
🌑 컬렉션 프레임웍 (Collections Framework)
✔️ Collections Framework의 핵심 interface
🔸 Vector · Hashtable과 같은 기존의 Collections class들 대신 ArrayList · HashMap 을 사용하자
- 기존의 Collections class들은 호환을 위해 남겨둔 것이다
- Vector · Stack · Hashtable · Properties와 같은 class는 Collections Framework가 만들어지기 이전부터
존재했기 때문에 Collections Framework의 명명법을 따르지 않은 것이다.
🔹 Collection interface
- Collections class에 저장된 데이터를 읽고, 추가하고 삭제하는 등
Collection을 다루는데 가장 기본적인 메서드가 정의되어 있다. - ' 람다 (Lambda) ' & ' 스트림 (stream) '에 관련된 메서드들이 추가되었다. ( JDK1.8 ~ )
| 메서드 | 설명 |
| boolean add(Object o) boolean addAll(Collection c) |
지정된 객체(o) 또는 Collection(c)의 객체들을 Collection에 추가 |
| void clear() | Collection의 모든 객체 삭제 |
| boolean contains(Object o) boolean containsAll(Collection c) |
지정된 객체 또는 Collection의 객체들이 Collection에 포함되어 있는지 확인 |
| booelan equals(Object) | 동일한 Collection인지 비교 |
| int hashCode() | Collection의 hash code를 반환 |
| boolean isEmpty | Collection이 비어있는지 확인 |
| Iterator iterator() | Collection의 iterator를 얻어서 반환 |
| boolean remove(Object o) boolean removeAll(Collection c) |
지정된 객체 또는 Collection에 포함된 객체들 삭제 |
| boolean retainAll(Collection c) | 지정된 Collection에 포함된 객체만 남기고 다른 객체들은 Collection에서 삭제 이 메서드를 통해 Collection에 변화가 있으면 true를, 그렇지 않으면 false를 반환 |
| int size() | Collection에 저장된 객체의 개수를 반환 |
| Object[ ] toArray() | Collection에 저장된 객체를 객체배열(Object[ ])로 반환 |
| Object[ ] toArray(Object[] a) | 지정된 배열에 Collection의객체를 저장해서 반환 |
🔹 List interface
- 중복을 허용하면서 저장순서가 유지
| 메서드 | 설명 |
| void add(int index, Object element) boolean addAll(int index, Collection c) |
지정된 위치(index)에 객체(element) 또는 Collection에 포함된 객체들을 추가 |
| Object get(int index) | 지정된 위치(index)에 있는 객체를 반환 |
| int indexOf(Object o) int lastIndexOf(Obejct o) |
지정된 객체의 위치(index)를 반환 (List의 첫 번째 요소부터 순방향 / 마지막 요수부터 역방향) |
| ListIterator listIterator() ListIterator listIterator(int index) |
List의 객체에 접근할 수 있는 ListIterator를 반환 |
| Object remove(int index) | 지정된 위치(index)에 있는 객체를 삭제하고 삭제된 객체를 반환 |
| Object set(int index, Object element) | 지정된 위치(index)에 객체(element)를 저장 |
| void sort(Comparator c) | 지정된 비교자(comparator)로 List를 정렬 |
| List subList(Int fromIndex, int toIndex) | 지정된 범위(fromIndex부터 toIndex)에 있는 객체를 반환 |
🔹 Set interface
- 중복 허용 X · 저장순서 유지 X
- Set interface를 구현한 class
➠ HashSet, TreeSet, etc.
🔹 Map interface
- key (중복 X) & value (중복 O)을 하나의 쌍으로 묶어서 저장
- Map interface를 구현한 class
➠ Hashtable, HashMap, LinkedHashMap, SortedMap, TreeMap, etc.
| 메서드 | 설명 |
| void clear() | Map의 모든 객체를 삭제 |
| boolean containsKey(Object key) | 지정된 key객체와 일치하는 Map의 key객체가 있는지 확인 |
| boolean containsValue(Object value) | 지정된 value객체와 일치하는 Map의 value객체가 있는지 확인 |
| Set entrySet() | Map에 저장되어 있는 key - value쌍을 Map.Entry타입의 객체로 저장한 Set으로 반환 |
| boolean equals(Object o) | 동일한 Map인지 비교 |
| Object get(Object key) | 지정한 key객체에 대응하는 value객체를 찾아서 반환 |
| int hashCode() | hash code를 반환 |
| boolean isEmpty() | Map이 비어있는지 확인 |
| Set keySet() | Map에 저장된 모든 key객체를 반환 |
| Object put(Object key, Object value) | Map에 value객체를 key객체에 연결(mapping)하여 저장 |
| void putAll(Map t) | 지정된 Map의 모든 key-value쌍을 추가 |
| Object remove(Object key) | 지정한 key객체와 일치하는 key-value객체 삭제 |
| int size() | Map에 저장된 key-value쌍의 개수를 반환 |
| Collection values() | Map에 저장된 모든 value객체를 반환 |
🔹 Map.Entry interface
- Map interface의 내부 인터페이스(inner interface)
➠ interface도 inner class처럼 inner interface를 정의하는 것이 가능 - Map에 저장되는 key - value쌍을 다루기 위해 정의되었다.
| 메서드 | 설명 |
| boolean equals(Object o) | 동일한 Entry인지 비교 |
| Object getKey() | Entry의 key객체를 반환 |
| Object getValue() | Entry의 value객체를 반환 |
| int hashCode() | Entry의 hash code를 반환 |
| Object setValue(Object value) | Entry의 value객체를 지정된 객체로 바꾼다 |
🌒 ArrayList
✔️ ArrayList
🔹 ArrayList class
- List interface를 구현하기에 데이터의 저장순서가 유지되고 중복 허용
- 기존의 Vector를 개선한 것, 구현원리 & 기능적인 측면이 동일
- Object배열을 이용해서 데이터를 순차적으로 저장
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable {
...
transient Object[] elementData; // Object배열
...
}🔻 모든 종류의 객체를 담을 수 있다
🔹 ArrayList의 생성자 & 메서드
| 생성자 & 메서드 | 설 명 |
| ArrayList() | 크기가 10인 ArrayList를 생성 |
| ArrayList(Collection c) | 주어진 Collection이 저장된 ArrayList를 생성 |
| ArrayList(int initialCapacity) | 지정된 초기용량을 갖는 ArrayList를 생성 |
| boolean add(Object o) | ArrayList의 마지막 객체를 추가. 성공하면 true |
| void add(int index, Object element) | 지정된 위치(index)에 객체를 저장 |
| boolean addAll(Collection c) | 주어진 Collection의 모든 객체를 저장 |
| boolean addAll(int index, Collection c) | 지정된 위치(index)부터 주어진 Collection의 모든 객체를 저장 |
| void clear() | ArrayList를 완전히 비운다. |
| Object clone() | ArrayList를 복제 |
| boolean contains(Object o) | 지정된 객체(o)가 ArrayList에 포함되어 있는지 확인 |
| void ensureCapacity(int minCapacity) | ArrayList의 용량이최소한 minCapacity가 되도록 한다. |
| Object get(int index) | 지정된 위치(index)에 저장된 객체를 반환 |
| int indexOf(Object o) | 지정된 객체가 저장된 위치를 찾아 반환 |
| boolean isEmpty() | ArrayList가 비어있는지 확인 |
| iterator iterator() | ArrayList의 iterator객체를 반환 |
| boolean isEmpty() | ArrayList가 비어있는지 확인 |
| Iterator iterator() | ArrayList의 iterator객체를 반환 |
| int lastIndexOf(Object o) | 객체(o)가 저장된 위치를 끝부터 역방향으로 검색해서 반환 |
| ListIterator listIterator() | ArrayList의 ListIterator를 반환 |
| ListIterator listIterator(int index) | ArrayList의 지정된 위치부터 시작하는 ListIterator를 반환 |
| Object remove(int index) | 지정된 위치(index)에 있는 객체를 제거 |
| boolean remove(Object o) | 지정된 객체를 제거. (성공하면 true, 실패하면 false) |
| boolean removeAll(Collection c) | 지정한 Collection에 저장된 것과 동일한 객체들을 ArrayList에서 제거 |
| boolean retainAll(Collection c) | ArrayList에 저장된 객체 중에서 주어진 Collection과 공통된 것들만 남기고 나머지 삭제 |
| Object set(int index, Object element) | 주어진 객체(element)를 지정된 위치(index)에 저장 |
| int size() | ArrayList에 저장된 객체의 개수 반환 |
| void sort(Comparator c) | 지정된 정렬기준(c)으로 ArrayList를 정렬 |
| List subList(int fromIndex, int toIndex) | fromIndex부터 toIndex 사이에 저장된 객체를 반환 |
| Object[ ] toArray() | ArrayList에 저장된 모든 객체들을 객체배열로 반환 |
| Object[ ] toArray(Object[ ] a) | ArrayList에 저장된 모든 객체들을 객체배열 a에 담아 반환 |
| void trimToSize() | 용량을 크기에 맞게 줄인다. (빈 공간을 없앤다.) |
- 예시 코드
for(int i = list2.size()-1; i >= 0; i--) {
if(list1.contains(list2.get(i))
list2.remove(i);
}🔻 list2에서 list1과 공통되는 요소들을 찾아서 삭제
🔻 위 코드와 달리 변수 i를 증가시키면서 삭제한다면, 한 요소가 삭제될 때마다 빈 공간을 채우기 위해
나머지 요소들이 자리이동을 하여 올바른 결과를 얻을 수 없다.
- ArrayList를 생성할 때, 실제 저장할 요소의 개수보다 약간 여유있는 크기로 생성하자
➠ 크기를 벗어나면 자동적으로 크기가 늘어나지만 처리시간이 많이 소요된다
🔹 ArrayList & Vector의 장단점
- 배열을 이용한 자료구조는 데이터를 읽어오고 저장하는 데는 효율이 좋다 !
- 용량을 변경해야할 때 새로운 배열을 생성한 후 기존의 배열로부터 새로 생성된 배열로 데이터를 복사
➠ 효율이 상당히 떨어진다 ! - 배열의 중간에 위치한 객체를 추가하거나 삭제하는 경우 다른 데이터의 위치를
이동시켜 줘야 하기 때문에 다루는 데이터의 개수가 많을수록 작업시간이 오래 걸린다 !
public Object remove(int index) {
Object oldObj = null;
if(index < 0 || index >= size)
throw new IndexOutOfBoundsException("범위를 벗어났습니다.");
oldObj = data[index];
if(index != size-1) {
// data[index+1]에서 data[index]로 size-index-1개의 데이터를 복사
System.arraycopy(data, index+1, data, index, size-index-1);
}
data[size-1] = null;
size--;
return oldObj;
}🔻 Vector class의 remove() 메서드
✔️ Java API 소스 보는 방법
- JDK를 설치한 디렉토리의 src.zip 파일의 압축을 풀고,
package별로 찾아 찾아 들어가면 원하는 class의 소스를 볼 수 있다.
ex) ' src\java\util\Vector.java ' ➠ Vector class
🌓 LinkedList
✔️ LinkedList
🔹 LinkedList class
- 배열의 단점(크기 변경 X, 비순차적인 데이터의 추가 · 삭제가 비효율적)을 보완
➠ 불연속적으로 존재하는 데이터를 서로 연결(link)한 형태
➠ 요소를 삭제하거나 새로운 요소를 추가하는 작업 처리속도가 매우 빠르다 ! - 요소 접근방향이 단방향이기 때문에 다음 요소에 대한 접근과 달리 이전 요소에 대한 접근은 어렵다
➠ 이 점을 보완한 것이 ' 이중 연결리스트 (doubly linked list) '
➠ Doubly linked list가 LinkedList보다 많이 사용된다 ! - ' 이중 원형 연결리스트 (doubly circular linked list) '
➠ 이중 연결리스트 (doubly linked list)의 접근성보다 향상시킨 것
➠ doubly linked list의 첫 번째 요소와 마지막 요소를 서로 연결시킨 것이다 - 사실 LinkedList는 이름과 달리 doubly linked list로 구현되어 있다.
🔹 LinkedList의 생성자 & 메서드
- List interace를 구현했기에 ArrayList와 메서드의 종류 & 기능은 거의 같다
| 생성자 & 메서드 | 설 명 |
| LinkedList() | LinkedList객체를 생성 |
| LinkedList(Collection c) | 주어진 Collection을 포함하는 LinkedList객체를 생성 |
| boolean add(Object o) | 지정된 객체(o)를 LinkedList의 끝에 추가. 저장에 성공하면 true, 실패하면 false |
| void add(int index, Object element) | 지정된 위치(index)에 객체(element)를 추가 |
| boolean addAll(Collection c) | 주어진 Collection에 포함된 모든 요소를 LinkedList의 끝에 추가. 성공하면 true, 실패하면 false |
| void clear() | LinkedList의 모든 요소 삭제 |
| boolean contains(Object o) | 지정된 객체가 LinkedList에 포함되었는지 |
| boolean containsAll(Collection c) | 지정된 Collection의 모든 요소가 포함되었는지 알려준다. |
| Object get(int index) | 지정된 위치(index)의 객체를 반환 |
| int indexOf(Object o) | 지정된 객체가 저장된 위치(앞에서 몇 번째)를 반환 |
| boolean isEmpty() | LinkedList가 비어있는지 알려준다. 비어있으면 true |
| Iterator iterator() | iterator를 반환 |
| int lastIndexOf(Object o) | 지정된 객체의 위치(index)를 반환 (끝부터 역순검색) |
| ListIterator listIterator() | ListIterator를 반환 |
| ListIterator listIterator(int index) | 지정된 위치에서부터 시작하는 ListIterator를 반환 |
| Object remove(int index) | 지정된 위치(index)의 객체를 LinkedList에서 제거 |
| boolean remove(Object o) | 지정된 객체를 LinkedList에서 제거. 성공하면 true, 실패하면 false |
| boolean removeAll(Collection c) | 지정된 Collection의 요소와 일치하는 요소를 모두 삭제 |
| boolean retainAll(Collection c) | 지정된 Collection의 모든 요소가 포함되어 있는지 확인 |
| Object set(int index, Object element) | 지정된 위치(index)의 객체를 주어진 객체로 바꾼다 |
| int size() | LinkedList에 저장된 객체의 수를 반환 |
| List subList(int fromIndex, int toIndex) | LinkedList의 일부를 List로 반환 |
| Object[ ] toArray() | LinkedList에 저장된 객체를 배열로 반환 |
| Object[ ] toArray(Object[ ] a) | LinkedList에 저장된 객체를 주어진 배열에 저장하여 반환 |
| Object element() | LinkedList의 첫 번째 요소를 반환 |
| boolean offer(Object o) | 지정된 객체(o)를 LinkedList의 끝에 추가. 성공하면 true, 실패하면 false |
| Object peek() | LinkedList의 첫 번째 요소를 반환 |
| Object poll() | LinkedList의 첫 번째 요소를 반환하고 제거 |
| Object remove() | LinkedList의 첫 번째 요소를 제거 |
| void addFirst(Object o) void addLast(Object o) |
LinkedList의 맨 앞/끝에 객체(o)를 추가 |
| Iterator descendingIterator() | 역순으로 조회하기 위한 DescendingIterator() |
| Object getFirst() Object getLast() |
LinkedList의 첫 번째 / 마지막 요소 반환 |
| boolean offerFirst(Object o) boolean offerLast(Object o) |
LinkedList의 맨 앞 / 끝에 객체(o)를 추가. 성공하면 true, 실패하면 false |
| Object peekFirst() Object peekLast() |
LinkedList의 첫 번째 / 마지막 요소를 반환 |
| Object pollFirst() Object pollLast() |
LinkedList의 첫 번째 / 마지막 요소를 반환하면서 제거 |
| Object pop() | removeFirst()와 동일 |
| Object removeFirst() Object removeLast() |
LinkedList의 첫 번째 / 마지막 요소를 제거 |
| boolean removeFirstOccurence(Object O) boolean removeLastOccurence(Object O) |
LinkedList에서 첫 번째 / 마지막으로 일치하는 객체를 제거 |
🔹 LinkedList의 장단점
- 순차적으로 추가 / 삭제하는 경우 ➠ ArrayList > LinkedList
➠ 단, 저장공간을 초과해서 추가할 경우엔 LinkedList가 더 빠를 수 있다.
➠ 순차적으로 삭제할 경우엔 마지막 요소의 값을 null로 바꿔주기만 하면 되기 때문에 매우 빠르다 - 중간 데이터를 추가 / 삭제하는 경우 ➠ LinkedList ( 각 요소간의 연결만 변경 ) > ArrayList
- 데이터가 많아질수록 데이터에 대한 접근성이 떨어진다 !
- 각 상황에 맞게 ArrayList와 LinkedList를 조합해서 사용한다면 효율이 좋을 것
🌔 Stack & Queue
✔️ Stack
🔹 Stack class
- LIFO (Last In First Out)
- 순차적으로 데이터를 추가하고 삭제하기에 ArrayList와 같은 배열기반의 Collection class가 적합 !
- Java에서 별도의 Stack class를 구현하여 제공하고 있다.
🔹 Stack 메서드
| 메서드 | 설 명 |
| boolean empty() | Stack이 비어있는지 확인 |
| Object peek() | Stack의 맨 위에 저장된 객체를 반환. pop()과 달리 Stack에서 객체를 꺼내지 X. (비었을 때는 EmptyStackException 발생) |
| Object pop() | Stack의 맨 위에 저장된 객체를 꺼낸다. (비었을 때는 EmptyStackException 발생) |
| Object push(Object item) | Stack에 객체(item)을 저장 |
| int search(Object o) | Stack에서 주어진 객체(o)를 찾아서 그 위치를 반환. 못찾으면 -1을 반환 (배열과 달리 위치(index)는 0이 아닌 1부터 시작) |
🔹 Stack의 활용
- 수식 계산
- 수식 괄호 검사
- Word Processor의 undo/redo
- Web Browser의 뒤로/앞으로
✔️ Queue
🔹 Queue interface
- FIFO (First In First Out)
- 데이터를 꺼낼 때 항상 처음 위치(index)의 데이터를 삭제하므로, 추가/삭제가 쉬운 LinkedList가 적합 !
- Java에서 Queue를 interface로 정의해놓기만 하고 별도의 class를 제공 X
➠ 대신 Queue interface를 구현한 class들이 있다 !
➠ 구현한 class들은 Java API 문서를 참고하여 확인 가능 - Queue interface를 구현한 class 중에는 LinkedList class가 있다.
Queue q = new LinkedList(); // Queue 객체 생성
🔹 Queue 메서드
| 메서드 | 설 명 |
| boolean add(Object o) | 지정된 객체를 Queue에 추가. 성공하면 true를반환. 저장공간이 부족하면 IllegalStateException 발생 |
| Object remove() | Queue에서 객체를 꺼내 반환. 비어있으면 NoSuchElementException 발생 |
| Object element() | 삭제없이 요소를 읽어온다. peek와 달리 Queue가 비었을 때 NoSuchException발생 |
| boolean offer(Object o) | Queue에 객체를 저장. 성공하면 true, 실패하면 false를 반환 |
| Object poll() | Queue에서 객체를 꺼내서 반환. 비어있으면 null을 반환 |
| Object peek() | 삭제없이 요소를 읽어 온다. Queue가 비어있으며 null을 반환 |
| void clear() |
🔹 Queue의 활용
- 최근 사용 문서 코드
class QueueEx {
static Queue q = new LinkedList();
static final int MAX_SIZE = 5; // Queue에 최대 5개까지만 저장
public static void main(String[] args) {
System.out.println("help를 입력하면 도움말을 볼 수 있습니다.");
while(true) {
System.out.print(">>");
try {
// 화면으로부터 라인단위로 입력받는다.
Scanner s = new Scanner(System.in);
String input = s.nextLine().trim();
if("".equals(input)) continue);
if(input.equalsIgnoreCase("q")) {
System.exit(0);
} else if(input.equalsIgnoreCase("help")) {
System.out.println(" help - 도움말을 보여줍니다.");
System.out.println(" q 또는 Q - 프로그램을 종료합니다.");
System.out.println(" history - 최근에 입력한 명령어를 "
+ Max_SIZE + "개 보여줍니다.");
} else if(input.equalsIgnoreCase("history")) {
int i = 0;
// 입력받은 명령어를 저장하고,
save(input);
// LinkedList의 내용을 보여준다.
LinkedList tmp = (LinkedList)q;
ListIterator it = tmp.listIterator();
while(it.hasNext())
System.out.println(=+i + "." + it.next());
} else {
save(input);
System.out.println(input);
} // if(input.equalsIgnoreCase("q");
} catch(Exception e) {
System.out.println("입력오류입니다.");
}
} // while(true)
} // main()
public static void save(String input) {
// queue에 저장한다.
if(!"".equals(input))
q.offer(input);
// queue의 최대크기를 넘으면 제일 처음 입력된 것을 삭제한다.
if(q.size() > MAX_SIZE) // size()는 Collection interface에 정의
q.remove();
}
} // end of class🔻 Unix의 ' history ' 명령어를 Queue를 이용해서 구현한 코드
🔻 위의 예제 코드를 응용하면 최근 열어 본 문서들의 목록을 보여주는 기능을 쉽게 구현 가능
- 인쇄작업 대기목록
- 버퍼 (buffer)
✔️ PriorityQueue
🔹 PriorityQueue class
- Queue interface의 구현체 중의 하나로,
저장한 순서에 관계없이 우선순위(Priority)가 높은 것부터 꺼낸다.
Queue q = new PriorityQueue();🔻 인터페이스 obj = new 구현체();
- null은 저장할 수 없으며, null을 저장하면 NullPointerException이 발생
- 저장공간으로 배열을 사용하며, 각 요소를 ' 힙 (heap) '이라는 자료구조의 형태로 저장
- 힙 (heap) ➠ ' 이진 트리 (Binary tree) '의 한 종류로 가장 큰 값이나 가장 작은 값을 빠르게 찾을 수 있는 자료구조 !
Queue pq = new PriorityQueue();
pq.offer(3); // pq.offer(new Integer(3));
pq.offer(1);
pq.offer(5);
pq.offer(2);
pq.offer(4);
System.out.println(pq); // pq의 내부 배열 출력
Object obj = null;
// PriorityQueue에 저장된 요소를 하나씩 꺼낸다.
while((obj = pq.poll() != null)
System.out.println(obj);
}[1, 2, 5, 3, 4]
1
2
3
4
5
🔻 우선순위(Priority)는 숫자가 작을수록 높은 것이다
➠ 숫자뿐만 아니라 객체도 저장 가능. 단, 각 객체의 크기를 비교할 수 있는 방법을 제공해야 한다 !
➠ 위의 코드도 정수를 저장한 것처럼 보이지만,
Compiler가 ' Integer class '로 Auto-boxing 해준 것이기 때문에
사실 ' Integer class '의 객체를 저장한 것 !
➠ ' Integer '와 같은 ' Number '의 sub class들은 자체적으로 숫자를 비교하는 방법을 정의하고 있어
비교 방법을 지정해주지 않아도 된다 !
🔻내부 배열에 요소가 힙(heap)의 형태로 저장되었기 때문에, 저장한 순서와 다르게 저장된다.
✔️ Deque (Double-Ended Queue)
🔹 Deque interface
- Queue의 변형으로, 양쪽 끝에 추가 / 삭제가 가능 !
- Deque의 조상은 Queue이며, 구현체로는 ' ArrayDeque '과 ' LinkedList ' 등이 있다.
- Deque ➠ Stack + Queue
🔹 Deque의 메서드에 대응하는 Queue & Stack의 메서드
| Deque | Queue | Stack |
| offerLast() | offer() | push() |
| pollLast() | - | pop() |
| pollFirst() | poll() | |
| peekFirst() | peek() | |
| peekLast() | - | peek() |
🌔 Iterator · ListIterator · Enumeration
✔️ Iterator
🔹 Iterator interface
- Collection에 저장된 각 요소에 접근하는 기능을 가진 interface
- Collection interface에는 ' Iterator (Iterator를 구현한 class의 instance) '를 반환하는 iterator()를 정의
➠ iterator()는 List · Set (Collection interface의 자손)에도 포함되어 있어,
List · interface를 구현하는 Collections class는 iterator()가 각 Collection의 특징에 알맞게 작성되어 있다.
🔹 iterator 메서드
https://docs.oracle.com/javase/8/docs/api/java/util/iterator.html
JDK 20 Documentation - Home
The documentation for JDK 20 includes developer guides, API documentation, and release notes.
docs.oracle.com
🔹 참조변수의 타입 - ArrayList 타입, Collection 타입
Collection c = new ArrayList(); // 다른 Collection으로 변경시 이 부분만 수정
Iterator it = c.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}🔻 ArrayList 대신 Collection interface를 구현한 다른 Collections class에 대해서도 이와 동일한 코드 사용 가능 !
🔻 Iterator를 이용해서 Collection의 요소를 읽어오는 방법을 표준화하였다.
➠ 코드의 재사용성 ⇈
🔻 참조변수의 타입을 ArrayList타입이 아니라 Collection타입으로 한 이유
➠ Collection에 정의되지 않은 메서드는 사용되지 않았을 것을 확신할 수 있기에,
Collection interface를 구현한 다른 class (ex. LinkedList) 타입으로 변경할 때
참조변수 선언문 이후의 코드를 검토할 필요 X
🔻 List class들은 저장순서를 유지
➠ 위처럼 Iterator를 이용해서 읽어 온 결과와 저장 순서는 동일 ( ⟺ Set class ~ 저장 순서 유지 X )
- Map interface를 구현한 Collection class
➠ iterator() 직접 호출 불가능 !
➠ ' keySet() '이나 ' entrySet() '과 같은 메서드를 통해 key와 value를 각각 Set의 형태로 얻어 온 후에
다시 iterator()를 호출해야 Iterator를 얻을 수 있다.
Map = map = new HashMap();
Iterator it = map.entrySet.iterator();
// Set eSet = map.entrySet();
// iterator it = eSet.iterator();
✔️ ListIterator & Enumeration
🔹 Enumeration interface
- Iterator의 구버전 ➠ 이전 버전으로 작성된 소스와의 호환을 위해 남겨진 것
🔹 ListIterator interface
- Iterator interface를 상속받아서 기능을 추가한 interace
- Collection의 요소에 접근할 때 양방향으로의 이동 가능 !
ListIterator it = list.listIterator();
while(it.hasNext()) {
System.out.print(it.next()); // 순방향으로 진행
}
System.out.println();
while(it.hasPrevious()) {
System.out.print(it.previous()); // 역방향으로 진행
} 🔻 단, ' hasNext() ' 나 ' hasPrevious() ' 를 호출해서 이동할 수 있는지 확인
- List interface를 구현한 Collections class (ArrayList, LinkedList) 에서만 사용 가능 !
🔹 ListIterator 메서드
https://docs.oracle.com/javase/8/docs/api/java/util/ListIterator.html
ListIterator (Java Platform SE 8 )
An iterator for lists that allows the programmer to traverse the list in either direction, modify the list during iteration, and obtain the iterator's current position in the list. A ListIterator has no current element; its cursor position always lies betw
docs.oracle.com
- ' optional operation (선택적 기능) ' 이라고 표시된 메서드들은 반드시 구현할 필요 X
public void remove() {
throw new UnsupportedOperationException();
}🔻구현하지 않더라도 예외를 던져서 구현되지 않은 기능이라는 것을 메서드를 호출하는 쪽에 알리자 !
- ' remove() ' 를 호출하기 전에는 반드시 ' next() ' 가 호출된 상태이어야 한다 !
➠ next()로 읽어온 객체를 삭제하는 것이기 때문이다
➠ 요소가 삭제되면 데이터가 한 자리씩 당겨지며 해당 빈 자리가 채워진다.
MyVector v = new MyVector(); // MyVector - Iterator를 구현한 class
v.add("0");
v.add("1");
v.add("2");
v.add("3");
v.add("4");
System.out.println(v);
Iterator it = v.iterator();
it.next();
it.remove();
it.next();
it.remove();
System.out.println(v);[0, 1, 2, 3, 4]
[2, 3, 4]
🌕 Arrays
✔️ Arrays
🔹 Arrays class
- 배열(Array)를 다루는데 유용한 메서드들이 정의된 class
➠ 모두 static 메서드이다 ! - 같은 기능의 메서드가 배열의 타입(기본형 배열 · 참조형 배열)만 다르게 Overloading 되어 있다
🔹 Arrays 메서드 ( 매개변수의 타입이 int 배열인 메서드 )
- 배열의 복사
- copyOf() ➠ 배열의 전체
- copyOfRange() ➠ 배열의 일부 (지정된 범위의 끝은 포함 X)
- 배열 채우기
- fill ➠ 배열의 모든 요소를 지정된 값으로 채운다
- setAll()
➠ 배열을 채우는데 사용할 함수형 interface를 매개변수로 받는다
➠ 매개변수 ➙ 함수형 interface를 구현한 객체 or 람다식
int[] arr = new int[5];
Arrays.setAll(arr, () -> (int)(Math.random()*5)+1);
- 배열의 정렬과 검색
- sort() ➠ 배열 정렬
- binarySearch()
➠ 배열에 저장된 요소 검색 (검색할 범위를 반복적으로 절반씩 줄여가며 검색)
➠ 반드시 배열이 정렬된 상태여야 올바른 결과를 얻는다 !
➠ ' 순차 검색 (linear search) ' 에 비해 검색속도가 상당히 빠르다
➠ 큰 배열의 검색에 유리 !
- sort() ➠ 배열 정렬
- 배열의 비교와 출력
- equals() ➠ 일차원 배열에만 사용 가능
- deepEquals ➠ 다차원 배열의 비교에 사용 (배열의 모든 요소를 재귀적으로 접근해서 문자열 구성)
- toString() ➠ 일차원 배열에만 사용 가능
- deepToString() ➠ 다차원 배열에만 사용 가능
- 배열을 List로 변환
- asList(Object... a)
➠ 매개변수의 타입이 가변인수라서 배열 생성 없이 저장할 요소들만 나열하는 것도 가능
( 단, 기본형 배열은 불가능 ! ➜ 변환 필요 )
- asList(Object... a)
List list = Arrays.asList(new Integer[]{1,2,3,4,5});
List list = Arrays.asList(1,2,3,4,5);🔻 단, ' asList() ' 가 반환한 List의 크기는 변경 불가능
➠ 즉, 추가 / 삭제 불가능 !
➠ 저장한 내용은 변경 가능하다
List list = new ArrayList(Arrays.asList(1,2,3,4,5));🔻 이런 식으로 생성하면 크기도 변경 가능 !
- parallelXXX() & spliterator() & stream()
- parallelXXX() ➠ 보다 빠른 결과를 얻기 위해 여러 thread가 작업을 나누어 처리
- spliterator() ➠ 여러 tread가 처리할 수 있게 하나의 작업을 여러 작업으로 나누는 SpliIterator 반환
- stream() ➠ Collection을 stream으로 변환
🌖 Comparator & Comparable & 정렬
✔️ Comparable
🔹 Comparable interface
- 기본 정렬기준(오름차순)을 구현하는데 사용
➠ Wrapper class, String, Date, File과 같은 class들이 Comparable을 구현하고 있다
➠ Comparable interface를 구현하고 있는 class는 정렬이 가능하다는 것을 의미 !
public interface Comparable {
public int compareTo(Object o);
}
✔️ Comparator
🔹 Comparator interface
- 기본 정렬기준 외에 다른 기준으로 정렬하고자할 때 사용
public interface Comparator {
int compare(Object o1, Object o2);
boolean equals(Object obj); // Overriding이 필요할 수도 있다는 것을 알리기 위해 정의한 것
}
- Arrays.sort()
class ComparatorEx {
public static void main(String[] args) {
String[] strArr = {"cat", "Dog", "lion"};
Arrays.sort(strArr); // String의 Comparable 구현에 의한 정렬
System.outprintln(Arrays.toString(strArr));
Arrays.sort(strArr, String.CASE_INSENSITIVE_ORDER); // 대소문자 구분 X
System.outprintln(Arrays.toString(strArr));
Arrays.sort(strArr, new Descending()); // 역순 정렬
System.outprintln(Arrays.toString(strArr));
}
}
class Descending implements Comparator {
public int compare(Objec o1, Object o2) {
if(o1 instanceof Comparable && o2 instanceof Comparable) {
Comparable c1 = (Comparable)o1;
Comparable c2 = (Comparable)o2;
return c1.compareTo(c2) * -1; // -1을 곱해서 기본 정렬방식이 역으로 변경
// return c2.com
return -1;
}
}[Dog, cat, lion]
[cat, Dog, lion]
[lion, cat, Dog]
🔻 ' Arrays.sort() ' 는 배열을 정렬할 때, Comparator를 지정해주지 않으면 저장하는 객체
(주로 Comparable을 구현한 class의 객체)에 구현된 내용에 따라 정렬
🔻 String의 Comparable 구현은 문자열이 사전 순으로 정렬되도록 작성되어 있다
🔻 compare()의 매개변수가 Object타입이기 때문에 compareTo()를 바로 호출할 수 없으므로
먼저 Comparable로 형변환해야 한다 !
✔️ Comparable, Comparator 와 정렬과의 관계
🔹 Comparable과 Comparator의 차이
- ' Comparable.compareTo(T o) ' 메서드는 자기 자신과 매개변수로 받은 객체를 비교하는 것이고,
' Comparator.compare(T o1, T o2) ' 메서드는 두 개의 매개변수로 받은 객체들을 비교하는 것이다 - 일반적으로, Comparable은 기본(default) 순서를 정의하는데 사용되며, Comparator는 특별한(specific) 기준의 순서를 정의할 때 사용한다
왜 그럴까?
아래에 내림차순으로 정렬하기 위해 Comparable을 구현한코드와 Comparator를 구현한 코드 두 개가 있다
확인해보면 알 수 있듯이, Comparble과 달리 Comparator는 익명 객체를 생성하여 오버라이딩해준 ' compare() ' 메서드를 사용(비교 기준 설정)하는데 문제가 없다
앞서 말했듯이 ' Comaparble.compareTo(T o) ' 메서드는 자기 자신과 매개변수로 받은 객체를 비교하는 것이기 때문에, 그말은 즉 Comparator처럼 서로 다른 두 개의 동일한 타입의 객체를 비교하는 것이 아닌 익명 객체(자기자신; this)과 하나의 객체를 비교하는 것이다
➙ 그래서 Comparable를 구현한 클래스는 익명 객체를 생성해줄 수 없다.
이와 달리, 익명 객체를 활용하기 좋은 Comparator는 자신이 원하는 순서 기준을 여러 개 만들어 줄 수 있다 !
( 익명 객체의 장점이 익명 객체를 가리키는 참조변수의 이름만 다르게 하면 다양한 구현이 가능하다. )
➙ 그래서 Comparable은 기본 순서를 정의하는데 사용되며, Comparable는 순서 기준을 추가하고 싶을 때 사용한다고 말하는 것이다 !
- 정리하자면, Comparable은 객체 자체에 비교 가능한 특성을 부여해 주기 위한 interface, Comparator은 특정 비교 방법을 전달하기 위한 함수형 파라미터 성격이 강한 것이다
비교 기준을 제공하기 위해 Student class에서 Comparable을 구현해준 코드
// Comparble
class Student implements Comparable<Student> {
int age; // 나이
int classNumber; // 학급
Student(int age, int classNumber) {
this.age = age;
this.classNumber = classNumber;
}
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
}
익명 객체를 이용해 비교 기준을 여러 개 생성한 Comparator
// 학급 대소 비교 익명 객체
public static Comparator<Student> comp = new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.classNumber - o2.classNumber;
}
};
// 나이 대소 비교 익명 객체
public static Comparator<Student> comp2 = new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.age - o2.age;
}
};
🔹 정렬과의 관계
- 위와 과정을 통해 생성한 익명 객체를 매개변수로 받아 정렬(sort())하는 방법 (내림차순)
이때 매개변수로 받은 객체 comp의 타입은?
➜ Comparator class 타입이 되겠죠
Arrays.sort(arr, comp); // arr이 내림차순으로 정렬된다
- ' Arrays.sort() ' 로 정렬하려는 대상은 기본형 배열이 아닌 객체 배열이나 2차원 배열이어야 한다는 것을 기억하자
➜ 기본형 배열을 정렬해야 한다면, stream을 이용해 Wrapper class 타입으로 변환시켜야 한다
( 또는, Collections class 타입으로 변환시켜 ' Collections.sort() ' 를 이용하는 방법도 있다 )
int[] nums = new int[]{1, 3, 5, 2};
// Wrapper class 타입
Integer[] boxedNums = Arrays.stream(nums).boxed().toArray(Integer[]::new);
Arrays.sort(boxedNums, (a, b) -> a[0] - b[0]);
// Collection class 타입
ArrayList<Integer> numsList = (ArrayList<Integer>) Arrays.stream(nums).boxed().collect(Collectors.toList());
Collections.sort(list, (a, b) -> a[0] - b[0]);
- 사실 Java에서 내림차순 기준을 담고 있는 객체를 반환하는 ' Collections.reverseOrder() ' 를 제공해준다
( 리스트를 반대로 뒤집어주는 ' Collections.reverse() ' 메서드 제공 )
Arrays.sort(boxedNums, Collections.reverseOrder()); // OK
Arrays.sort(nums, Collections.reverseOrder()); // Error;
- 익명 객체를 생성하지 않고 람다식(익명 객체를 대신)을 이용하여 정렬하는 방법 (내림차순)
Arrays.sort(arr, (o1, o2) -> o2 - o1);
🌗 HashSet & TreeSet
✔️ HashSet
🔹 HashSet class
- Set interface를 구현한 가장 대표적인 Collections class
➠ 중복된 요소를 저장 X - List interface를 구현한 Collections class와 달리 저장순서를 유지 X
➠ 자체적인 저장방식에 따라 순서가 결정 !
➠ 저장순서를 유지하고 싶다면 LinkedHashSet 사용 - 내부적으로 HashMap을 이용하여 만들어진 것이며, Hashing을 이용해서 구현 !
🔹 HashSet 메서드
https://docs.oracle.com/javase/8/docs/api/java/util/HashSet.html
HashSet (Java Platform SE 8 )
This class implements the Set interface, backed by a hash table (actually a HashMap instance). It makes no guarantees as to the iteration order of the set; in particular, it does not guarantee that the order will remain constant over time. This class permi
docs.oracle.com
- boolean add(Object o)
class HashSetEx {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add(new String("abc"));
set.add(new String("abc"));
set.add(new Person("Kyu", 21));
set.add(new Person("Kyu", 21));
System.out.println(set);
}
}
class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
public boolean eqauls(Object obj) {
if(obj instance of Person) {
Person tmp = (Person)obj;
return name.equals(tmp.name) && (age == tmp.age);
}
return false;
}
public int hashCode() {
return (name + age).hashCode();
}
public String toString() {
return name + ":" + age;
}
}[abc, Kyu:21]
🔻 새로운 요소를 추가하기 전에 기존에 저장된 요소와 같은 것인지 판별하기 위해서
추가하려는 요소의 ' equals() ' 와 ' hashCode() ' 를 호출
➠ ' equals() ' 와 ' hashCode() ' 를 목적에 맞게 Overriding 해야 한다 !
public int hashCode() {
return Objects.hash(name, age); // int hash(Object... values)
}🔻 ' hashCode() '를 java.util.Objects class의 ' hash() '를 이용해서 Overriding 한 코드
🔹 HashCode()를 Overriding 할 때 만족해야 하는 3가지 조건

- 실행 중인 Application 내의 동일한 객체에 대해서 여러 번 ' hashCode() '를 호출해도 동일한 int 값 반환
(단, equals() 메서드의 구현에 사용된 멤버변수의 값이 바뀌지 않은 경우에만 !)
Person p = new Person("Kyu", 21);
int hashCode1 = p.hashCode();
int hashCode2 = p.hashCode()
p.age = 20;
int hashCode3 = p.hashCode();🔻 hashCode1 = hashCode2, 하지만 실행할 때마다 그 전과 같은 값일 필요는 X
🔻 ' p.age = 20 ' 처럼 equals() 메서드에 사용된 멤버변수의 값이 변경된 후에는
hashCode() 메서드가 동일한 int 값을 반환할 필요 X
🔻 String class는 문자열의 내용으로 hashCode를 생성하기 때문에
내용이 같은 문자열에 대한 hashCode() 메서드 호출은 항상 동일한 hashCode 반환 !
🔻 Object class는 객체의 주소로 hashCode를 생성하기 때문에
실행할 때마다 hashCode가 달라질 수 있다 !
- equals() 메서드를 이용한 비교에 의해서 true를 얻은 두 객체에 대해
' hashCode() ' 를 호출해서 얻은 결과는 반드시 같아야 한다 ! - Hashing을 사용하는 Collection의 성능을 향상시키기 위해선 equals() 메서드를 이용한 비교에 의해서
false를 얻은 두 객체는 ' hashCode() ' 호출에 대해 다른 int 값을 반환하는 것이 좋다 !
➠ 서로 다른 객체에 대해서 hashCode값이 중복되는 경우가 많아질수록
Hashing을 사용하는 Hashtable, HashMap과 같은 Collection의 검색속도가 떨어진다
✔️ TreeSet
🔹 TreeSet class
- ' 이진 검색 트리 (binary search tree) ' 라는 자료구조 형태로 데이터를 저장하는 Collection class
➠ 정렬, 검색, 범위검색(range search)에 높은 성능을 보인다
➠ TreeSet class는 Binary search tree의 성능을 향상시킨 ' Red - Black tree ' 로 구현되어 있다 !

class TreeNode {
TreeNode left; // left child node
Object element; // 객체를 저장하기 위한 참조변수
TreeNode right; // right child node
}
- Set interface를 구현했으므로 중복된 데이터의 저장을 허용 X
정렬된 위치에 저장하므로 저장순서 유지 X
- 두 객체를 비교할 방법을 필요 !
➠ TreeSet에 저장되는 객체가 Comparable을 구현 or TreeSet에게 Comparator를 제공
- 이진 검색 트리 ( binary search tree)
- 모든 Node는 최대 두 개의 Child node를 가질 수 있다
- Left Child node의 값 < Parent Child node의 값 < Right child node의 값
- Node의 추가 / 삭제 작업 비효율적 ! (순차적으로 저장하지 않기 때문에)
- 검색(범위검색)과 정렬에 유리 !
➠ 왼쪽 마지막 값에서부터 오른쪽 값까지 값을 ' Left node - Parent node - Right node ' 순으로 읽어오면
오름차순으로 정렬된 순서를 얻을 수 있다 - 중복된 값 저장 X
- 모든 Node는 최대 두 개의 Child node를 가질 수 있다
Set set = new TreeSet();
for(int i = 0; set.size() < 6; i++) {
int num = (int)(Math.random()*45) + 1;
set.add(num); // set.add(new Integer(num));
}
System.out.println(set);[5, 12, 24, 26, 33, 45]
🔻 따로 정렬하지 않아도 TreeSet은 요소를 정렬한 상태로 저장한다
- 오름차순 정렬의 경우
➠ 공백 - 숫자 - 대문자 - 소문자 순으로 정렬
🔹 TreeSet 메서드
https://docs.oracle.com/javase/8/docs/api/java/util/TreeSet.html
TreeSet (Java Platform SE 8 )
docs.oracle.com
- SortedSet subSet(Object fromElement, Object toElement)
- ' toElement ' 는 범위검색(range search)를 할 때 범위에 포함 X
- ' toElement ' 는 범위검색(range search)를 할 때 범위에 포함 X
- SortedSet headSet(Object toElement)
- ' toElement ' 보다 작은 값들 ➠ ' toElement '가 저장된 Node의 Left Nodes
- ' toElement ' 보다 작은 값들 ➠ ' toElement '가 저장된 Node의 Left Nodes
- SortedSet tailSet(Object fromElement)
- ' toElement ' 보다 큰 값들 ➠ ' fromElement '가 저장된 Node의 Right Nodes
🌘 HashMap ( & Hashtable )
✔️ HashMap
🔹 HashMap class
- Hashtable class와의 관계 = Vector class와 ArrayList와의 관계
- Map를 구현했으므로 Map의 특징인 key와 value를 묶어서 하나의 데이터(entry)로 저장한다는 특징이 있다
- Hashing을 사용 ➠ 많은 양의 데이터를 검색하는데 있어서 뛰어난 성능을 보인다 !
public class HashMap extends AbstractMap implements Map, Cloneable, Serializable {
transient Entry[] table;
...
static class Entry implements Map.Entry {
final Object key;
Object value;
...
}
} 🔻key & value는 하나의 class(' Entry ')로 정의해서 하나의 배열로 다룬다
➠ 데이터의 무결성(intergrity)적인 측면에서 더 바람직 !
- key ➠ Collection 내에서 유일해야 한다
value ➠ 데이터의 중복 허용 - Hashtable과 달리 key나 value의 값으로 null을 허용
- HashMap같이 Hashing을 구현한 Collection class들은 저장순서를 유지 X
➠ 한정되지 않은 범위의 비순차적인 값들의 빈도수는 HashMap을 이용하여 구한다
⟺ 한정된 범위 내에 있는 순차적인 값들의 빈도수는 배열을 이용하여 구한다
🔹 HashMap 생성자 & 메서드
https://docs.oracle.com/javase/8/docs/api/java/util/HashMap.html
HashMap (Java Platform SE 8 )
If the specified key is not already associated with a value (or is mapped to null), attempts to compute its value using the given mapping function and enters it into this map unless null. If the function returns null no mapping is recorded. If the function
docs.oracle.com
- HashMap.entrySet() ➠ key & value
- HashMap.keySet() ➠ key
- HashMap.values() ➠ value
✔️ Hashing & Hash function
🔹 Hash function
- 임의의 길이를 갖는 데이터를 입력받아 고정된 길이의 값, 즉 hashCode을 출력하는 function
➠ 데이터가 저장되어 있는 곳을 알려준다
🔹 Hashing

- Hash function을 이용해서 데이터를 Hash table에 저장하고 검색하는 기법
- Hashing을 구현한 Collection class
➠ HashSet, HashMap (Hashtable은 호환성 문제로 남겨두고 있는 것) - Hashing에서 사용하는 자료구조
➠ 배열 + LinkedList
🔹 Hash fuction의 알고리즘

- 서로 다른 key에 대해서 중복된 hashCode를 반환하지 않도록 Hash function을 생성하는 것이 중요하다 !
➠ LinkedList는 크기가 커질수록 검색속도가 떨어지는, 즉 검색에 불리한 자료구조이기 때문이다 - HashMap과 같이 Hashing을 구현한 Collection class에서는
Object class에 정의된 hashCode()를 Hash funtion으로 사용 !
➠ 객체의 주소를 이용하는 알고리즘으로 hashCode를 생성하기 때문에
모든 객체에 대해 hashCode()를 호출한 결과가 서로 유일하기 때문에 아주 좋은 방법이다
🔸 equals를 Overriding 할 때 주의해야 할 점
- 서로 다른 두 객체에 대해 equals() 메서드로 비교한 결과가 true인 동시에
hashCode() 메서드의 반환값이 같아야 같은 객체로 인식한다
➠ 따라서 equals() 메서드를 Overriding 할 때는 equals() 결과가 true인 두 객체의 hashCode() 메서드의
반환 결과의 값이 항상 같도록 hashCode()도 같이 적절하게 Overriding 해주어야 한다 !
🌚 TreeMap
✔️ TreeMap
🔹 TreeMap class
- Binary Search tree의 형태로 key & value 쌍으로 이루어진 데이터를 저장
➠ 검색과 정렬에 적합한 Collections class이다 - 검색에 관련된 대부분의 작업은 HashMap이 더 뛰어나다
➠ 다만 범위검색이나 정렬이 필요한 경우엔 TreeMap을 사용 !
🔹 TreeMap 생성자 & 메서드
https://docs.oracle.com/javase/8/docs/api/java/util/TreeMap.html
TreeMap (Java Platform SE 8 )
A Red-Black tree based NavigableMap implementation. The map is sorted according to the natural ordering of its keys, or by a Comparator provided at map creation time, depending on which constructor is used. This implementation provides guaranteed log(n) ti
docs.oracle.com
🌘 Properties
✔️ Properties
🔹 Properties class
- Hashtable class (HashMap class의 구버전) 을 상속받아 구현한 class
➠ key와 value을 (String, String) 형태로 저장
➠ 저장순서 유지 X - Application의 환경설정과 관련된 속성(property)을 저장하는데 사용
파일 입출력 기능을 제공한다는 점에서 HashMap (Hashtable) class와 차이가 있다
➠ properties 파일에 담긴 데이터를 관리하기 위한 class이다 - Collections Framework 이전의 구버전이므로 ' Iterator ' 가 아닌 ' Enumeration '을 사용
🔹 Properties 메서드
https://docs.oracle.com/javase/8/docs/api/java/util/Properties.html
Properties (Java Platform SE 8 )
Reads a property list (key and element pairs) from the input character stream in a simple line-oriented format. Properties are processed in terms of lines. There are two kinds of line, natural lines and logical lines. A natural line is defined as a line of
docs.oracle.com
- Object setProperty(String key, String value)
➠ 내부적으로 Hashtable의 put() 메서드를 호출
➠ 기존에 같은 key로 저장된 값이 있는 경우 그 값을 Object타입으로 반환, 그렇지 않을 때는 null을 반환 - String getProperty(String key)
String getProperty(String key, String defaultValue)
➠ Properties에 저장된 값을 읽어오는 메서드, 읽어오려는 key가 존재하지 않으면 defaultValue 반환 - void list(PrintStream out)
void list(PrintWriter out)
➠ Properties에 저장된 모든 데이터를 화면 또는 파일에 출력
➠ System.out은 System class에 정의된 PrintStream타입의 static 변수이다
🔹 파일로부터 읽어온 데이터의 인코딩(encoding) 변환
// commandline에서 intputfile을 지정해주지않으면 프로그램을 종료하게 되어있다.
Properties prop = new Properties();
String inputFile = args[0];
try {
prop.load(new FileInputStream(inputFile));
// prop.load(new FileInputStream('src/main/resources/db.properties'));
} catch(IOException e) {
System.out.println("지정된 파일을 찾을 수 없습니다.");
}
// 인코딩 변환
String name = prop.getProperty("name");
try {
name = new String(name.getBytes("8859_1"), "EUC-KR");
} catch(Exception e) {}🔻 파일로부터 읽어온 데이터의 인코딩을 라틴문자집합(8859_1)에서 한글완성형(EUC-KR 또는 KSC5601)으로 변환
➠ 우리가 사용하는 OS의 기본 인코딩(encoding)이 Unicode가 아니기 때문에 이러한 변환이 필요하다 !
🌗 Collections
✔️ Collections
🔹 Collections class
- Collection과 관련된 메서드를 제공
🔹 Collections 메서드
https://docs.oracle.com/javase/8/docs/api/java/util/Collections.html
Collections (Java Platform SE 8 )
Rotates the elements in the specified list by the specified distance. After calling this method, the element at index i will be the element previously at index (i - distance) mod list.size(), for all values of i between 0 and list.size()-1, inclusive. (Thi
docs.oracle.com
✔️ Collection의 동기화
🔹 Collection의 동기화 필요성
- 멀티 쓰레드(multi-thread) 프로그래밍에선 하나의 객체를 여러 thread가 동시에 접근 가능
데이터의 일관성(consistency)을 유지하기 위해선 공유되는 객체에 동기화(synchronization) 필요 - Vector · Hashtable과 같은 구버전(JDK1.2 이전) class들은 자체적으로 동기화 처리가 되어 있다
➠ Multi-thread 프로그래밍이 아닌 경우에는 불필요한 기능이 되어 성능 저하 - 새로 추가된 ArrayList · HashMap과 같은 Collection은 동기화가 필요한 경우에만
java.util.Collections class의 동기화 메서드를 이용해서 동기화처리가 가능하도록 변경
🔹 Collections class의 동기화 메서드
- synchronizedXXX
static Collection synchronizedCollection(Collection c)
static List synchronizedList(List list)
static Set synchronizedSet(Set s)
static Map synchronizedMap(Map m)
static SortedSet synchronizedSortedSet(SortedSet s)
static SortedMap synchronizedSortedMap(SortedMap m)
- 사용 예제 코드
List syncList = Collections.synchronizedList(new ArrayList(...));
✔️ 변경불가 Collection
🔹 읽기전용으로 만드는 메서드
- unmodifiableXXX
static Collection unmodifiableCollection(Collection c)
static List unmodifiableList(List list)
static Set unmodifiableSet(Set s)
static Map unmodifiableMap(Map m)
static NavigableSet unmodifiableNavigableSet(NavigableSet s)
static SortedSet unmodifiableSortedSet(SortedSet s)
static NavigableMap unmodifiableNavigableMap(NavigableMap m)
static SortedMap unmodifiableSortedMap(SortedMap m)
✔️ Singleton Collection
🔹 단 하나의 객체만울 저장하는 Collection을 만드는 메서드
- 매개변수로 지정되 요소를 저장하는 Collection을 반환
➠ 반환된 Collection은 변경 불가능
static list singletonList(Object o)
static Set singleton(Object o) // singletonSet이 아니다
static Map singletonMap(Object key, Object value)
✔️ 한 종류의 객체만 저장하는 Collection
🔹 Collection에 지정된 종류의 객체만 저장할 수 있도록 제한하는 메서드
- Collection에 모든 종류의 객체를 저장할 수 있다는 것은 장점이자 단점 !
➠ 대부분 한 종류의 객체를 저장한다 - 보통 ' 지네릭스(generics) ' 로 간단히 처리
➠ 아래와 같은 메서드들을 제공하는 이유는 호환성 때문이다 - checkedXXX
static Collection checkedCollection(Collection c, Class type)
static List checkedList(List list, Class type)
static Set checkedSet(Set s, Class type)
static Map checkedMap(Map m, Class keyType, Class valueType)
static Queue checkedQueue(Queue queue, Class type)
static NavigableSet checkedNavigableSet(NavigableSet s, Class type)
static SortedSet checkedSortedSet(SortedSet s. Class type)
static NavigableMap checkedNavigableMap(NavigableMap m, Class keyType, Class valueType)
static SortedMap checkedSortedMap(SortedMap m, Class keyType, Class valueType)
🌖 Collection class 정리 & 요약
✔️ Collection class 간의 관계
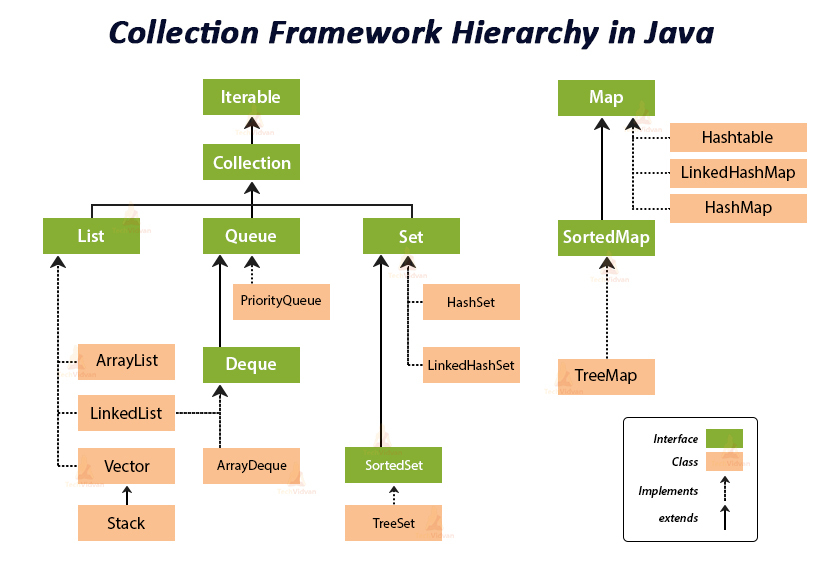

🔸 ArrayList
- 배열기반, 데이터의 추가 · 삭제에 불리(순차적인 추가 · 삭제는 제일 빠르다)
, 임의의 요소에 대한 접근성(accessiblity)은 뛰어나다 !
🔸 LinkedList
- 연결기반, 데이터의 추가 · 삭제에 유리, 임의의 요소에 대한 접근성이 좋지 않다
🔸 HashMap
- 배열 + 연결 기반, 추가 · 삭제 · 검색(최고 성능) · 접근성 모두 뛰어나다
🔸 TreeMap
- 연결기반, 정렬 · 검색(특히 범위검색)에 적합. 검색성능은 HashMap보다 떨어진다
🔸 Stack
- Vector를 상속받아 구현
🔸 Queue
- LinkedList가 Queue interface를 구현
🔸 Properties
- Hashtable을 상속받아 구현
🔸 HashSet
- HashMap을 이용해서 구현, 중복된 요소 저장 X, 객체 비교 기준 필요
🔸 TreeSet
- TreeMap을 이용해서 구현, 중복된 요소 저장 X, Binary Search Tree을 기반으로 저장하며 자동 정렬
🔸 LinkedHashMap & LinkedHashSet
- HashMap과 HashSet에 저장순서 유지 기능 추가
▼ Study📋
☑️ ArrayList로 생성된 리스트도 중간에 있는 데이터를 삭제할 때 삭제한
데이터의 자리를 채우기 위해 앞으로 당겨지는 것처럼 LinkedList도 유사하게 작동한다
☑️ hashCode의 성능이 좋으려면 Hash function가
서로 다른 키에 대해서 중복된 Hash code의 반환을 최소화해야 한다
☑️ 환경 설정과 관련된 속성(Property)을 properties 파일에 따로 저장해 관리하고,
이 파일을 다루기 위한 class가 Properties class !