▼ What ?
이번 주 "Database" 강의 시간엔 트랜잭션이 실패하는 경우와 실패했을 때 어떤 식으로 복구하는지에 대해 배웠는데, 트랜잭션은 데이터베이스의 뼈대라고 할 수 있을 정도로 중요한 개념이라고 생각하기 때문에 오늘 배운 내용에 대해서도 복습하고 정리해두려고 한다.
▼ Failure Classification
Transaction failure
- Logical errors
➜ Internal errors(wrong inputs, data loss, overflow, resource limit, etc.)로 인해 트랜잭션이 완료될 수 없다.
➜ 사용자 애플리케이션의 트랜잭션 레벨에서 발생한 에러이기 때문에 가장 사소하고 복구가 쉽다. - System errors
➜ 'Deadlock' 과 같은 error condition이 발생하면, database system이 active 상태에 있는 트랜잭션을 종료해야 한다.
( Deadlock(교착 상태) ➜ 두 개 이상의 트랜잭션이 특정 자원(테이블 또는 행)의 lock을 소유한 채 다른 트랜잭션이 소유하고 있는 lock을 요구하면 아무리 기다려도 작업이 수행되지 않는 상태를 말한다. )
System crash
- 파워(Power) 고장이나 하드웨어 혹은 소프트웨어 오류(ex. 정전)로 인해 시스템이 충돌하고, 휘발성(volatile) 저장 장치의 데이터가 손실되며 트랜잭션 처리가 중단되는 경우이다.
( DBMS의 버퍼가 초기화되어 최신 데이터가 손실된다. )
➜ Recovery system의 주요 대상 ! - Fail-stop assumption
➜ 비휘발성(non-volatile) 저장 장치(디스크)의 데이터는 "System crash" 가 발생해도 데이터가 손상되지 않는다는 가정을 의미한다.
➜ "System crash" 은 디스크에 영향을 주지 않는다.
( Database system은 디스크 데이터의 손상을 방지하기 위해 수많은 무결설 검사를 수행한다. )
Disk failure
- 헤드가 충돌(Head crash; 손상)하거나 이와 유사한 비휘발성 메모리(디스크)가 고장이 나면 디스크 저장장치의 전체나 부분이 고장나게 된다.
➜ 이와 같은 붕괴(destruction)는 감지될 수 있다고 가정한다.
( 디스크 드라이브들이 고장을 감지하기 위한 checksum을 사용한다. )
➜ 주기적인 백업을 통해 복구가 가능하다.
▼ Recovery
Recovery at Storage Level
- Recovery system에서의 저장공간은 Volatile stroage, Nonvolatile storage, Stable storage로 나뉜다.
- Volatile storage (휘발성 저장장치)
➜ System crash를 피할 수 없다.
( ex. main memory, cache memory ) - Nonvolatile storage (비휘발성 저장장치)
➜ System crash에 영향을 받지 않는다.
( ex. disk, tape, flash meomry, non-volatile RAM )
➜ 단, 시간이 지남에 따라 마모되고 신뢰성이 떨어질 수 있다. - Stable storage
➜ 어떤 failure에도 고장나지 않는 이론적인(mythical) 형태의 저장장치이다.
➜ 중복되지 않는, 서로 다른 non-volatile 매체(media)에 여러 개의 사본을 유지함으로써 근사적으로 데이터 손실이 없도록 할 수 있다.
- Volatile storage (휘발성 저장장치)
- 트랜잭션은 디스크에서 메인 메모리로 데이터를 입력(input)하고, 다시 그 데이터를 디스크로 출력(output)한다.
➜ 이때, 디스크와 메인 메모리 사이의 입출력(I/O)은 블록(block) 단위로 이루어진다 !
Stable-Storage Implementation
- Stable storage를 구현하기 위해선, 데이터의 블록(block)들을 분리된 여러 non-volatile storage(디스크)에 사본으로 저장하여 유지되어야 한다.
➜ 그러한 사본들은 재난으로 인한 데이터 손실을 방지하기 위해 원격(remote) 사이트(site)에도 저장되어 있어야 한다. - 고장(오류)으로부터 복구하기 위한 방법 (Recovery)
- 일관성이 없는(inconsistent) 블럭들을 먼저 찾아야 한다.
- Expensive solution ➜ 모든 디스크 블록(block)을 두 개씩 일일히 비교해보는 방법
- Better solution - RAID system에서 사용하는 방식
➜ 작동 중인 디스크의 기록을 non-volatile storage(Flash, Non-volatile RAM 또는 special area of dist)에도 저장한다.
➜ 그렇게 저장된 정보를 일관성이 없는 데이터 블록을 찾기 위한 복구 과정에서 활용할 수 있고 그 정보들의 사본만 비교해보면 된다.
- Expensive solution ➜ 모든 디스크 블록(block)을 두 개씩 일일히 비교해보는 방법
- 만약 두 개의 비일관적인 블록의 사본 중 에러가 감지된 것이 있다면 다른 사본을 그것에 덮어씌우기만 하면 되고, 둘 다 에러는 없지만 다르다면 첫 번째(first) 블록을 두 번째(second) 블록에 덮어씌워주면 된다.
- 일관성이 없는(inconsistent) 블럭들을 먼저 찾아야 한다.
- 하지만, 데이터 전송 중 오류가 발생하면 여전히 일관성이 없는 사본들이 생겨날 수 있다.
➜ 블록(Block) 전송의 경우.
- Successful completion
- Partial failure
➜ 목적지(destination)의 데이터 블록이 부분적으로 일치하지 않은 경우. - Total failure
➜ 목적지(destination)의 데이터 블록이 아에 업데이트 되지 않은 경우.
- Successful completion
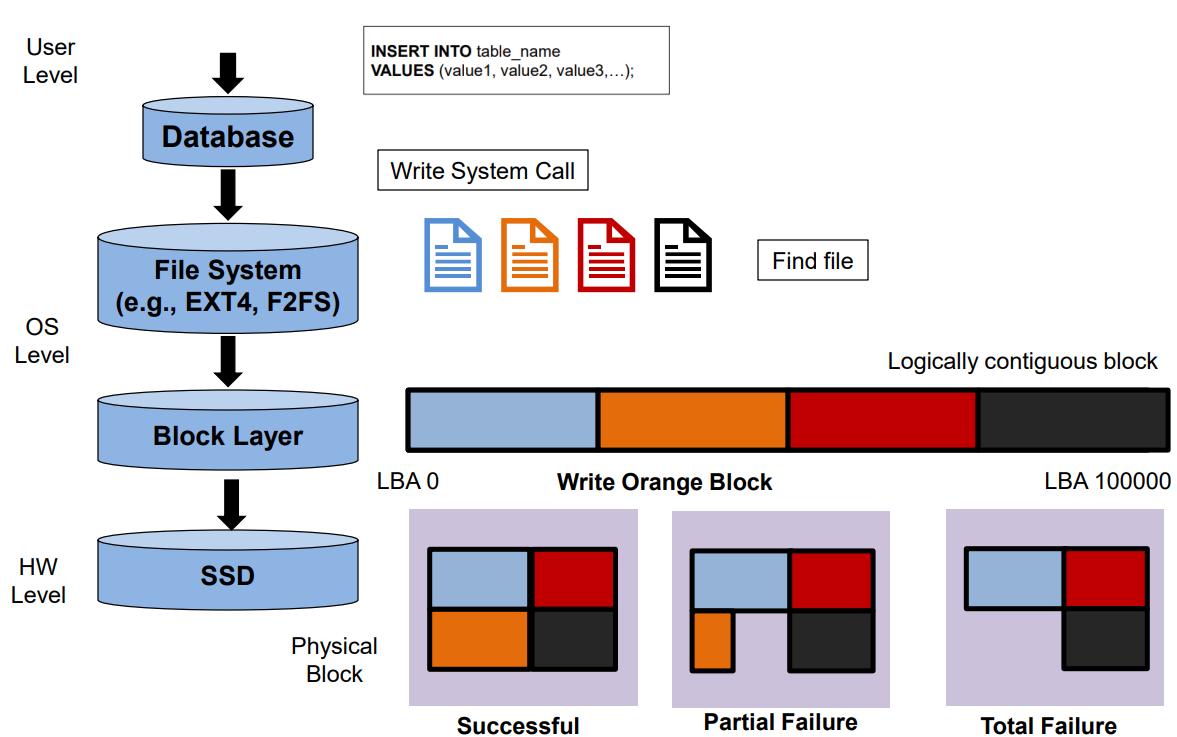
- 데이터 전송 중 발생하는 오류로부터 저장 매체의 데이터 손실을 방지하기 위한 방법
➜ 각 데이터 블럭마다 두 개의 사본이 있다고 가정 !
- 첫 번째 physical block에 정보를 저장한다.
- 첫 번째 physical block 저장에 성공하면, 같은 정보를 두 번째 physical block에도 저장해준다.
- 두 번째 physical block 저장까지 성공하게 되면 출력(output)이 완료된다.
Recovery Algorithms
- Recovery Algorithm이 반드시 갖추어야 하는 부분
- 정상적인(Normal) 트랜잭션이 수행될 때는 고장 복구에 필요한 정보들을 수집해야 한다 !
- 고장(오류)이 발생하면 데이터베이스를 복구하여 원자성(Atomicity), 일관성(Consistency), 그리고 지속성(Durability)를 보장해줘야 한다.
- 정상적인(Normal) 트랜잭션이 수행될 때는 고장 복구에 필요한 정보들을 수집해야 한다 !
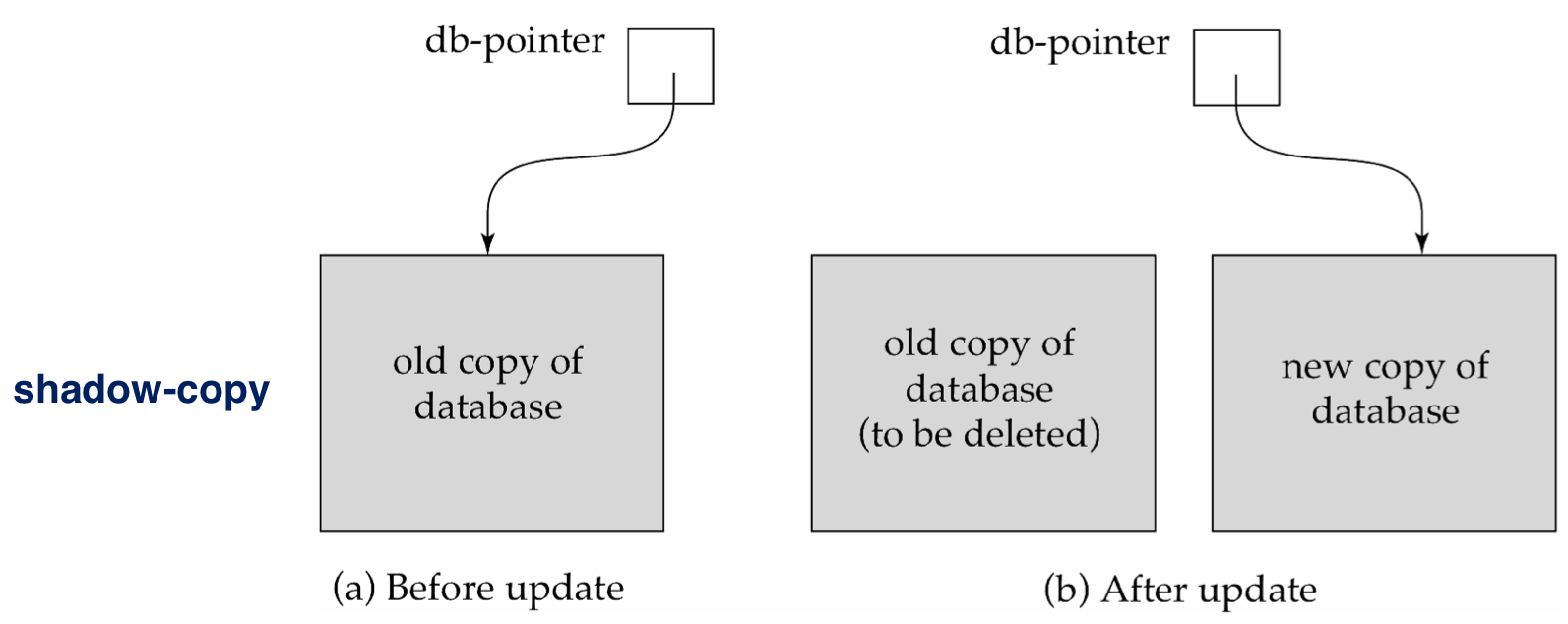
Shadow-paging (aka. Double Write) - 많이 사용 X
- Shadow-copy scheme
➜ 현 페이지 테이블(old copy)와 그림자 페이지 테이블(new copy)를 유지하면서, 트랜젝선을 실행하는 과정에서 old page만 사용하고 변경된다.
➜ new copy는 업데이트 되지 않고 트랜잭션 실행 직전 상태를 유지한다 !
➜ 트랜잭션이 'committed' 상태가 되면 old copy를 new copy로 대체시키고(성공 시), 시스템이 붕괴되거나 트랜잭션이 'aborted' 상태가 되는 경우엔 new copy를 이용해 트랜잭션 직전 상태로 복구시킨다(실패 시).
Log-Based Recovery 기법
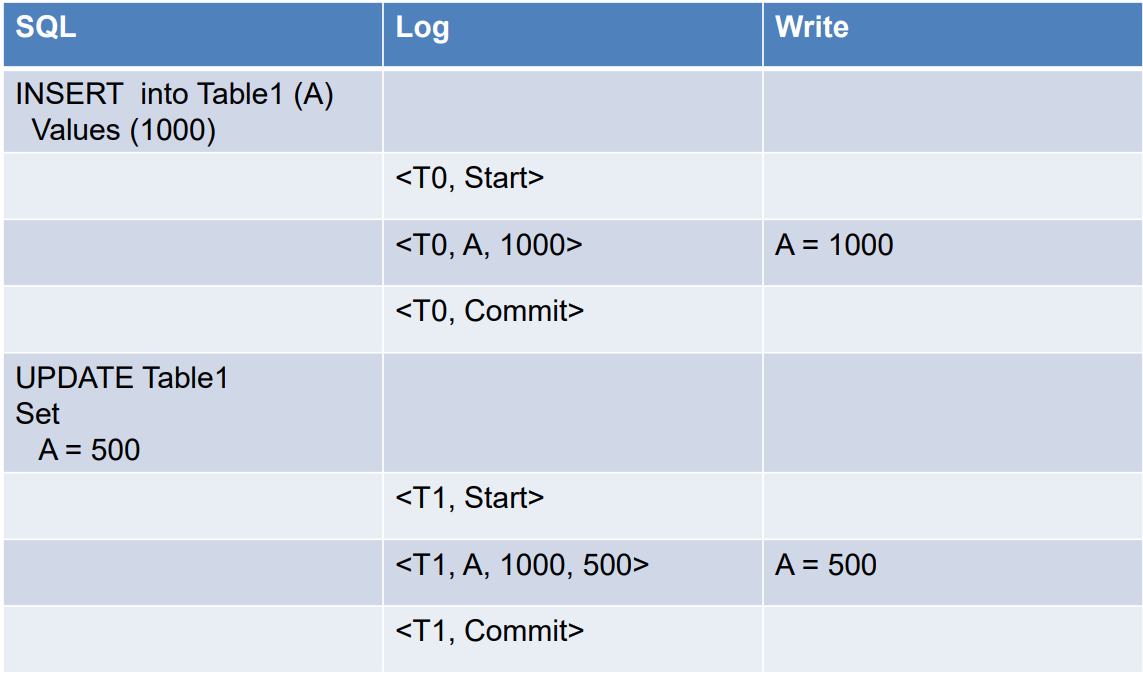
- Log ?
➜ 데이터베이스에 업데이트된 모든 내용을 기록해놓은 것이다.
➜ "Log" 는 stable storage에 있어야 한다. - Log record
- 트랜잭션 Ti이 시작되면, log <Ti, start>를 기록한다.
- 트랜잭션 Ti가 write(X)를 수행하기 전에, log <Ti, X, V1, V2>를 기록한다.
➜ V1 : old value / V2 : new value
( Ti가 X를 V1에서 V2로 바꿨다는 의미이다. ) - Ti가 last statement를 마치면, log <Ti, commit>이 기록된다.
- 트랜잭션 Ti이 시작되면, log <Ti, start>를 기록한다.
Undo & Redo of Transactions
- undo(Ti)
: 트랜잭션 Ti에 의해 업데이트된 모든 데이터 items의 값을 Ti에 대한 가장 최신 log부터 뒤로 돌아가면서 이전(기존) 값으로 복원한다.
( 트랜잭션의 작업을 무효화 ! )
➜ 일단, undo가 시작되면 log를 거꾸로 올라가면서 <T, X, V1, V2>라는 업데이트 log를 찾고 X의 값을 V1으로 덮어씌운다.
➜ 데이터 item X가 old value V로 복원될 때마다 "special log record <Ti, X, V>"가 작성된다.
➜ 트랜잭션의 undo가 완료되면 log <Ti abort>를 기록한다.
- 트랜잭션 시작 log인 <Ti start>가 있지만 <Ti commit>이나 <Ti abort>가 없다.
- 트랜잭션 시작 log인 <Ti start>가 있지만 <Ti commit>이나 <Ti abort>가 없다.
- redo(Ti)
: 트랜잭션 Ti의 첫 번째 log부터 Ti에 의해 업데이트된 모든 데이터 items의 값을 새로운 값으로 설정한다.
( 트랜잭션이 수행한 업데이트 작업을 첫 번째 log부터 순서대로 다시 한 번 수행하여 데이터를 최신화하는 작업 ! )
➜ 이 경우에는 logging이 수행되지 않는다.
( 추가적인 log를 남기지 X )
- 트랜잭션 시작 log인 <Ti start>가 있고 <Ti commit>이나 <Ti abort>가 남아있는 상태이다.
- undo(T0)
➜ T0가 완료되지 못한 채 고장(오류)이 발생했기 때문에 B는 2000으로, A는 1000으로 복원되고(undo), <T0, B, 2000>, <T0, A, 1000>, <T0, abort>라는 log를 추가로 남긴다.

- redo(T0) and undo(T1)
➜ 고장이 발생하기 전에 T0는 commit 되었기 때문에 A와 B는 각 950과 2050으로 저장되고(redo), T1은 완료되지 못한 채로 고장이 발생하여 C는 700으로 복원된다(undo). 그리고 <T1, C, 700>, <T1, abort>라는 log를 추가로 남긴다.

- redo(T0) and redo(T1)
➜ 고장이 발생하기 이전에 모두 커밋되었기 때문에 추가적인 log를 남기지 않고 redo를 수행한다.

Checkpoints 기법 (undo/redo 사용)
- log가 많이 축적된 상황에서 고장이 발생했을 때 log에 기록된 모든 트랜잭션을 Redoing/Undoing하는 것은 시간이 매우 많이 소모된다.
➜ 만약 시스템이 오랫동안 작동한다면, 전체 로그를 탐색하는 것은 시간 소모적(time-consuming)이다.
➜ 데이터베이스에 이미 반영한 것을 불필요하게 redo 트랜잭션을 수행할 수 있다. - 주기적으로 checkpoint를 두면 고장 발생시 복구의 범위를 제한할 수 있다 !
➜ Checkpointing 과정
- 메인 메모리에 있는 모든 log record를 stable storage로 output한다.
- 모든 수정된 buffer block들을 디스크로 출력(output) 한다.
- <checkpoint L>라는 log record를 stable storage에 작성한다.
( 여기서 L은 checkpoint 시간에 active되어 있는 트랜잭션의 list를 의미한다. ) - checkpointing을 하는 동안 모든 업데이트는 중단된다.
- 메인 메모리에 있는 모든 log record를 stable storage로 output한다.
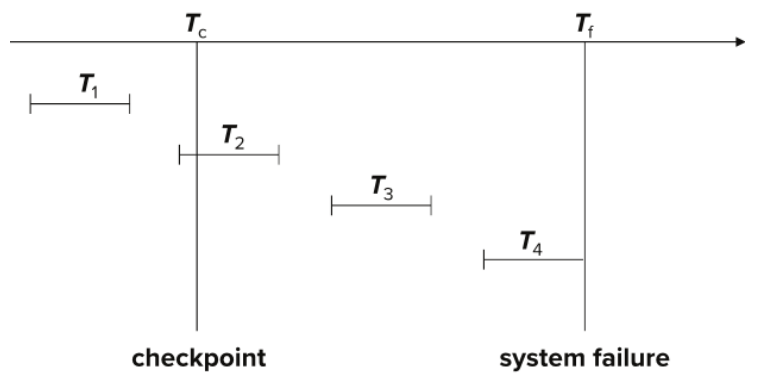
- T1 : checkpoint 이전에 이미 완료되었으므로 디스크에 업데이트 사항이 반영되었으므로 recovery 대상 X.
T2 : checkpoint 시점에 진행 중이기 때문에 recovery 대상에 포함되고, T2에 대한 완료 log가 있으므로 checkpoint 이후의 작업만 redo를 수행한다.
T3 : T3의 시작 log를 확인하여 recovery 대상에 포함하고, T3의 완료 log도 확인되므로 redo를 수행한다.
T4 : T4의 시작 log를 확인하여 recovery 대상에 포함하는데 고장 시점(system failure)에도 완료되지 못하고 recovery 대상에 남아 있으므로 undo를 수행한다.