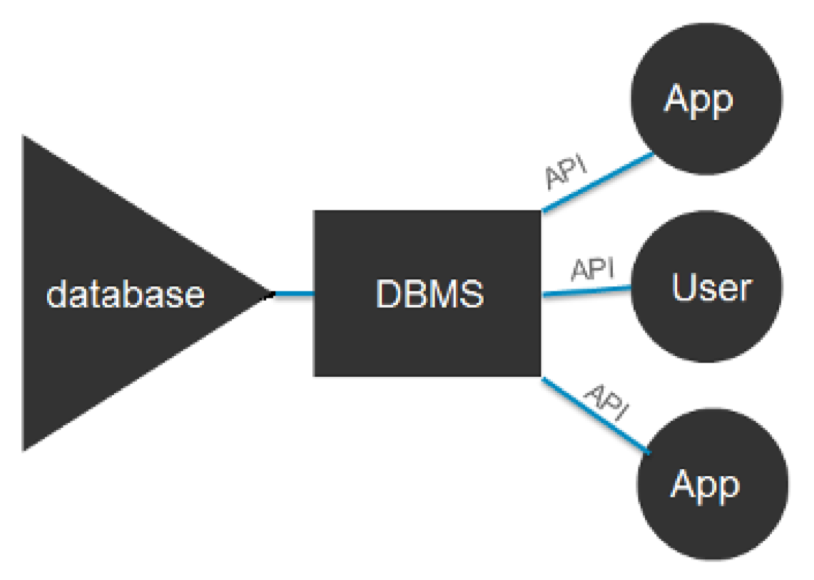
- 데이터베이스(Database)를 생성하고
데이터의 일관성(Consistency)이 유지될 수 있도록 관리하는 시스템 소프트웨어이다.
➜ DB와 최종 사용자(end users) 또는 애플리케이션 프로그램 사이의 인터페이스(interface) 역할도 한다.
( 접근성도 보장 )
- Perfomance monitoring/tuning(성능 모니터링)
- 백업(Backup)
- 복원(Recovery)
- DBMS가 중점적으로 관리하는 3가지
- 데이터(Data)
- 데이터베이스 엔진(Database engine)
- 스키마(Schema)
: DB의 논리 구조(logical structure)를 정의.
- 데이터(Data)
- File System, HDBMS, NDBMS, RDBMS, ODBMS, NoSQL 등 여러 종류의 DBMS 모델들이 있고,
주로 RDBMS를 다룬다
스키마(Schema) & 인스턴스(Instance)
- Logical schema
: 데이터베이스의 전체적인 논리적(logical) 구조. 개념적(conceptual) 스키마를 구체화한 것이라고 할 수 있다.
➜ 테이블 이름, 필드 이름, 엔티티 관계, 무결성 제약조건(예: 데이터베이스 관리 규칙)과 같은 정보를 기반으로 스키마 오브젝트를 정의.
➜ 즉, 데이터 구조화(structure)하고 데이터 간의 관계(relationship)을 정의해놓은 것이다.
( 단, 어떠한 기술 정보도 담고 있지 않는다. ) - Physical schema
: 데이터베이스의 전체적인 물리적(physical) 구조.
➜ 테이블 이름, 필드 이름, 엔티티 관계 등의 컨텍스트 정보 외에 논리적 데이터베이스 스키마 유형에 없는 기술 정보를 제공. - Instance
: 데이터베이스에서 특정 시점의 실제(actual) 내용.
➜ 내용을 계속 바뀔 수 있고 프로그래밍 언어에서 변수의 값과 유사하다고 볼 수 있다.
DB를 다루기 위한 언어 - SQL (Structure Query Language)
- DDL (Data Definition Language) : 데이터베이스 스키마를 정의하기 위한 명령어들.
➠ CREATE, ALTER, DROP, RENAME, TRUNCATE- 데이터베이스 스키마
- 무결성 제약 ➜ Primary Key
- 권한 부여(Authorization) ➜ 누가 어떤 것에 접근할지?
- DML (Data Manupulation Language) : 데이터를 다루기 위한 명령어들. (Query language)
➠ SELECT / INSERT, UPDATE, DELETE - DCL (Data Control Language) : DB에 접근하고 객체들을 사용할 수 있는 권한을 다루기 위한 명령어들
➠ GRANT, REVOKE - TCL (Transition Control Language) : DML에 의해 조작된 결과를 트랜잭션(작업 단위) 별로 제어하는 명령어들.
➠ COMMIT, ROLLBACK, SAVEPOINT
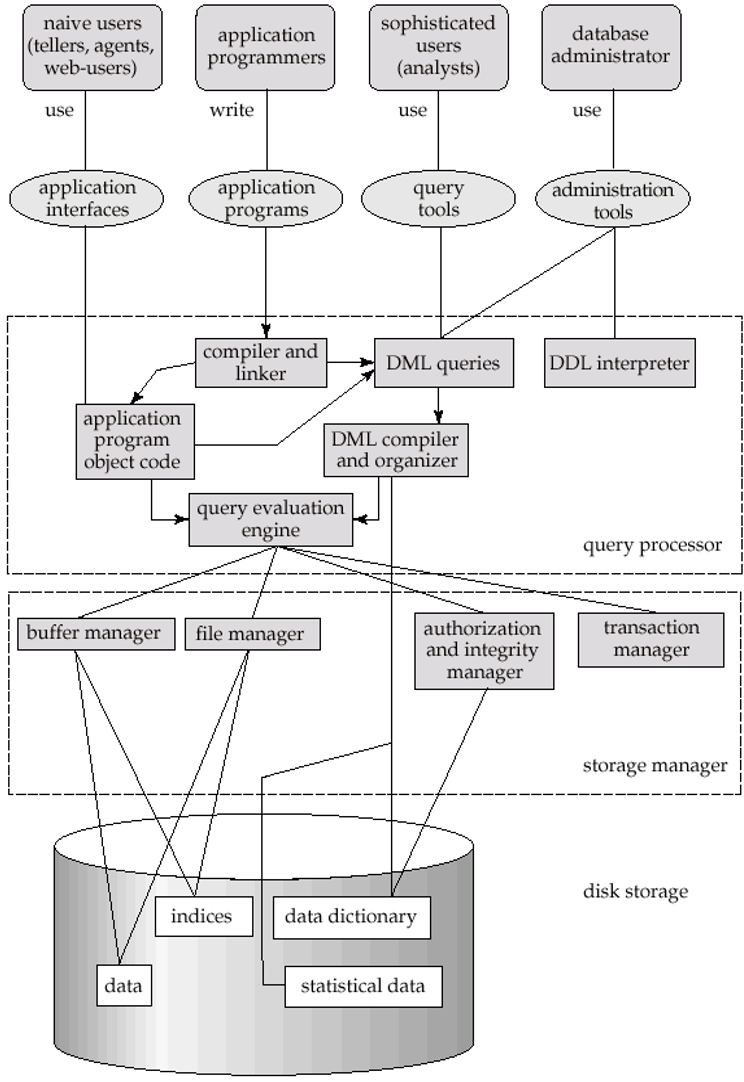
Storage Manager
- 데이터 베이스에 저장된 low-level data와 애플리케이션 프로그램사이에 인터페이스를 제공하는 프로그램 모듈.
➜ 효율적인 DB 작업을 위해 ! - Storage manager components
- Authorization and integrity manager
- Transaction manager
- File manager
- Buffer manager
- Authorization and integrity manager
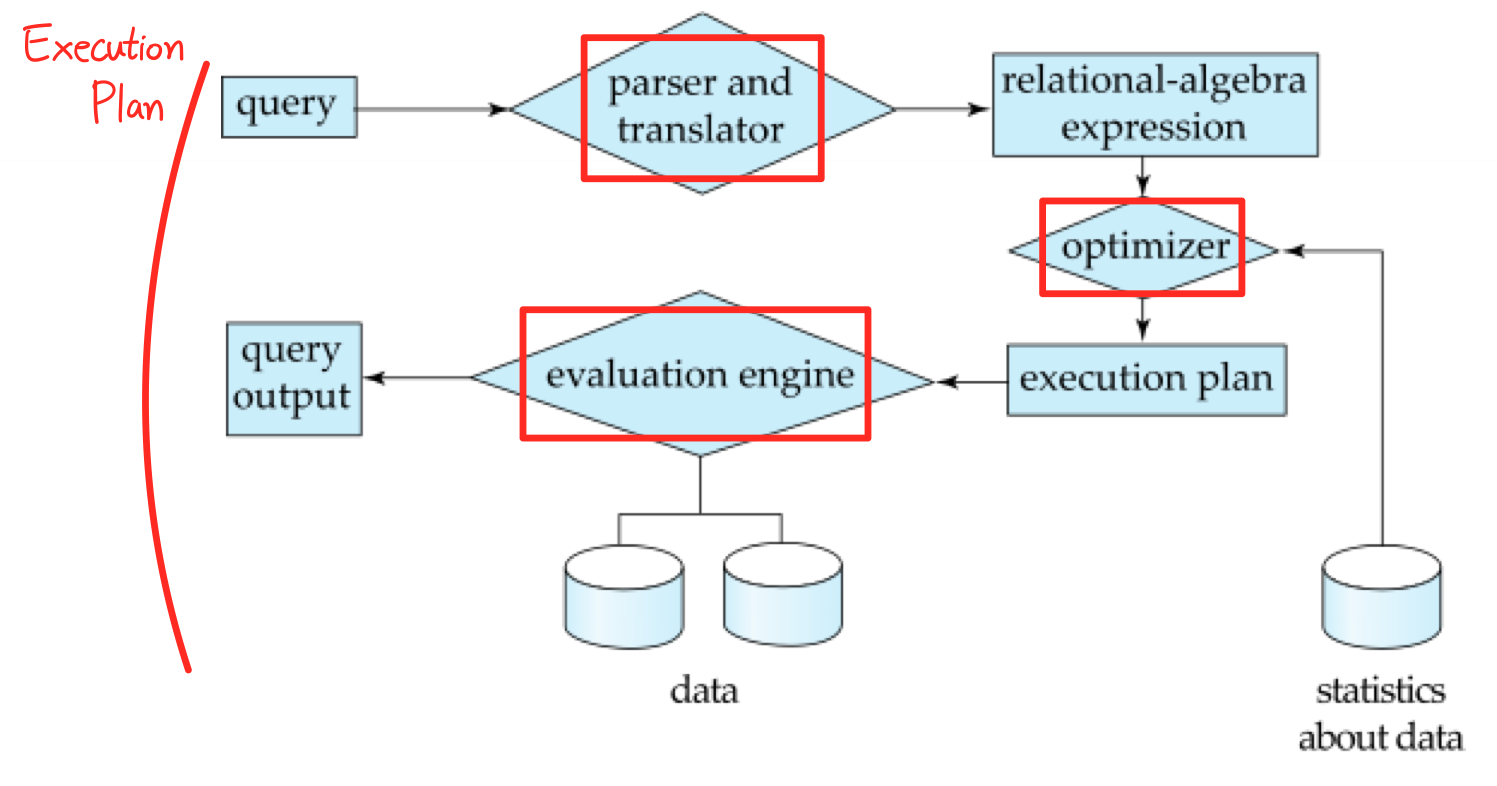
Query Processor
- Query processor componenet
- DDL interpreter
➜ DDL로 구성된 코드를 분석하고 "데이터 사전 (Data Dictionary)"에 내용을 저장한다.
( *Data Dictionary :데이터베이스에 저장되는 데이터에 관한 정보, 데이터를 관리(설명)하기 위한 데이터베이스 시스템 ) - DML compiler
➜ DML로 구성된 코드를 low-level instructions(명령어)로 구성된 evaluation plan으로 바꿔준다. - Query evaluation engine
➜ DML compiler에 의해 생성된 low-level instructions 실행.
- DDL interpreter
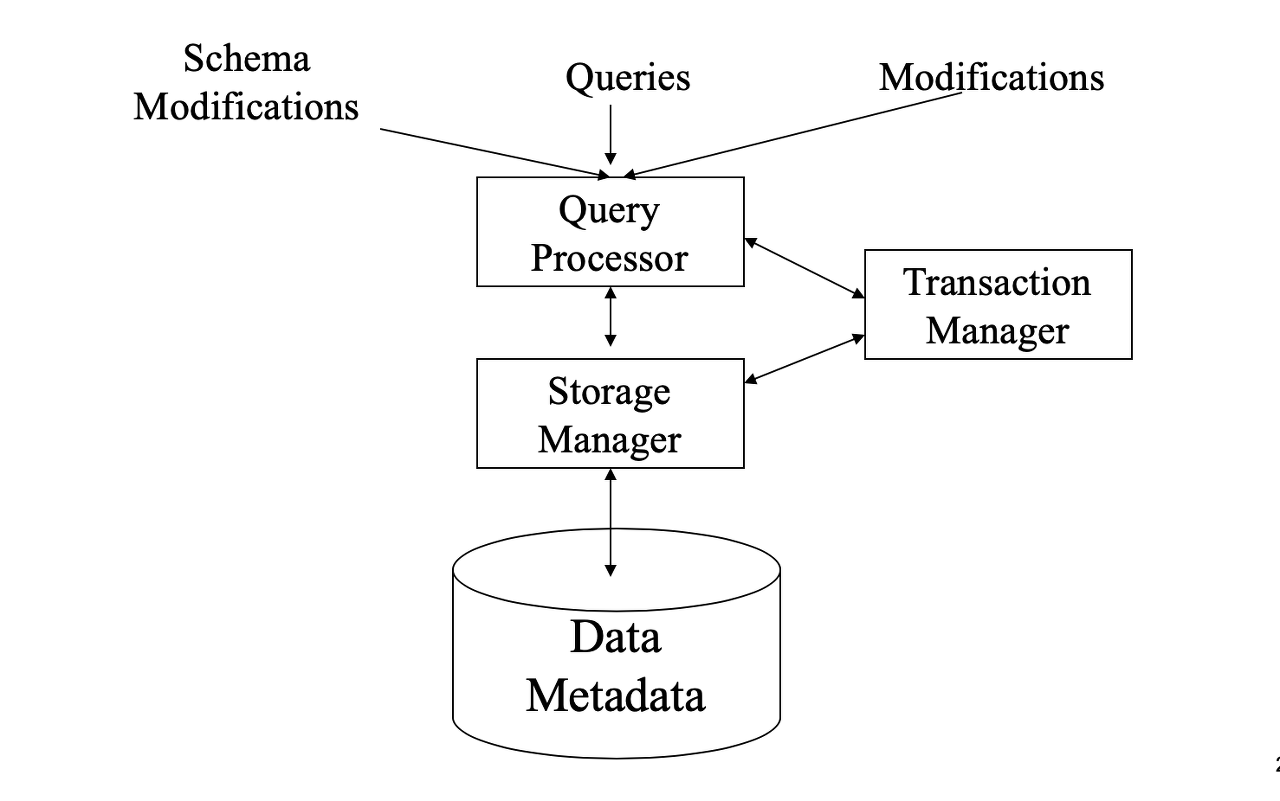
- Query Processor
➜ Parsing and translation
➜ Optimization
➜ Evaluation
▼ Relation Model & RDBMS (+ NoSQL)
데이터 모델 (Data model)
- 데이터, 데이터 관계(relationships), 일관성 제약(consistency constraints), 데이터 시멘틱(Semantic) 등을 나타내는 개념적 도구의 집합이다.
그리고 이러한 데이터 구조의 복잡도를 숨기기 위해 필요한 것이 "데이터 추상화 (Data abstraction)" 이다.
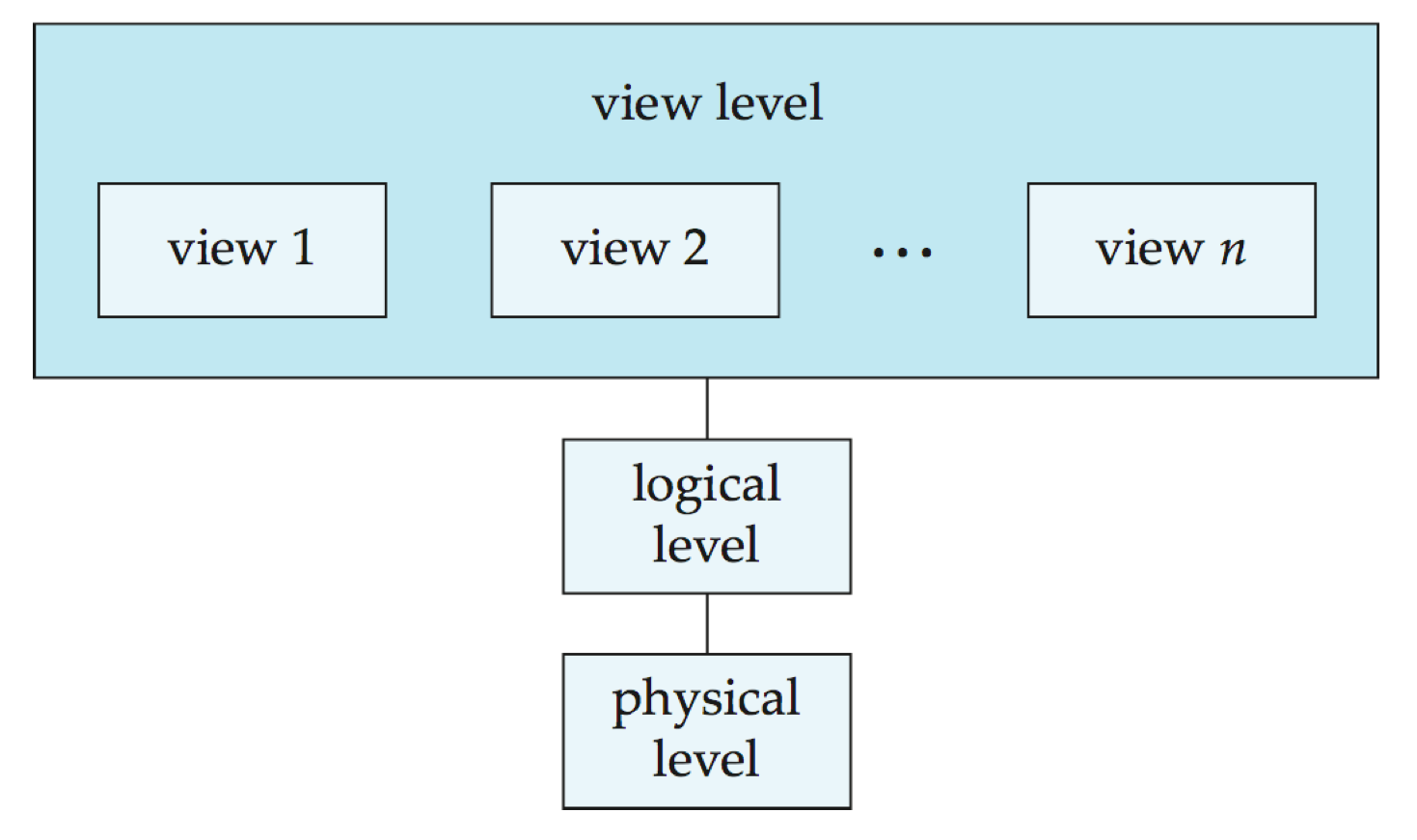
- 추상화 단계 (Levels of Abstraction)
- Physical level
➜ 기록이 어떻게 저장될 것인지. - Logical level
➜ 데이터와 데이터들 간의 관계. - View level
➜ 애플리케이션이 데이터 타입의 세부사항들을 숨긴다. (+ 보안 목적) - 데이터베이스 시스템의 아키텍쳐(Architecture)
- Physical level
관계형 모델 (Relational Model)
- 모든 데이터가 어떠한 관계(relation)를 맺어 구성된 튜플들의 집합, 즉 2차원 테이블의 형태로 표현된 것.
➜ 그리고 이러한 관계형 모델이 적용된 데이터베이스가 관계형 데이터베이스(Relational database)이다. - 관계형 모델
➜ 사용자는 데이터베이스에 어떤 정보가 포함되어 있는지와 데이터베이스로부터 어떤 정보를 원하는지를 직접 요청할 수 있고, DBMS는 데이터 구조와 쿼리에 응답하기 위한 검색 절차를 보여주도록 한다.
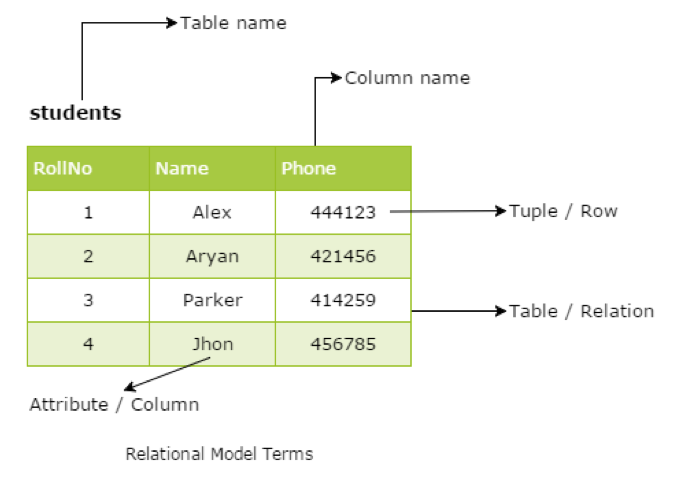
- 테이블(Table)
: 2차원의 테이블 형태로 저장되는 데이터 간의 관계(Relation). - 튜플(Tuple) / 행(Row)
: 테이블에서의 단일 행(Row) - 컬럼(Column) / 속성(Attribute)
: 특정 데이터 타입에 해당되는 값들의 집합. - 도메인(Domain)
: 관계(Relation)에 포함된 포함된 속성(Attribute)이 가질 수 있는 값의 집합. - 차수(Degree)
: 관계(Relation)에 들어있는 속성(Attribute)의 개수 - 기수(Cardinality)
: 관계(Relation)에 들어있는 튜플(Tuple)의 개수
- 테이블(Table)
- 관계(Relation)은 순서가 없는 집합의 개념이다.
관계형 모델(Relational model)의 특징
➜ 튜플(Tuple)은 순서에 상관없이 임의의 순서로 저장되는데, 튜플(Tuple)들은 삽입, 삭제, 업데이트가 실시간으로 발생한다.
➜ 그렇기 때문에, 각 튜플(Tuple)을 구별해주기 위해서 필요한 것이 키(Key)이다 !
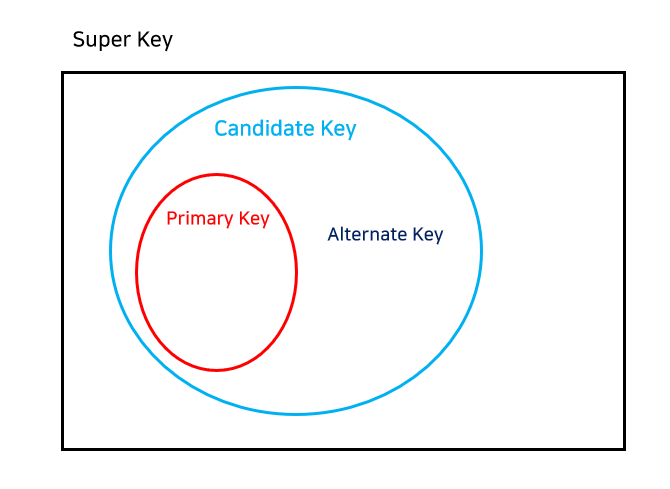
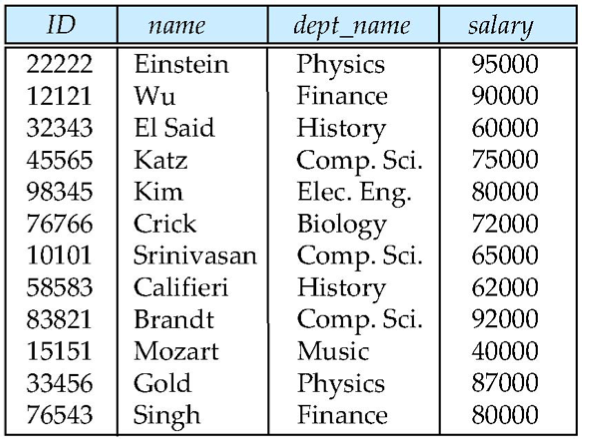
- Super Key
: 튜플을 식별할 수 있는 유일한 속성(attributes) 또는 집합. - Candidate Key (후보키)
: Super Key 중에서 최소성을 갖는 키(key).
➜ ID 또는 name 또는 dept.name 또는 salary - Primary Key (기본키)
: 튜플을 식별할 수 있는 유일한(unique) 키(key).
➜ 하나의 관계형 데이터베이스에선 반드시 하나만 가질 수 있고, 중복되서도 null 값을 가져서도 안된다. - Unique Key (고유키)
: PK처럼 값의 중복을 허용하지 않지만, null 값은 허용한다. - Alternate Key (대체키)
: Primary Key를 제외한 나머지 Candidate Key.
➜ Primary Key가 될 수 있는 Candidate Key들이다. - Foreign Key (외래키)
: 한 관계(relation)으로부터 다른 관계(relation)의 튜플을 참조하는 데 사용되는 속성(attribute)이다.
- Super Key
- 데이터베이스 스키마
- Database schema
: 데이터베이스의 논리적 구조.
➜ instructor(ID, name, dept_name, salary) - Database instance
: 데이터베이스에 있는 데이터의 스냅샷(snapshot).
- Database schema
관계형 DBMS (RDBMS)
- 흔히 생각하는 일반적인 데이터베이스의 구조이다
- 모든 테이블을 2차원 테이블 형태(Column / Row)로 구성하여 DB를 관리.
➠ 즉, 테이블들끼리 관계(Relation)를 맺어 모여있는 형태로 구성되어 있다. - ACID를 꼭 준수해야 하며, 그만큼 데이터의 안정성이 보장된다.
( ACID (약어) : Transaction이 안전하게 수행되는 것을 보장하기 위한 성질 )
➠ 데이터 처리 속도가 빠르나, 처리에 대한 부하가 발생시 성능 저하가 일어난다. - Oracle (+ MySQL), MSSQL, MariaDB, DB2Sybase
- 이러한 관계를 나타내기 위해 외래 키(FK : Foreign Key)를 사용.
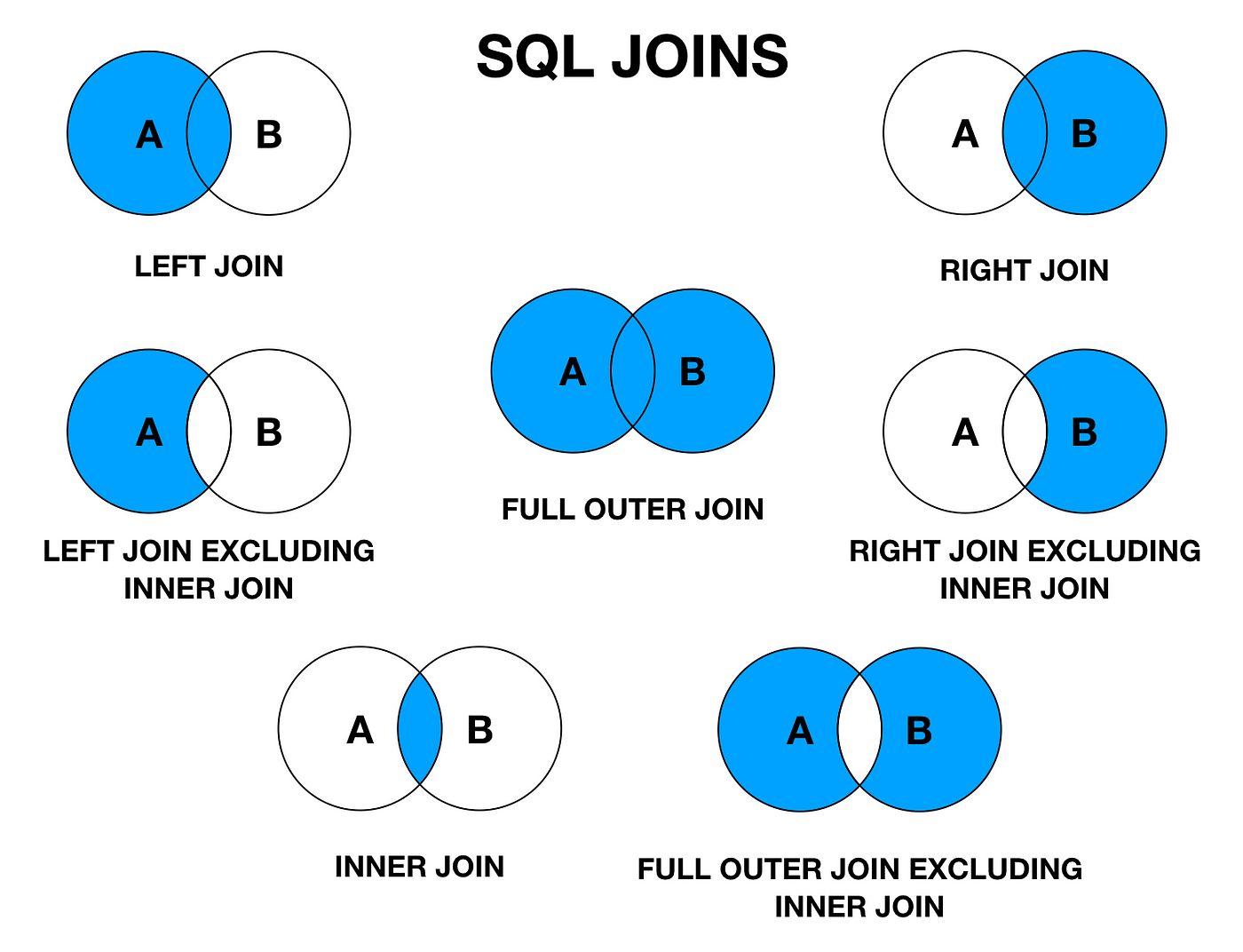
➠ FK를 이용해 테이블 간의 join이 가능하다 ! - join
➠ 둘 이상의 테이블을 연결해서 데이터를 검색하는 방법.
NoSQL
- RDBMS와 달리 관계를 정의하지 않은 구조이다.
➠ 비관계형 DBMS라고도 한다. - 전과 달리 RDBMS 방식으로는 더이상 처리할 수 없는 정도로 복잡하고 용량이 큰 데이터들이 등장하거나, SNS처럼 처리 속도를 극한으로 올려야 하는 서비스들이 등장하면서 부각되기 시작한 기술이다.
- 복잡도가 떨어져 많은 대용량의 데이터를 다룰 수 있지만,
중복 데이터가 존재할 수 있고 데이터가 규격화되어있지 않아 업데이트가 비교적 느리다.
➠ 정확도를 포기하고 자유도를 높인 방식, 업데이트가 자주 이루어지지 않은 시스템에서 사용하자.
▼ Why ? What ?
이번에 처음으로 팀원들과 웹 개발 프로젝트를 진행하게 되어서 데이터베이스 뭔지, 그리고 Database는 어떻게 관리해야 하는 것인지에 대해 제대로 공부를 시작해보려고 한다.
(+) "Database" 강의에서 배운 Relational model에 대한 내용도 추가적으로 정리했다 !
▼ 데이터베이스 (Database)
Database (DB)
- 데이터를 조회하고 저장하는 프로그램
데이터베이스 시스템(Database System)이 왜 필요한가?
- 데이터의 중복성(redundancy)과 비일관성(inconsistency)을 해결 !
➜ 용량을 최소화할 수 있고 데이터를 효율적으로 다룰 수 있다.
( 이런 시스템을 유지하기 위한 규칙이 존재하긴 한다. ) - 데이터에 접근(access)하는 데 있어서 발생하는 어려움을 해결 !
➜ 애플리케이션이나 웹을 통해 여러 시스템들(사람들)이 데이터를 공유하고 사용할 수 있게 해준다. - 대량의 파일과 형식들로 인해 발생하는 데이터들의 고립(isolation)을 해결 !
- 가장 중요한 무결성(Integrity) 문제를 해결 !
➜ 데이터 연산에 제약(constraints)을 걸어서 해결한다.
ex) 뱅킹 데이터베이스 시스템에서 제약(account balance > 0)을 걸어 데이터 연산 이후에 잔액이 0원 이상일 경우에만 수행될 수 있도록 한다.
- 무결성(Integrity) ?
➜ 데이터의 정확성(중복이나 누락 X), 일관성(Consistency), 유효성
- 무결성(Integrity) ?
- 데이터베이스가 왜 필요한지 이해하기 위해선 트랜잭션(Transaction)과 ACID에 대해 아는 것은 필수적이다 !
ACID (참고자료) - [DB] 데이터베이스 트랜잭션(Transaction) & ACID — Uykm_Note (tistory.com)
[DB] 데이터베이스 트랜잭션(Transaction) & ACID
▼ Why ? What ? "Database" 강의시간에 배운 트랜잭션(Transaction)과 ACID는 데이터베이스를 다루기 전에 꼭 알고 있어야 하는 개념이기 때문에 따로 더 공부하고 정리해두려고 한다. ▼ DB Transaction 트랜
ukym-tistory.tistory.com
Database Architecture
- 데이터베이스 시스템 구조의 종류
- 중앙 집중식 데이터베이스 (Centralized database)
➜ 중앙 컴퓨터에 데이터의 대부분이 저장되며 다른 위치의 사용자가 단말 장치에 의해 접근이 가능한 데이터베이스 시스템. - 분산 데이터베이스 (Distributed Database)
➜ 네트워크를 통해 연결된 여러 개의 컴퓨터에 분산되어 있는 데이터베이스 시스템. - Client-Server
➜ 하나의 서버가 다수의 클라이언트에 연결되어 있는 데이터베이스 시스템. - 병렬 데이터베이스 (Parallel database)
➜ 단일 물리적 데이터베이스를 "공유"하는 여러 인스턴스를 실행하는 데이터베이스 시스템.
- 중앙 집중식 데이터베이스 (Centralized database)
- Two-tier architecture & Three-tier architecture
▼ DBMS (Database Management System)
DBMS
- 데이터베이스(Database)를 생성하고
데이터의 일관성(Consistency)이 유지될 수 있도록 관리하는 시스템 소프트웨어이다.
➜ DB와 최종 사용자(end users) 또는 애플리케이션 프로그램 사이의 인터페이스(interface) 역할도 한다.
( 접근성도 보장 )
- Perfomance monitoring/tuning(성능 모니터링)
- 백업(Backup)
- 복원(Recovery)
- DBMS가 중점적으로 관리하는 3가지
- 데이터(Data)
- 데이터베이스 엔진(Database engine)
- 스키마(Schema)
: DB의 논리 구조(logical structure)를 정의.
- 데이터(Data)
- File System, HDBMS, NDBMS, RDBMS, ODBMS, NoSQL 등 여러 종류의 DBMS 모델들이 있고,
주로 RDBMS를 다룬다
스키마(Schema) & 인스턴스(Instance)
- Logical schema
: 데이터베이스의 전체적인 논리적(logical) 구조. 개념적(conceptual) 스키마를 구체화한 것이라고 할 수 있다.
➜ 테이블 이름, 필드 이름, 엔티티 관계, 무결성 제약조건(예: 데이터베이스 관리 규칙)과 같은 정보를 기반으로 스키마 오브젝트를 정의.
➜ 즉, 데이터 구조화(structure)하고 데이터 간의 관계(relationship)을 정의해놓은 것이다.
( 단, 어떠한 기술 정보도 담고 있지 않는다. ) - Physical schema
: 데이터베이스의 전체적인 물리적(physical) 구조.
➜ 테이블 이름, 필드 이름, 엔티티 관계 등의 컨텍스트 정보 외에 논리적 데이터베이스 스키마 유형에 없는 기술 정보를 제공. - Instance
: 데이터베이스에서 특정 시점의 실제(actual) 내용.
➜ 내용을 계속 바뀔 수 있고 프로그래밍 언어에서 변수의 값과 유사하다고 볼 수 있다.
DB를 다루기 위한 언어 - SQL (Structure Query Language)
- DDL (Data Definition Language) : 데이터베이스 스키마를 정의하기 위한 명령어들.
➠ CREATE, ALTER, DROP, RENAME, TRUNCATE- 데이터베이스 스키마
- 무결성 제약 ➜ Primary Key
- 권한 부여(Authorization) ➜ 누가 어떤 것에 접근할지?
- DML (Data Manupulation Language) : 데이터를 다루기 위한 명령어들. (Query language)
➠ SELECT / INSERT, UPDATE, DELETE - DCL (Data Control Language) : DB에 접근하고 객체들을 사용할 수 있는 권한을 다루기 위한 명령어들
➠ GRANT, REVOKE - TCL (Transition Control Language) : DML에 의해 조작된 결과를 트랜잭션(작업 단위) 별로 제어하는 명령어들.
➠ COMMIT, ROLLBACK, SAVEPOINT
Storage Manager
- 데이터 베이스에 저장된 low-level data와 애플리케이션 프로그램사이에 인터페이스를 제공하는 프로그램 모듈.
➜ 효율적인 DB 작업을 위해 ! - Storage manager components
- Authorization and integrity manager
- Transaction manager
- File manager
- Buffer manager
- Authorization and integrity manager
Query Processor
- Query processor componenet
- DDL interpreter
➜ DDL로 구성된 코드를 분석하고 "데이터 사전 (Data Dictionary)"에 내용을 저장한다.
( *Data Dictionary :데이터베이스에 저장되는 데이터에 관한 정보, 데이터를 관리(설명)하기 위한 데이터베이스 시스템 ) - DML compiler
➜ DML로 구성된 코드를 low-level instructions(명령어)로 구성된 evaluation plan으로 바꿔준다. - Query evaluation engine
➜ DML compiler에 의해 생성된 low-level instructions 실행.
- DDL interpreter
- Query Processor
➜ Parsing and translation
➜ Optimization
➜ Evaluation
▼ Relation Model & RDBMS (+ NoSQL)
데이터 모델 (Data model)
- 데이터, 데이터 관계(relationships), 일관성 제약(consistency constraints), 데이터 시멘틱(Semantic) 등을 나타내는 개념적 도구의 집합이다.
그리고 이러한 데이터 구조의 복잡도를 숨기기 위해 필요한 것이 "데이터 추상화 (Data abstraction)" 이다.
- 추상화 단계 (Levels of Abstraction)
- Physical level
➜ 기록이 어떻게 저장될 것인지. - Logical level
➜ 데이터와 데이터들 간의 관계. - View level
➜ 애플리케이션이 데이터 타입의 세부사항들을 숨긴다. (+ 보안 목적) - 데이터베이스 시스템의 아키텍쳐(Architecture)
- Physical level
관계형 모델 (Relational Model)
- 모든 데이터가 어떠한 관계(relation)를 맺어 구성된 튜플들의 집합, 즉 2차원 테이블의 형태로 표현된 것.
➜ 그리고 이러한 관계형 모델이 적용된 데이터베이스가 관계형 데이터베이스(Relational database)이다. - 관계형 모델
➜ 사용자는 데이터베이스에 어떤 정보가 포함되어 있는지와 데이터베이스로부터 어떤 정보를 원하는지를 직접 요청할 수 있고, DBMS는 데이터 구조와 쿼리에 응답하기 위한 검색 절차를 보여주도록 한다.
- 테이블(Table)
: 2차원의 테이블 형태로 저장되는 데이터 간의 관계(Relation). - 튜플(Tuple) / 행(Row)
: 테이블에서의 단일 행(Row) - 컬럼(Column) / 속성(Attribute)
: 특정 데이터 타입에 해당되는 값들의 집합. - 도메인(Domain)
: 관계(Relation)에 포함된 포함된 속성(Attribute)이 가질 수 있는 값의 집합. - 차수(Degree)
: 관계(Relation)에 들어있는 속성(Attribute)의 개수 - 기수(Cardinality)
: 관계(Relation)에 들어있는 튜플(Tuple)의 개수
- 테이블(Table)
- 관계(Relation)은 순서가 없는 집합의 개념이다.
관계형 모델(Relational model)의 특징
➜ 튜플(Tuple)은 순서에 상관없이 임의의 순서로 저장되는데, 튜플(Tuple)들은 삽입, 삭제, 업데이트가 실시간으로 발생한다.
➜ 그렇기 때문에, 각 튜플(Tuple)을 구별해주기 위해서 필요한 것이 키(Key)이다 !
- Super Key
: 튜플을 식별할 수 있는 유일한 속성(attributes) 또는 집합. - Candidate Key (후보키)
: Super Key 중에서 최소성을 갖는 키(key).
➜ ID 또는 name 또는 dept.name 또는 salary - Primary Key (기본키)
: 튜플을 식별할 수 있는 유일한(unique) 키(key).
➜ 하나의 관계형 데이터베이스에선 반드시 하나만 가질 수 있고, 중복되서도 null 값을 가져서도 안된다. - Unique Key (고유키)
: PK처럼 값의 중복을 허용하지 않지만, null 값은 허용한다. - Alternate Key (대체키)
: Primary Key를 제외한 나머지 Candidate Key.
➜ Primary Key가 될 수 있는 Candidate Key들이다. - Foreign Key (외래키)
: 한 관계(relation)으로부터 다른 관계(relation)의 튜플을 참조하는 데 사용되는 속성(attribute)이다.
- Super Key
- 데이터베이스 스키마
- Database schema
: 데이터베이스의 논리적 구조.
➜ instructor(ID, name, dept_name, salary) - Database instance
: 데이터베이스에 있는 데이터의 스냅샷(snapshot).
- Database schema
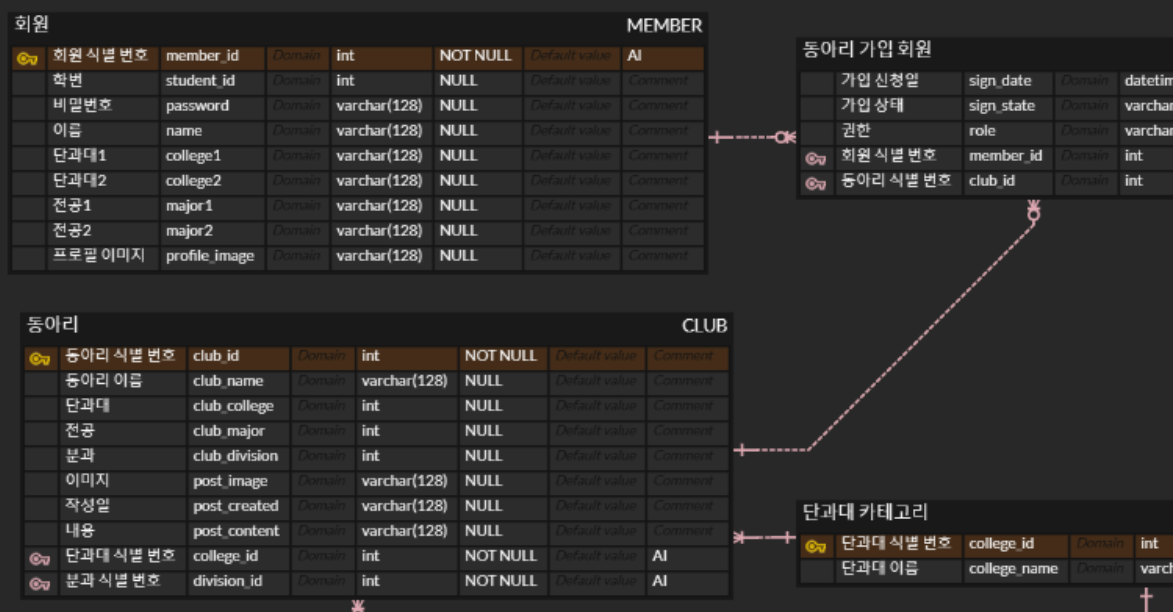
관계형 DBMS (RDBMS)
- 흔히 생각하는 일반적인 데이터베이스의 구조이다
- 모든 테이블을 2차원 테이블 형태(Column / Row)로 구성하여 DB를 관리.
➠ 즉, 테이블들끼리 관계(Relation)를 맺어 모여있는 형태로 구성되어 있다. - ACID를 꼭 준수해야 하며, 그만큼 데이터의 안정성이 보장된다.
( ACID (약어) : Transaction이 안전하게 수행되는 것을 보장하기 위한 성질 )
➠ 데이터 처리 속도가 빠르나, 처리에 대한 부하가 발생시 성능 저하가 일어난다. - Oracle (+ MySQL), MSSQL, MariaDB, DB2Sybase
- 이러한 관계를 나타내기 위해 외래 키(FK : Foreign Key)를 사용.
➠ FK를 이용해 테이블 간의 join이 가능하다 ! - join
➠ 둘 이상의 테이블을 연결해서 데이터를 검색하는 방법.
NoSQL
- RDBMS와 달리 관계를 정의하지 않은 구조이다.
➠ 비관계형 DBMS라고도 한다. - 전과 달리 RDBMS 방식으로는 더이상 처리할 수 없는 정도로 복잡하고 용량이 큰 데이터들이 등장하거나, SNS처럼 처리 속도를 극한으로 올려야 하는 서비스들이 등장하면서 부각되기 시작한 기술이다.
- 복잡도가 떨어져 많은 대용량의 데이터를 다룰 수 있지만,
중복 데이터가 존재할 수 있고 데이터가 규격화되어있지 않아 업데이트가 비교적 느리다.
➠ 정확도를 포기하고 자유도를 높인 방식, 업데이트가 자주 이루어지지 않은 시스템에서 사용하자.