
▼ Why ? What ?
HTTP는 서버와 클라이언트가 데이터를 주고 받기 위한 프로토콜(protocol)이기 때문에, 웹이 동작하는 과정을 이해하려면 웹 개발을 하기 위해서 알아야 하는 가장 중요한 개념들 중 하나이다. 그래서 이번 웹 개발 프로젝트를 진행하기 위해선 HTTP에 대해 이해하는 것이 시급하다고 생각하여 HTTP와 HTTPS에 대해 공부하게 되었다.
▼ 웹의 동작 원리
웹이 어떻게 동작하는가 ?

- 웹 브라우저를 통해 찾고자 하는 웹 페이지의 URL 주소를 입력하고, 원하는 데이터를 받는다
- 우리가 URL 주소를 입력하면, 사용자가 입력한 URL 주소 중에 Domain Name 부분을 DNS(Domain Name Server)에서 검사한다
[ IP 주소를 기억하기 쉽게 표현한 것 ➜ Domain Name (google.com, naver.com, etc) ] - DNS에서 해당 Domain 주소에 해당하는 IP 주소를 찾았으면, IP 주소와 사용자가 입력한 URL 정보를 함께 전달한다
- 이때 HTTP 프로토콜을 사용하여 HTTP Request 메시지를 생성한다
- 이렇게 생성된 HTTP Request 메시지는 TCP 프로토콜을 사용해 인터넷을 거쳐 해당 IP 주소의 컴퓨터로 이동한다
- 이렇게 도착한 HTTP Request 메시지는 HTTP 프로토콜을 사용해 다시 웹 페이지 URL 정보로 변환된다
- 웹 서버는 도착한 웹 페이지 URL 정보에 해당하는 데이터를 검색
- 이렇게 검색된 웹 페이지 데이터는 또다시 HTTP 프로토콜을 사용해 HTTP Response 메시지를 생성한다
- 이렇게 생성된 HTTP Response 메시지는 TCP 프로토콜을 사용해 인터넷을 거쳐 원래의 컴퓨터로 다시 전송된다
- 도착한 HTTP Response 메시지는 HTTP 프로토콜을 사용해 웹 페이지 데이터로 변환되고, 변환된 웹 페이지 데이터는 웹 브라우저에 의해 출력되어 우리가 볼 수 있게 되는 것이다
- 우리가 URL 주소를 입력하면, 사용자가 입력한 URL 주소 중에 Domain Name 부분을 DNS(Domain Name Server)에서 검사한다

URL

- Uniform Resource Locator
➜ 웹(web) 상에서 자원(Resource)들의 위치 - 특정 웹 서버의 특정 파일에 접근하기 위한 경로(주소)
- Domain(IP 주소) ➜ 웹 서버의 위치
- Port ➜ 웹 서버에서 자원에 접근하기 위해 사용하는 게이트 번호 (웹 브라우저에서 자동 처리)
(기본 Port 값) http ➜ 80 / https ➜ 443
▼ HTTP (Hyper-Text Transfer Protocol)
HTTP ?
- Server/Client 모델을 따르는 인터넷 상에서 데이터를 주고받기 위한 Protocol을 의미 !
➜ HTML 문서, 이미지, 동영상, 텍스트 등 어떤 종류의 데이터도 전송할 수 있도록 설계되어 있다 - (Request) 클라이언트 ➜ 서버
(Response) 서버 ➜ 클라이언트
HTTPS (Hypertext Transfer Protocol Secure) ?
- 하이퍼 텍스트 전송 프로토콜 보안으로 표준 HTTP와 동일한 방식으로 작동한다
- 서버와 주고받는 데이터가 암호화되기 때문에 웹사이트에 추가적인 보호를 제공한다
➜ 개인 데이터를 훔치거나, 해킹하거나 볼 수 없도록 작동 !
무상태(Stateless) 프로토콜
- 서버가 클라이언트의 상태를 보존 X
➜ 매 요청(Request)에 대해 첫 응답(Response)인 것처럼 작동 - 쿠키(Cookie), 세션(Session), 토큰(Token) 같은 기능이 구현되지 않은 사이트에 로그인 했을 때, 예를 들어 메일 서비스로 이동했을 때 로그인 상태가 유지되지 않아 로그인을 재요청할 것이다
➜ 요청할 때마다 이전에 보냈던 데이터를 함께 보내줘야 하는 단점 때문에 쿠키나 세션, 토큰 같은 기능들이 생겨난 것이다 - 장점
➜ 스케일 아웃(scale-out)에 유리
[ Scale-out : 서버를 수평적으로 늘려 서버의 부하를 줄이는 방법 ( + 로드 밸런싱(load balancing) ) ]
➜ 클라이언트의 상태를 보존하지 않기 때문에 어떤 서버에서도 클라이언트의 요청을 동일하게 처리하기 때문이다 !
비연결성
- HTTP 통신은 요청이 있을 때만 연결을 유지하고, 이후 데이터를 전송하면 연결을 종료한다
- 데이터 전송이 필요한 때만 연결이 유지되기 때문에, 불특정 다수를 대상으로 하는 서비스에 적합하다
➜ 실제 사용자가 수천명이라도 서버에서 동시에 처리하는 요청 수는 수십개 이하로 작아지기 때문에 !
➜ 서버의 자원을 효율적으로 사용 가능 - 비연결성의 단점 극복
- Persistent connection
➜ 한 번의 연결로 여러 데이터를 보낼 수 있게 됐다 - Pipelining
➜ 요청을 연속적으로 보내서 순차적으로 받아 데이터 요청/응답에 대한 지연시간이 감소했다
- Persistent connection

▼ HTTP 메시지 구조

요청(Request) 데이터 포맷 (구조)

헤더 부분 (Header)
- START-LINE (첫줄)
- Request(요청)인지 Response(응답)인지에 따라 다른 정보를 포함하게 된다
➜ 요청 메서드, 요청 URL, HTTP 프로토콜의 버전

method (공백 - SP) request-target (공백 - SP) HTTP-version (엔터 - CRLF)
- 요청 메서드 (Request Method)
- GET : 리소스를 조회할 때 주로 사용.
- POST : 요청 데이터 처리, 주로 등록에 사용
- PUT : 리소스를 대체 할 때 주로 사용, 해당 리소스가 없으면 생성함.
- PATCH : 리소스 부분을 일부 변경해야할 때 주로 사용.
- DELETE : 리소스 삭제
- HEAD : (HTTP)헤더 정보만 요청한다. 해당 자원이 존재하는지 혹은 서버에 문제가 없는 지를 확인하기 위해서 사용한다.
- OPTIONS : 웹서버가 지웒나느 메서드의 종류를 요청한다.
- TRACE : 클라이언트의 요청을 그대로 반환한다. 예컨데 echo서비스로 서버상태를 확인한기 위한 목적으로 주로 사용한다.
➜ 주의할 점
: HTTP 메서드에 따라 서버에서 동작을 지정해줘야 한다! 메서드에 따른 동작은 모두 서버에서 구현해주어야하는 부분이다
( GET 메서드로 요청했다고 해서 무조건 데이터를 조회하는 것이 아니고, DELETE 메서드로 요청했다고 해서 무조건 해당 데이터를 삭제하는 것 X )
- 요청 URL : 요청하는 리소스(자원)의 위치를 명시
➜ request-target
: /member?name=John 이 이에 해당하는 부분이며, /member라는 리소스에 name=John이라는 파라미터를 지정하여 데이터를 보내는 것이다. 서버에서는 "/member"으로 왔을때 처리하는 로직들을 실행한다. 요청 객체(HttpRequest)에서 request.getParameter("name")을 하여 John이라는 값을 가져올 수 있다. - HTTP 프로토콜의 버전 : 웹 브라우저가 사용하는 http 프로토콜의 버전
- 나머지 헤더 부분은 여러 줄의 헤더 정보. 각각의 줄은 헤더명과 헤더 값이 콜론으로 구분
Empty Line
- 헤더(Header)와 바디(Message Body)를 구분하기 위한 것으로, 헤더와 바디 사이의 한 줄의 공백을 말한다
요청 바디 (Request Body; Message Body)
- 요청을 할 때 함께 보낼 데이터가 담길 부분이다
- 요청 메서드(Request Method)가 POST나 PUT을 사용하게 됐을 때 필요 !
( GET 메서드 방식은 요청을 할 때 함께 보내야 하는 리소스도 URL에 붙여주기 때문에 요청 바디가 필요 X )
응답(Response) 데이터 포맷

헤더 부분 (Header)
- START-LINE (첫 줄) ➜ 응답 HTTP 프로토콜의 버전, 상태 코드(status-code), 응답 메시지
( 성공했다는 응답 코드는 200 )
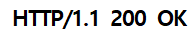
HTTP-version (공백 - SP) status-code (공백 - SP) reason-pharse (엔터 - CRLF)
- status-code : HTTP 요청에 대한 서버의 응답 상태
➜ 웹 서핑을 하다 보면 많이 볼 수 있는 404 에러 페이지가 이에 해당한다- 2xx : 성공
- 4xx : 클라이언트 요청 오류
- 5xx : 서버 내부 오류
- reason-phrase : 사람이 이해할 수 있는 짧은 상태 코드 설명 글
- 나머지 헤더 부분엔 날짜, 웹서버 이름과 버전, 콘텐츠 타입, 캐시 제어 방식, 콘텐츠 길이 등의 값이 들어간다
응답 바디 (Response Body)
- 실제 응답 리소스 데이터가 담긴 부분으로, HTML 문서나 이미지, 영상, 음성, JSON 등등 byte로 표현할 수 있는 모든 데이터를 전송 가능하다
( 응답 메시지에 HTML이 담겨 있는데 이 HTML을 받아 브라우저가 화면에 렌더링해준다 )