
▼ Why ?
동아리 스터디에서 선배가 백엔드와 클라이언트 사이에 전반적인 흐름에 대해서 설명하는 시간을 가졌는데, 거기서 알게 된 여러 개념들 중 로드 밸런싱 말고도 병목 현상이라는 개념도 따로 정리해두면 좋을 것 같다는 생각이 들었다.
▼ 시스템 성능 문제의 두 가지 원인
응답 (Response) ?
- 처리 하나당 소요되는 시간
ex) 검색 엔진에서 키워드를 입력하고 '검색' 을 누른 후 검색 결과가 표시되기까지 걸리는 시간 = 응답시간
응답 문제
- 각 서버 이상으로 인한 응답 시간 지연 ➔ 로그 등을 보면 어느 정도 문제 파악 가능
- 네트워크 문제 + 물리적인 한계 ( cf . 시스템에 도달하기까지의 경로가 복잡한 경우 )
➔ 처리량 개선을 통해 시스템 전체 사용률을 개선하는 것이 일반적
처리량 (Throughput) ?
- 단위 시간당 처리하는 양
ex) 검색 엔진이 초당 받아 들이는 사용자 수
처리량 문제
- 대량의 데이터를 교환하는데 영역이 부족한 경우에 발생
➔ 물리적으로 데이터를 통과시킬 수 없을 때 처리량 관점의 병목 현상 발생
응답과 처리량은 밀접한 관계
- 응답이 매우 느린 시스템에선 다수의 사용자 요청이 시스템 내에 누적되므로 전체 처리량 ⇊
- 처리량이 포화 상태가 되면 리소스가 부족해져서 응답도 함께 악화
➜ 병목 현상을 개선하려면 반드시 응답과 처리량 모두 고려하여 진행
▼ 병목 현상 (Bottleneck)
- 전체 시스템의 성능이나 용량이 하나의 구성 요소로 인해 제한을 받는 현상
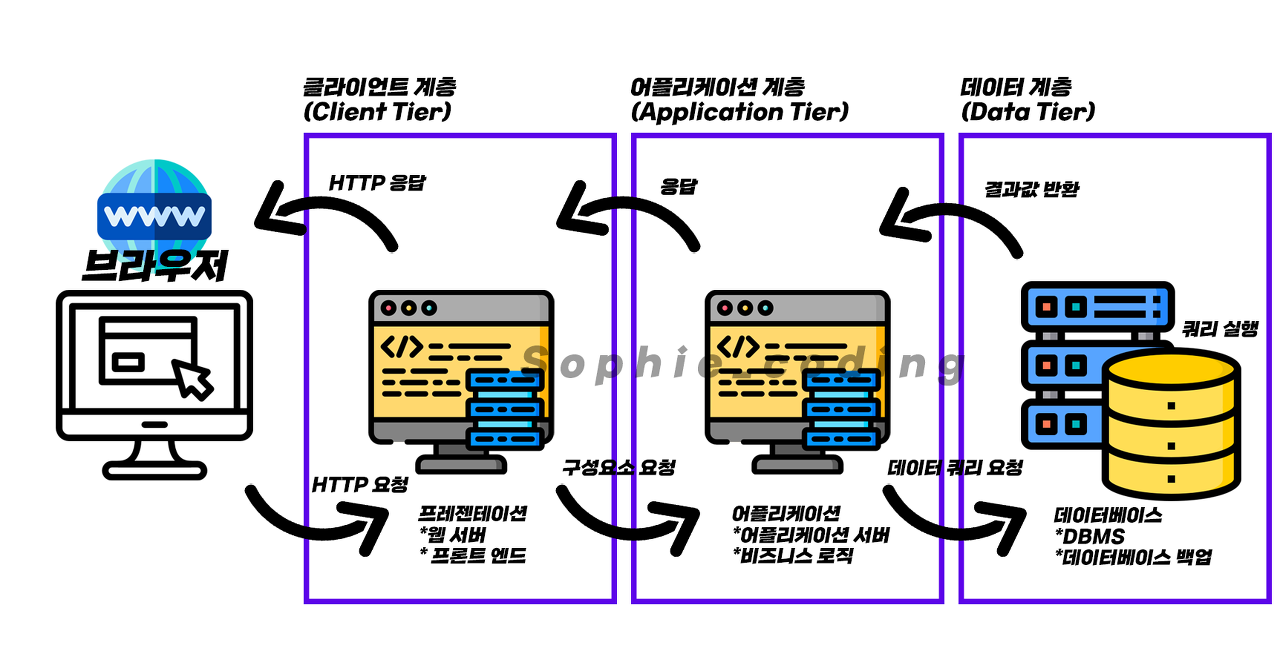
- 3 Tier 시스템에서 어플리케이션(API) 서버의 CPU 사용률이 높아져 처리량 ⇒ 한계
➜ API 서버에 대한 응답(Response) 시간이 악화
➜ API 서버 ⇒ 병목 지점
병목 지점은 반드시 존재
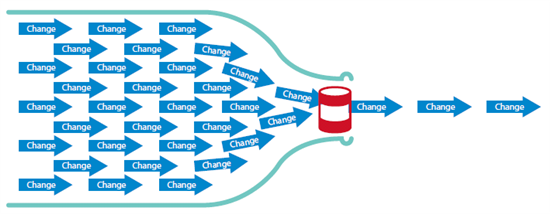
- 모든 서버, 소프트웨어, 물리 엔진이 균등하게 처리량을 분배하는 것은 이론상 불가능
➔ 특정 부분의 처리량이 조금이라 낮다면 그곳이 병목 지점
▼ 병목 현상을 어떻게 해결해야 할까 ?
샤딩 ( Sharding )
- 데이터를 샤드(Shard)라고 하는 더 작은 청크로 분할하고 여러 데이터베이스 서버에 저장하는 것
데이터베이스 샤딩이 중요한 이유
- 어플리케이션이 성장할수록 어플리케이션 사용자 수와 저장되는 데이터 양 ⇈
➜ 데이터베이스에서 병목 현상 발생
➜ 여러 샤드에서 더 작은 데이터 세트를 병렬로 처리하는 데이터베이스 샤딩으로 해결
(+) 응답 시간 개선
- 대규모의 단일 데이터베이스에선 특정 데이터를 검색하는 데 여러 행을 탐색해야 하므로 많은 시간 소요
➜ 데이터 샤드는 전체 데이터베이스보다 행 수가 적어 특정 데이터를 검색하거나 쿼리를 실행하는 데 걸리는 시간 단축
(+) 전체 서비스 중단 방지
- 데이터베이스를 호스팅하는 컴퓨터에서 장애가 발생
➔ 샤딩은 데이터베이스의 일부를 다른 컴퓨터에 배포
➔ 다른 컴퓨터에서 정상 작동하는 또 다른 샤드를 사용하여 작동시켜 어플리케이션 중단 X
➜ 혹은 샤딩이 샤드 간 데이터 복제와 함께 이루어진 경우, 샤드 중 하나를 사용할 수 없게 되더라도 대체 샤드에서 데이터에 엑세스하고 복원 가능
(+) 효율적인 크기 조정
- 데이터베이스 확장 지원 · 유지 관리를 위해 어플리케이션을 종료하지 않고도 런타임에 새 샤드 추가
▼ Why ?
동아리 스터디에서 선배가 백엔드와 클라이언트 사이에 전반적인 흐름에 대해서 설명하는 시간을 가졌는데, 거기서 알게 된 여러 개념들 중 로드 밸런싱 말고도 병목 현상이라는 개념도 따로 정리해두면 좋을 것 같다는 생각이 들었다.
▼ 시스템 성능 문제의 두 가지 원인
응답 (Response) ?
- 처리 하나당 소요되는 시간
ex) 검색 엔진에서 키워드를 입력하고 '검색' 을 누른 후 검색 결과가 표시되기까지 걸리는 시간 = 응답시간
응답 문제
- 각 서버 이상으로 인한 응답 시간 지연 ➔ 로그 등을 보면 어느 정도 문제 파악 가능
- 네트워크 문제 + 물리적인 한계 ( cf . 시스템에 도달하기까지의 경로가 복잡한 경우 )
➔ 처리량 개선을 통해 시스템 전체 사용률을 개선하는 것이 일반적
처리량 (Throughput) ?
- 단위 시간당 처리하는 양
ex) 검색 엔진이 초당 받아 들이는 사용자 수
처리량 문제
- 대량의 데이터를 교환하는데 영역이 부족한 경우에 발생
➔ 물리적으로 데이터를 통과시킬 수 없을 때 처리량 관점의 병목 현상 발생
응답과 처리량은 밀접한 관계
- 응답이 매우 느린 시스템에선 다수의 사용자 요청이 시스템 내에 누적되므로 전체 처리량 ⇊
- 처리량이 포화 상태가 되면 리소스가 부족해져서 응답도 함께 악화
➜ 병목 현상을 개선하려면 반드시 응답과 처리량 모두 고려하여 진행
▼ 병목 현상 (Bottleneck)
- 전체 시스템의 성능이나 용량이 하나의 구성 요소로 인해 제한을 받는 현상
- 3 Tier 시스템에서 어플리케이션(API) 서버의 CPU 사용률이 높아져 처리량 ⇒ 한계
➜ API 서버에 대한 응답(Response) 시간이 악화
➜ API 서버 ⇒ 병목 지점
병목 지점은 반드시 존재
- 모든 서버, 소프트웨어, 물리 엔진이 균등하게 처리량을 분배하는 것은 이론상 불가능
➔ 특정 부분의 처리량이 조금이라 낮다면 그곳이 병목 지점
▼ 병목 현상을 어떻게 해결해야 할까 ?
샤딩 ( Sharding )
- 데이터를 샤드(Shard)라고 하는 더 작은 청크로 분할하고 여러 데이터베이스 서버에 저장하는 것
데이터베이스 샤딩이 중요한 이유
- 어플리케이션이 성장할수록 어플리케이션 사용자 수와 저장되는 데이터 양 ⇈
➜ 데이터베이스에서 병목 현상 발생
➜ 여러 샤드에서 더 작은 데이터 세트를 병렬로 처리하는 데이터베이스 샤딩으로 해결
(+) 응답 시간 개선
- 대규모의 단일 데이터베이스에선 특정 데이터를 검색하는 데 여러 행을 탐색해야 하므로 많은 시간 소요
➜ 데이터 샤드는 전체 데이터베이스보다 행 수가 적어 특정 데이터를 검색하거나 쿼리를 실행하는 데 걸리는 시간 단축
(+) 전체 서비스 중단 방지
- 데이터베이스를 호스팅하는 컴퓨터에서 장애가 발생
➔ 샤딩은 데이터베이스의 일부를 다른 컴퓨터에 배포
➔ 다른 컴퓨터에서 정상 작동하는 또 다른 샤드를 사용하여 작동시켜 어플리케이션 중단 X
➜ 혹은 샤딩이 샤드 간 데이터 복제와 함께 이루어진 경우, 샤드 중 하나를 사용할 수 없게 되더라도 대체 샤드에서 데이터에 엑세스하고 복원 가능
(+) 효율적인 크기 조정
- 데이터베이스 확장 지원 · 유지 관리를 위해 어플리케이션을 종료하지 않고도 런타임에 새 샤드 추가