
▼ Why ?
" [PCCP] 문자열과 해시함수 [4] " 를 풀면서 정렬하여 해결하는 방식을 생각하다가 ' Arrays.sort() ' 와 ' Collection.sort() ' 의 차이는 알아두는 것이 좋을 것 같아 찾아보게 되었다
▼ Arrays.sort()
- 간단하게 배열을 정렬하는 메서드라고 할 수 있다
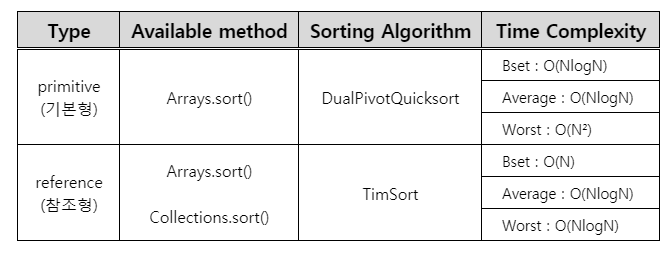
- 함수의 내부를 살펴보면, 기본형(Primitive) 타입의 배열을 매개변수로 받았을 때, DualPivotQuicksort을 채택한 것을 알 수 있다
// Arrays.java
public static void sort(int[] a) {
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}🔻 DualPivotQuicksort는 두 개의 피벗(Pivot)을 기준으로 정렬하기 때문에
일반적인 경우엔 Quicksort보다 나은 시간 복잡도를 보장하지만,
최악의 경우엔 Quicksort처럼 O(n^2)의 시간 복잡도를 피할 수 없다
- 하지만, 참조형(Reference) 타입의 배열을 매개변수로 받았을 때엔, TimSort를 채택한 것을 확인해볼 수 있다
public static void sort(Object[] a) {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a);
else
ComparableTimSort.sort(a, 0, a.length, null, 0, 0);
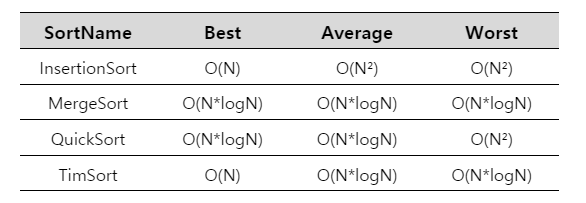
}🔻 TimSort - "삽입 정렬 (Insertion Sort)" + "병합 정렬 (Merge Sort)"
➜ 최선(Best)의 경우엔 삽입 정렬의 O(n)의 시간 복잡도를,
최악(Worst)의 경우엔 병합 정렬의 O(nlogn)의 시간복잡도를 보인다
▼ Collections.sort()
- 간단하게 `컬렉션`들을 정렬하는 메서드라고 할 수 있다
➜ `Collection` 인터페이스를 상속받는 인터페이스 : `List`, `Map`, `Set`, ...
➜ `Collections` 클래스는 `Collection` 인터페이스를 구현한 클래스인 것 ! - ' Collections.sort() ' 의 내부 소스도 살펴보자
1. ' Collections.sort() ' 는 ' list.sort() ' 메서드를 호출하는 것을 알 수 있다
//Collections.java
public static <T> void sort(List<T> list, Comparator<? super T> c) {
list.sort(c);
}
2. 그리고, 이 ' list.sort() ' 내부에선 ' Arrays.sort() ' 메서드를 호출하는 것을 확인할 수 있다
// List.java
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}// Arrays
static <T> void sort(T[] a, Comparator<? super T> c)
- 결국 ' Collection.sort() ' 메서드는 List 객체를 Object 타입의 배열(참조형 타입의 배열)로 변환하여 ' Arrays.sort() ' 메서드를 실행한다
➜ 따라서 ' Collection.sort() ' 메서드도 사실 근본적으로는 ' Arrays.sort() ' 메서드를 사용하는 것이다 - 하지만, ' Collection.sort() ' 메서드는 참조형 타입의 배열을 받기 때문에 TimeSort를 채택한 방식으로 정렬하여 최악의 경우(Worst case)에도 시간 복잡도로 O(nlogn)을 가진다 !
▼ 정리
- ' Arrays.sort() ' 이든 ' Collections.sort ' 이든 결국 정렬을 수행하기 위해선 ' Arrays.sort() ' 메서드를 사용한다
- 중요한 것은 어떤 타입(Primitive 또는 Reference)의 배열을 받아 수행하냐에 따라 실행되는 정렬 알고리즘이 달라진다는 것이다
▼ 운영체제 관련 개념
- Arrays와 Collections에 대해 찾아보다 알게 된 사실인데, 배열(Arrays)은 캐시 메모리(cache memory)를 사용하지만, 컬렉션(Collections)은 캐시 메모리를 사용하기에 적절하지 않다고 한다
- 캐시 메모리 (cache memory) ?
: 속도가 빠른 장치와 느린 장치 간의 속도차에 따른 병목 현상을 줄이기 위한 범용성 메모리
( CPU(주기억장치)와 RAM(메인 메모리) 사이에 위치 )
➜ 이 캐시 메모리에서 필요한 정보를 찾는 캐시 적중률(hit-rate)를 높일 수 있는 원리가 참조의 지역성이다 ! - 배열(Arrays)처럼 정렬되고 순차적인 접근이 일어나는 데이터 구조는 최근에 사용했던 데이터와 인접한 데이터가 참조될 가능성이 높다는 특성인 공간적 지역성이 성립한다고 한다
( " 참조의 지역성(Locality of Reference, Principle of Locality) " 에서 공간적 지연성의 한 종류로, 순차적 지역성(Sequential Locality)라고도 부른다 )