
-
🌑 람다식 (Lamda expression)
-
✔️ 람다식 ?
-
✔️ 함수형 인터페이스 (Functional Interface)
-
✔️ 람다식의 타입과 형변환
-
✔️ 외부 변수를 참조하는 람다식
-
✔️ java.util.function package
-
✔️ 람다식 합성
-
✔️ 람다식을 더 간결하게 표현하는 방법
-
🌒 스트림 (Stream)
-
✔️ 스트림 (Stream) ?
-
✔️ 스트림(Stream)의 연산 ?
-
✔️ 스트림 생성
-
✔️ 스트림(Stream)의 중간 연산
-
✔️ Optional<T> & OptionalInt
-
✔️ 스트림의 최종 연산
-
✔️ collect()
-
✔️ 그룹화와 분할 - groupingBy(), partitioningBy()
-
✔️ Collector 구현
-
🌓 스트림(Stream)의 변환
-
✔️ 스트림(Stream) 간의 변환
-
▼ Study📋
🌑 람다식 (Lamda expression)
✔️ 람다식 ?
🔹 람다식(Lamda expression) : 메서드를 하나의 '식(expression)'으로 표현한 것
- class, 메서드, 객체 필요 X
➜ 람다식 자체만으로 메서드의 역할을 수행
➜ 즉, 메서드라는 개념보다 '익명 함수(function; 특정 class에 속하지 X)'라고 하는 것이 적절하다 - 쉽게 말하면 메서드를 변수처럼 다룰 수 있게 된다 (반환값, 매개변수)
- 메서드를 변수처럼 다루는 것이 어떻게 가능한가?
(아래 "함수형 인터페이스 - @FunctionalInterface" 관련 내용 참고)
람다식을 참조변수로 다룬다는 것
➜ 메서드를 통해 람다식을 주고받을 수 있다는 의미, 즉 메서드를 변수처럼 주고받는 것이 가능
➜ 사실은 메서드가 아니라 객체(익명 객체 ➟ 람다식)를 주고받는 것이긴 하다
- 메서드를 변수처럼 다루는 것이 어떻게 가능한가?
🔹 람다식 작성은 어떻게 할까 ?
- '익명 함수'답게 메서드 이름과 반환타입 제거
( 반환타입은 추론 가능하기 때문에 제거하는 것 ) - 매개변수 선언부와 몸체{} 사이에 ' -> ' 추가
- 람다식에서 식(expression)의 결과 자체가 반환값일 경우엔, return문을 '식'으로 대신
- '문장(statement)'이 아닌 '식'이므로 끝에 ' ; '을 붙이지 않는다
ex)int max(int a, int b) -> {
returna > b ? a : b;
} - 매개변수의 타입도 추론 가능한 경우엔 생략 가능 ➜ 대부분의 람다식에서 생략
- (1)매개변수가 하나뿐이고 (2)매개변수의 타입이 생략된 경우엔 괄호()도 생략 가능
( () ➜ 매개변수가 없는 경우엔 생략 X ) - (1)몸체{}안의 문장이 하나이고 (2)return문이 아니면 중괄호{}도 생략 가능
// (int a, int b) -> a > b ? a : b
(a, b) -> a > b ? a : b
// int square(int x) { return x * x; }
x -> x * x; // OK
int x -> x * x // Error
✔️ 함수형 인터페이스 (Functional Interface)
🔹 함수형 인터페이스가 왜 필요할까 ?
- 결론부터 말하면, 함수형 인터페이스가 필요한 이유는 람다식을 다루기 위해서이다
- 일단, 람다식은 메서드와 동등한 것이 아닌, 익명 클래스(Anonymous class)의 객체와 동등하다
- 익명 클래스의 객체(람다식)의 메서드 호출 방법
1. 일반적인 객체의 메서드를 호출할 때처럼 참조변수가 필요하다
➜ 즉, 메서드를 호출할 익명 객체를 생성해야 한다
(참조변수의 타입) f = (int a, int b) -> a > b ? a : b;
2. 참조변수의 타입은 ?
➜ 람다식과 동등한 메서드가 정의되어 있는 class나 interface !
interface MyFunction {
// 람다식과 동등한 max() 메서드
public abstract int max(int a, int b);
}
3. 해당 interface를 구현한 익명 클래스의 객체를 생성하고, 익명 객체의 메서드를 호출
MyFunction f = new MyFunction() { // 익명 객체
public int max(int a, int b) {
return a > b ? a : b;
}
};
int bigNum = f.max(5, 3); // 익명 객체의 메서드를 호출𐰸 𐰸
MyFunction f = (int a, int b) -> a > b ? a : b; // 익명 객체를 람다식으로 대체
int big = f.max(5, 3); // 익명 객체의 메서드를 호출
🔻 그렇다면, 람다식으로 익명 객체를 어떻게 대체하는 것일까?
➜ 람다식도 사실 익명 객체이며, 익명 객체의 메서드, 매개변수의 타입과 개수, 반환값이 일치하기 때문이다
- 따라서, 람다식을 interface를 통해 다루기로 결정
➜ 람다식을 다루기 위한 interface를 '함수형 인터페이스 (functional interface)'라 한다 !
🔹 함수형 인터페이스 - @FunctionalInterface
- 함수형 인터페이스에는 하나의 추상 메서드만 정의되어 있어야 한다
( 람다식과 추상 메서드의 1:1 연결을 위해 )
단, static 메서드와 default 메서드의 개수에는 제약 X - 람다식을 이용하면 interface의 메서드를 아래와 같이 간단히 구현 가능
( Comparator interface엔 추상 메서드가 ' compare() ' 메서드 하나만 정의되어 있다 )
List<String> list = Arrays.asList("abc", "aaa", "bbb", "ddd", "aaa");
Collections.sort(list, new Comparator<String>() { // 매개변수로 전달할 익명 객체를 생성하고
// 익명 클래스로 Comparator interface의 추상 메서드 구현
public int compare(String s1, String s2) {
retrun s2.compartTo(s1);
}
);𐰸 𐰸 ( 간단히 구현 )
List<String> list = Arrays.asList("abc", "aaa", "bbb", "ddd", "aaa");
/*
Comparator f = new Comparator<String>() {
public int compare(String s1, String s2) {
retrun s2.compartTo(s1);
}
}
*/
// 위처럼 생성한 익명 객체를 람다식으로 대체하고, 람다식을 참조변수로 다룬다
// Compartor f = (s1, s2) -> s2.compareTo(s1);
// Collecitons.sort(list, f);
// 위의 두 줄의 코드를 한 줄로 줄인 코드
Collections.sort(list, (s1, s2) -> s2.compareTo(s1));
🔻 결국 람다식을 참조변수로 다룬다는 것
➜ 메서드를 통해 람다식을 주고받을 수 있다는 의미, 즉 메서드를 변수처럼 주고받는 것이 가능
➜ 사실은 메서드가 아니라 객체(익명 객체 ➟ 람다식)를 주고받는 것이긴 하다
🔹 함수형 인터페이스 타입의 매개변수와 반환타입
- 아래와 같은 함수형 인터페이스 MyFunction이 있다
@FunctionalInterface
interface MyFunction {
void myMethod();
}
- 어떠한 메서드의 매개변수가 함수형 인터페이스인 MyFunction 타입이다?
➜ 해당 메서드(' aMethod ')의 매개변수는 람다식을 참조하는 참조변수로 지정해야 한다는 의미 !
void aMethod(MyFunction f) {
f.myMethod();
}
// aMethod 메서드 호출
MyFunction f = () -> System.out.println("myMethod()");
aMethod(f);
🔻 참조변수 없이 아래처럼 직접 람다식을 매개변수로 지정하는 것도 가능
aMethod(() -> System.out.println("myMethod()"));
- 메서드의 반환타입이 함수형 인터페이스 타입인 경우
➜ 해당 함수형 인터페이스의 추상 메서드와 동등한 (1)람다식을 가리키는 참조변수를 반환 or (2)람다식을 직접 반환
MyFunction myMethod() {
// (1)
MyFunction f = () -> {};
return f;
// (2)
// return () - {};
}
✔️ 람다식의 타입과 형변환
🔹 람다식의 타입 ≠ 함수형 인터페이스의 타입
- 함수형 인터페이스 타입의 참조변수로 람다식을 참조할 수 있는 것일 뿐, 타입이 같다는 착각 X
( 람다식은 익명 객체이지만, 사실 익명 객체도 타입이 있긴 하다. 컴파일러가 임의로 정해 알 수 없는 것일 뿐 )
➜ 아래처럼 형변환이 필요한 이유
// 'interface MyFunction { void method(); }'가 정의되었다고 가정
MyFunction f = (MyFunction) (() -> {}); // 형변환 생략 가능
- 람다식은 오직 함수형 인터페이스로만 형변환 가능
➜ 람다식도 객체이지만, Object class 타입으로는 형변환 불가능
➜ 굳이 하고 싶다면? 아래처럼 함수형 인터페이스 타입으로 먼저 형변환을 해줘야 한다
Object obj = (Object)(MyFunction)(() -> {});
String str = ((Object)(MyFunction)(() -> {})).toString();
✔️ 외부 변수를 참조하는 람다식
🔹 람다식도 익명 객체처럼 외부 변수에 접근 가능
- 람다식도 익명객체, 즉 익명 클래스의 instance이므로 익명 클래스에서의 규칙과 동일한 규칙에 따라 외부에 선언된 변수에 접근 가능하다
- 람다식 내에서 참조하는 지역변수(메서드 영역)는 ' final ' 이 붙지 않아도 상수로 간주한다
- 하지만, instance 변수는 람다식 내에서 참조하고 있어도 변경을 허용한다
@FunctionalInterface
interface MyFunction {
void myMethod();
}
class Outer {
int val = 10; // Outer.this.val
class Inner {
int val = 20; // this.val
void method(int i) { // void method(final int i) {
int val = 30; // final int val = 30;
// i = 10; // Error.. 상수이기 때문에 변경 X
MyFunction f = () -> {
System.out.println(i);
System.out.println(val);
System.out.println(++this.val); // 변경 OK
System.out.println(++Outer.this.val); // 변경 OK
};
f.myMethod();
}
}
}
- 지역변수와 같은 이름의 람다식 매개변수는 허용 X
MyFunction f = (i) -> { // Error
✔️ java.util.function package
🔹 java.util.function package에 미리 정의되어 있는 함수형 인터페이스 ?
- 대부분의 메서드는 타입이 비슷하기 때문에 미리 정의하여 사용해도 문제 X
- 매번 새로운 함수형 인터페이스를 정의 X
➜ 이 패키지에 정의되어 있는 함수형 인터페이스를 활용하자
( 메서드 이름 통일, 재사용성과 유지보수성 증가 )
🔹 자주 쓰이는 가장 기본적인 함수형 인터페이스
java.lang.Runnable
- void run()
Supplier<T>
- T get()
Consumer<T>
- void accept(T t)
Function<T, R>
- 일반적인 함수
- R apply(T t)
Predicate<T>
- 조건식을 람다식으로 표현하는데 사용
- boolean test(T t)
- Predicate는 Function의 변형으로, 반환타입이 boolean이라는 것만 다르다
Predicate<String> isEmptyStr = s -> s.length() == 0;
String s = "";
if(isEmptyStrt.test(s))
System.out.println("This is an empty String.");
- 사용 예제 코드
public static void main(String[] args) {
Function<Integer, Integer> f = i -> i/10*10; // i의 일의 자리 제거
List<Integer> list = new ArrayList>();
// list에 값을 넣어주는 코드 생략
List<Intger> newList = doSomething(f, list);
System.out.println(newList);
}
static <T> List<T> doSomething(Function<T, T> f, List<T> list) {
List<T> newList = new ArrayList<T>(list.size());
for(T i : list) {
newList.add(f.apply(i));
}
return newList;
}
🔹 매개변수가 두 개인 함수형 인터페이스 - 접두사 'Bi'가 붙는다
BiConsumer<T, U>
- void accept(T t, U u)
BiPredicate<T, U>
- boolean test(T t, U u)
BiFunction<T, U, R>
- R apply(T t, U u)
- 이 이상의 매개변수를 갖는 함수형 인터페이스가 필요하다면 직접 만들어야 한다
🔹 UnaryOperator & BinaryOperator (Function의 또다른 변형)
UnaryOperator<T>
- Function의 자손 interface
- T apply(T t)
BinaryOperator <T>
- BiFunction의 자손 interface
- T apply(T t, T t)
🔹 컬렉션 프레임워크 & 함수형 인터페이스
Collection
- 조건에 맞는 요소를 삭제
- void replaceAll(Predicate<E> filter)
List
- 모든 요소를 변환하여 대체
- void replaceAll(UnaryOperator<E> operator)
Iterable
- 모든 요소에 작업 action을 수행
- void forEach(Consumer<T> action)
Map
- V compute(K key, BiFunction<K, V, V> f) ➜ 지정된 키의 값에 작업 f 수행
- V computIfAbsent(K key, Function<K, V> f) ➜ 키가 없으면 작업 f 수행 후 추가
- V computeIfPresent(K key, BiFunction<K, V, V> f) ➜ 지정된 키가 있을 때, 작업 f 수행
- V merge(K key, V value, BiFunction<V, V, V> f) ➜ 모든 요소에 병합작업 f 수행
- void forEach(BiConsumer<K, V> action) ➜ 모든 요소에 작업 action 수행
- void replaceAll(BiFunction<K, V, V> f) ➜ 모든 요소에 치환작업 f 수행
- 사용 예제 코드
// map의 모든 요소를 {k, v}의 형식으로 출력
map.forEach((k, v) -> System.out.print("{" + k + ", " + v + "}"));
🔹 기본형을 사용하는 함수형 인터페이스
DoubleToIntFunction
- AToBFunction ➜ 입력이 A타입, 출력이 B타입
- int applyAsInt(double d)
ToIntFunction<T>
- ToBFuntion ➜ 입력은 지네릭 타입, 출력이 B타입
- int applyAsInt(T value)
IntFunction<R>
- AFunction ➜ 입력은 A타입, 출력은 지네릭 타입
- R apply(T t, U u)
ObjIntConsumer<T>
- ObjAFUnction ➜ 입력은 T, A타입이고, 출력은 없다
- void accept(T t, U u)
- 사용 코드 예제
public static void main(String[] args) {
IntUnaryOperator op = i -> i/10*10; // i의 일의 자리 제거
int[] arr = new int[10];
// arr에 값을 넣어주는 코드 생략
int[] newArr = doSomething(op, arr);
System.out.println(newArr);
}
static int[] doSomething(IntUnaryOperator op, int[] arr) {
int[] newArr = new int[arr.length];
for(int i = 0; i < newArr.length; i++) {
newList[i] = op.applyAsInt(arr[i]); // apply()가 아님에 주의
}
return newArr;
}
🔻 아래처럼 IntUnaryOperator가 아닌 Function을 사용할 경우 에러 발생
Function f = (i) -> i/10*10;𐰸 𐰸 ( 매개변수 i와 반환타입을 지정해주면 OK )
// 매개변수 타입은 Integer, 반환타입은 Integer
Function<Integer, Integer> f = (i) -> i/10*10;
// 매개변수 타입은 int, 반환타입은 Integer
// IntFunction<Integer> f = (i) -> i/10*10;
🔻근데 왜 IntToIntFuction(AToBFunction ➜ 입력은 A타입, 출력은 B타입)은 없을까?
➜ UnaryOperator가 그 역할을 하기 때문이다 !
➜ 매개변수의 타입과 반환타입이 일치할 때는 "사용 코드 예제"처럼 Function 대신 UnaryOperator를 사용하는 것이 좋다
✔️ 람다식 합성
🔹 람다식 합성 ?
- 수학에서 두 함수를 합성해서 하나의 새로운 함수를 만들어내듯이,
두 람다식을 합성해서 새로운 람다식을 만들 수 있다 - Function의 합성과 Predicate의 결합을 통해 람다식의 합성에 대해 알아보자
🔹 Function의 합성 & Predicate의 결합
- java.util.function 패키지의 함수형 인터페이스에는 추상메서드 외에도 default 메서드와 static 메서드가 정의되어 있다
( 함수형 인터페이스에선 defaut 메서드와 static 메서드의 개수엔 제약 X ) - 함수형 인터페이스의 메서드들은 대부분 유사하기 때문에, Function과 Predicate interface에 정의된 메서드만 살펴봐도 응용 가능하다
🔹 Function의 합성
- Function interface에 정의되어 있는 메서드 (default, static)
- default <V> Function<T, V> andThen(Function<? super R, ? extends V> after)
- default <V> Function<V, R> compose(Function<? super V, ? extends T> before)
- static <T> Function<T, T> identity()
( Function interface는 반드시 두 개의 타입을 지정해줘야 해서 타입이 같아도 Function<T>가 아닌 Function<T, T> 라 써야 한다 )
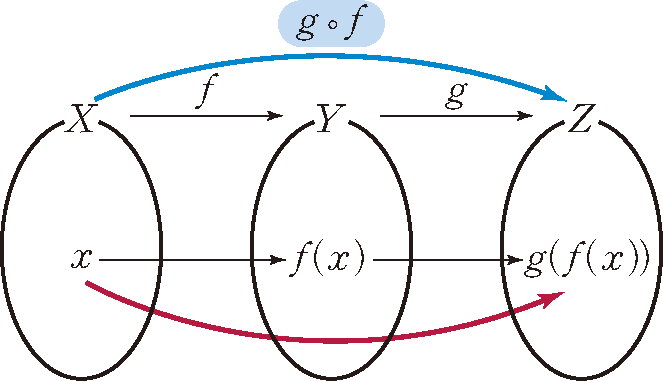
- 두 Function의 합성은 어느 함수를 먼저 적용하느냐에 따라 달라진다
함수 f, g가 있을 때,
- f.andThen(g) ➜ 함수 f를 먼저 적용한 다음, 함수 g를 적용
- f.compose(g) ➜ 반대로 적용
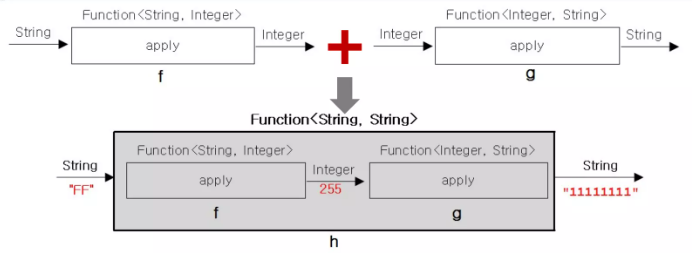
andThen()
- default <V> Function<T, V> andThen(Function<? super R, ? extends V> after)
Function<String, Integer> f = (s) -> Integer.parseInt(s, 16); // 함수 f : 문자열 ➜ 숫자
Function<Integer, String> g = (i) -> Integer.toBinaryString(i); // 함수 s : 숫자 ➜ 문자열
Function<String, String> h = f.andThen(g);
System.out.println(h.apply("FF")); // "FF" -> 255 -> "1111111"
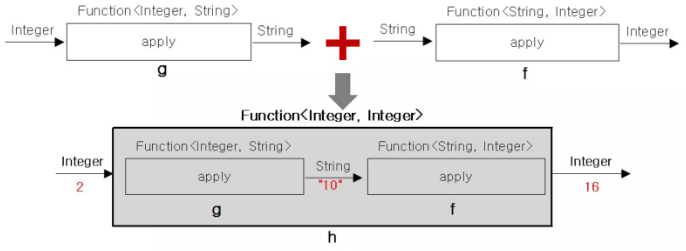
compose()
- default <V> Function<V, R> compose(Function<? super V, ? extends T> before)
Function<Integer, String> f = (i) -> Integer.toBinaryString(i); // 함수 f : 숫자 ➜ 문자열
Function<String, Integer> s = (s) -> Integer.parseInt(s, 16); // 함수 s : 문자열 ➜ 숫자
Function<String, String> h = f.compose(g);
System.outprintln(h.apply(2)); // 2 -> "10" -> 16
identity()
- static <T> Function<T, T> identity()
- 쉽게 말하면, 항등 함수( f(x) = x )이다
( map()으로 변환작업할 때처럼, 변함없이 그대로 처리하고자 할 때 사용 )
Function<String, String> f = x -> x;
// Function<String, String> f = Function.idenetity(); // 위와 동일
System.out.println(f.apply("AAA"));AAA
🔹 Predicate의 결합
- Predicate interface에 정의되어 있는 메서드 (static, default)
- default Predicate<T> and(Predicate<? super T> other)
- default Predicate<T> or(Predicate<? super T> other)
- default Predicate<T> negate()
(Predicate의 끝에 붙이면 조건식 전체가 부정이 된다) - static <T> Predicate<T> isEqual(Object targetRef)
- 여러 조건식을 논리연산자(&&, ||, !)으로 연결해서 하나의 식을 구성하는 것처럼,
' and() ', ' or() ', ' negate() '로 연결해서 하나의 새로운 Predicate로 결합
Predicate<Integer> p = i -> i < 100;
Predicate<Integer> q = i -> i < 200;
Predicate<Integer> r = i -> i i%2 == 0;
Predicate<Integer> notP = p.negate(); // i >= 100
Predicate<Integer> all = notP.and(q.or(r)); // 100 <= i && (i < 200 || i%2 == 0)
// 람다식을 직접 넣어도 된다
Predicate<Integer> all = notP.and(i -> i < 200).or(i -> i%2 == 0);
isEqual
- 두 대상을 비교하는 Predicate를 만들 때 사용
2개의 매개변수 (2개의 비교대상) ➜ (1) isEqual() (2) test()
// Predicate<String> p = Predicate.isEqual(str1);
// boolean result = p.test(str2); // str1과 str2가 같은지 비교하여 결과를 반환
boolean result = Predicate.isEqual(str1).test(str2)
✔️ 람다식을 더 간결하게 표현하는 방법
🔹 메서드 참조
- 람다식이 하나의 메서드만 호출하는 경우에 가능
- 람다식을 static 변수처럼 다룰 수 있게 해준다
1. static메서드 혹은 instance메서드를 참조하는 방법
➜ ' 클래스이름::메서드이름 ' or ' 참조변수::메서드이름 '
BiFunction<String, String, Boolean> f = (s1, s2) -> s1.equals(s2);
/* 이 람다식을 메서드로 표현하면
String isSame(St s) { // 메서드 이름은 의미 X
return s1.equals(s2);
}
*/𐰸 𐰸 ( isSame() 메서드는 사실 하는 일이 X ➜ 'String.equals()'를 직접 호출하자 )
BiFunction<String, String, Boolean> f = String::equals; // 메서드 참조🔻 생략된 부분은 컴파일러가 알아낼 수 있다
( (1)좌변의 Function interface에 지정된 지네릭 타입과 (2)parseInt 메서드의 선언부로부터 )
➜ (1)String 타입인 두 개의 매개변수를 받고, (2)Boolean 타입의 결과값을 반환하는구나
2. 특정 객체의 instance메서드 참조
- 이미 생성된 객체의 메서드를 람다식에서 사용하는 경우
➜ class 이름 대신 그 객체의 참조변수를 적어줘야 한다
MyClass obj = new MyClass();
Function<String, Boolean> f = (x) -> obj.equals(x); // 람다식
Function<String, Boolean> f2 = obj::equals; // 메서드 참조3. 생성자의 메서드 참조
- 생성자를 호출하는 람다식도 메서드 참조로 변환할 수 있다
Supplier<MyClass> s = () -> new MyClass(); // 람다식
Supplier<MyClass> s = MyClass::new; // 메서드 참조
- 매개변수가 있는 생성자라면?
➜ 생성자의 매개변수의 개수에 따라 알맞은 함수형 인터페이스를 써주거나, 알맞은 인터페이스가 없다면 새로운 함수형 인터페이스를 정의해줘야 한다
Function<Integer, MyClass> f = (i) -> new MyClass(i); // 람다식
Function<Integer, MyClass> f = MyClass::new; // 메서드 참조🔻 생성자의 매개변수가 1개이니까 그에 맞는 함수형 인터페이스인 Function을 사용
- 배열을 생성할 때엔?
Function<Integer, int[]> f = x -> new int[x]; // 람다식
Function<Integer, int[]> f2 = int[]::new; // 메서드 참조
🌒 스트림 (Stream)
✔️ 스트림 (Stream) ?
🔹 스트림 (Stream)
- 스트림(Stream)을 왜 만들었을까?
- 컬렉션이나 배열의 데이터를 for문과 Iterator로 다루는 것은 코드도 길어져 가독성이 떨어지며, 재사용성도 떨어진다
- 데이터 소스마다 다른 방식으로 다뤄야 한다
( ex. List를 정렬할 때는 ' Collections.sort() ' 를, 배열을 정렬할 때는 ' Arrays.sort() ' 를 사용해야 한다 )
- 다양한 데이터 소스(배열, 컬렉션, 파일, etc.)들을 모두 같은 방식으로 다룰 수 있다
➜ 배열과 List에 대한 Stream을 생성하고 같은 방식으로 정렬하는 과정
String[] array = {"a", "b", "c"};
List<String> list = Arrays.asList(arrays);
Stream<String> streamArray = Arrays.stream(array);
Stream<String> streamList = list.stream();
streamArray.sorted() // Arrays.sort(array)
streamList.sorted() // Collections.sort(list)
🔹 스트림의 특징
- 스트림은 데이터 소스를 변경하지 않는다
// 정렬된 결과를 List에 담아서 반환
List<String> sortedList = strList.sorted().collect(Collectors.toList());
- 스트림은 일회용이다
➜ Iterator처럼 스트림도 한 번 사용하면 닫혀서 사용할 수 없다
- 스트림은 작업을 내부 반복으로 처리한다
( 내부 반복이란, 반복문을 메서드 내부에 숨길 수 있다는 의미 )
/*
for(String str : strList)
System.out.println(str)
*/
stream.forEach(System.out::println);
✔️ 스트림(Stream)의 연산 ?
🔹 스트림 연산
- 스트림에 정의된 메서드 중에서 데이터 소스를 다루는 작업을 수행하는 것을 말한다
- 중간 연산
➜ 연산 결과(반환 값)이 스트림인 연산. 스트림에 연속해서 중간 연산할 수 있다 - 최종 연산
➜ 연산 결과(반환 값)이 스트림 X. 스트림의 요소를 소모하므로 단 한 번만 가능하다
- 중간 연산
- 스트림 연산 메서드
Stream (Java SE 20 & JDK 20) (oracle.com)
Stream (Java SE 20 & JDK 20)
Type Parameters: T - the type of the stream elements All Superinterfaces: AutoCloseable, BaseStream > A sequence of elements supporting sequential and parallel aggregate operations. The following example illustrates an aggregate operation using Stream and
docs.oracle.com
- 지연된 연산
➜ 스트림 연산에서 한 가지 중요한 점이 최종 연산이 수행되기 전까지는 중간 연산이 수행되지 않는다는 것, 즉 최종 연산이 수행되기 전까지 중간 연산은 지연된다는 것이다
( 중간 연산이 호출되는 것은 단지 어떤 작업을 수행해야지 지정해주는 것일 뿐 )
- 기본형을 다루는 스트림 (IntStream, LongStream, DoubleStream)
➜ 요소의 타입이 T인 스트림은 기본적으로 Stream<T>이지만, ' 오토박싱 & 언박싱 (Auto-boxing & Unboxing) ' 으로 인한 비효율을 줄이기 위해 데이터 소스의 요소를 기본형으로 다루는 스트림이 따로 제공된다
( ex. Stream<Integer> 대신 IntStream을 사용하는 것이 효율적 )
- 병렬 스트림
➜ 병렬 스트림은 내부적으로 fork&join Framework를 이용해 자동적으로 연산을 병렬로 수행하기 때문에 병렬 처리가 쉽다
int sum = strStream.parallel() // parallel() : strStream을 병렬 스트림으로 전환
.mapToInt(s -> s.length())
.sum();
// sequential() : parallel()을 호출한 것을 취소할 때만 사용 (병렬 작업 취소)
✔️ 스트림 생성
🔹 컬렉션 ➜ 스트림
- 컬렌션의 최고 조상인 Collection class에 ' stream() ' 이 이미 정의되어 있다
// 해당 컬렉션을 소스로 하는 스트림을 반환
Stream<T> Collection.stream()
- List로부터 스트림을 생성
List<Integer> list = Arrays.toList(1, 2, 3, 4, 5);
Stream<Integer> intStream = list.stream();
// forEach() 지정된 작업을 스트림의 모든 요소에 대해 수행
intStream.forEach(System.out::println);
intStream.forEach(System.out::println); // 최종 연산이기에 스트림이 이미 닫혀 Error 발생
🔹 배열 ➜ 스트림
- Stream과 Arrays class에 static 메서드로 정의되어 있다
Stream<T> Stream.of(T... values) // 가변 인자 (variable argument) : 매개 변수의 개수가 동적
Stream<T> Stream.of(T[])
Stream<T> Arrays.stream(T[])
Stream<T> Arrays.stream(T[] array, int startInclusive, int endExclusive)// 기본형 배열을 소스로 하는 스트림 생성 메서드
IntStream IntStream.of(int... value)
IntStream IntStream.of(int[])
IntStream Arrays.stream(int[])
IntStream Arrays.stream(int[] array, int startInclusive, int endExclusive)
- 문자열 배열 ➜ 스트림 / 기본형 배열 ➜ 스트림
// 문자열을 소스로 하는 스트림을 생성하는 바법
Stream<String> strStream = Stream.of("a", "b", "c"); // 가변 인자
// = Arrays.stream(new String[]){"a", "b", "c"});
// 기본형 배열(int[])을 소스로 하는 스트림을 생성하는 방법
IntStream intStream = IntStream.of(new int[]{1, 2, 3});
// = Arrays.stream(new int[]){1, 2, 3});
🔹 특정 범위의 정수 ➜ 스트림
- IntStream과 LongStream은 지정된 범위의 연속된 정수를 스트림으로 생성해서 반환하는 ' range() ', ' rangeClosed() ' 메서드를 갖고 있다
IntStream Stream = IntStream.range(1, 5); // 1, 2, 3, 4
IntStream Stream = IntStream.rangeClosed(1, 5); // 1, 2, 3, 4, 5➜ int보다 큰 범위의 스트림은 LongStream으로 생성
🔹 난수 ➜ 스트림
- Random class에는 난수로 이루어진 '무한 스트림'을 반환하는 인스턴스 메서드들이 있다
( ints(), longs(), doubles() )
➜ ' limit() ' 을 이용해 스트림의 크기를 제한해줘야 한다
IntStream intStream = new Random.ints().limit(5) // 5개의 랜덤 int
// 유한 스트림 생성, limit() 필요 X
// = new Random.ints(5, 1, 10) // [1, 10) 범위의 난수 5개를 가진 스트림 반환
// IntStream ints(int begin, int end)
// IntStream ints(long streamSize, int begin, int end)
🔹 람다식 ➜ 스트림
- ' iterate() ' 와 ' generate() ' 는 람다식을 매개변수로 받아서, 이 람다식에 의해 계산되는 값들을 요소로 하는 무한 스트림을 생성
static <T> Stream<T> iterate(T seed, UnaryOperator<T> f)
static <T> Stream<T> generate(Supplier<T> s) // 매개변수가 없는 람다식만 허용
1. ' iterate() ' 는 seed 값으로 지정된 값부터 람다식 f에 의해 계산된 결과를 다시 seed 값으로 해서 계산을 반복
Stream.iterate(0, n -> n + 2) // 0, 2, 4, 6 ...
2. ' generate() ' 는 ' iterate() ' 와 달리, 이전 결과를 이용해서 다음 요소 계산 X
// [0, 1)사이의 수(double)를 가진 무한 스트림
Stream<Double> randomStream = Stream.generate(Math::random)
- 단, ' iterate() ' 와 ' generate() ' 에 의해 생성된 스트림은 기본형(Primitive) 스트림 타입의 참조변수로 다룰 수 없다 !
( 굳이 필요하면, ' mapToInt() ' 같은 메서드로 변환을 해주면 된다 )
IntStream evenStream = Stream.iterate(0, n -> n + 2).mapToInt(Integer::valueOf);
Stream<Integer> stream = evenSteram.boxed(); // IntStream -> Stream<Integer>
🔹 파일 ➜ 스트림
- java.nio.file.Files에서 제공
list() : 지정된 디렉토리(dir)에 있는 파일의 목록을 소스로 하는 스트림을 생성하여 반환
Stream<Path> Files.list(Path dir)
lines() : 파일의 한 행(line)을 요소(행 단위)로 하는 스트림을 생성
( 파일 뿐만 아니라 다른 입력 대상으로부터도 읽어올 수 있다 )
// BufferedReadar class
Stream<String> Files.lines(Path path)
Stream<String> Files.lines(Path path, Charset cs)
Stream<String> lines()
🔹 빈 스트림
- 스트림에 연산을 수행한 결과 하나도 없을 때, null보다 빈 스트림을 반환하는 것이 좋다
Stream.empty(); // 빈 스트림을 생성해서 반환
emptyStream.count(); // 0; 스트림 내 요소의 개수를 반환
🔹 두 스트림의 연결
- Stream.conat() - 연결하려는 두 스트림의 요소는 같은 타입(ex. String)이어야 한다
Stream<String> stringStream = Stream.concat(strStream1, strStream2);
✔️ 스트림(Stream)의 중간 연산
🔹 스트림 자르기 - skip(), limit()
- Stream class에 정의된 skip(), limit()
Stream<T> skip(long n)
Stream<T> limit(long maxSize)
- 기본형 스트림 class(ex. IntStream)에도 skip(), limit이 정의돼 있다
➜ 반환 타입이 기본형 스트림 ( 매개변수의 타입은 똑같이 long )
// IntStream
intStream.skip(3) // 4번째 요소부터
.limit(5) // 5개로 제한 (4~8번째 요소)
🔹 스트림의 요소 필터링 - filter(), distinct()
Stream<T> distinct()
Stream<T> filter(Predicate<? super T> predicate)- distinct() : 중복된 요소 제거
- filter() : 주어진 조건(Predicate)에 맞지 않는 요소를 걸러낸다
➜ 매개변수로 Predicate 말고도 boolean 타입의 값을 반환하는 람다식도 사용 가능
➜ 다른 조건으로 ' filter() ' 를 여러 번 호출 가능
stream.distinct() // 중복제거
.filter(i -> i % 2 == 0) // 짝수만 남기기
🔹 스트림 정렬 - sorted()
- sorted()
Stream<T> sorted()
Stream<T> sorted(Comparator<? super T> comparator)
➜ Comparator나 int 값을 반환하는 람다식으로 정렬 기준을 지정하여 정렬한다
➜ 별도로 지정해주지 않으면, 요소의 ' 기본 정렬 기준(Comparble) ' 으로 정렬
( 단, 스트림의 요소가 Comparable을 구현한 class(ex. String)가 아니면 예외 발생 )
// 문자열 스트림을 String에 정의된 기본 정렬(사전순)로 정렬 후 출력
Stream<String> strStream = Stream.of("dd", "aaa", "CC", "cc", "b");
strStream.sorted().forEach(System.out::print); // CCaaabccdd
- Comparator interface에 있는 static, default 메서드들을 활용하여 정렬을 쉽게 하자 !
comparing()
(1) 스트림의 요소가 Comparable을 구현한 경우 기본 정렬 기준으로 정렬
(2) 그렇지 않았다면, 추가적인 매개변수로 ' 정렬 기준 (Comparator) '을 따로 지정해줘야 한다
( 비교대상이 기본형(Primitive)인 경우, ' comparingInt() ' 와 같은 메서드를 사용해서 효율적(Auto-boxing & Unboxing 하여 따로 변환해줄 필요 X)으로 정렬하자 )
thenComparing() : 정렬 조건을 추가할 때 사용
thenComparing(Comparator<T> other)
thenComparing(Function<T, U> keyExtractor) // T (입력) ➜ U (출력)
thenComparing(Function<T, U> keyExtractor, Comparator<U> keyComp)
// 학생의 성적을 반별 오름차순, 성적별 내림차순으로 정렬하여 출력
// main메서드
// studentStream : Student class의 instance들을 담은 스트림의 참조변수
// Stream<Student> studentStream = Stream of(
new Student("신민규", 1, 900),
...
);
studentStream.sorted(Comparator.comparing(Student::getBan) // 반별 정렬
.thenComparing(Comparator.naturalOrder()) // (1) 기본 정렬 (성적별 내림차순)
// .thenComparing(Student::getTotalScore, (a, b) -> b - a) // (2)
.forEach(System.out::println);
// Student class : (1) Comparable을 구현
class Student {
String name;
int ban;
int totalScore;
...
// 성적별 내림차순을 기본 정렬 기준으로 한다
public int compareTo(Student s) {
return s.totalScore - this.totalScore;
}
}
( Comparator의 메서드 참고 )
Comparator (Java SE 20 & JDK 20) (oracle.com)
Comparator (Java SE 20 & JDK 20)
Type Parameters: T - the type of objects that may be compared by this comparator All Known Implementing Classes: Collator, RuleBasedCollator Functional Interface: This is a functional interface and can therefore be used as the assignment target for a lambd
docs.oracle.com
( Comparable과 Comparator 차이 관련 내용 참고 )
[JAVA] 컬렉션 프레임웍 ( Collections Framework ) — Uykm_Note (tistory.com)
[JAVA] 컬렉션 프레임웍 ( Collections Framework )
🌑 컬렉션 프레임웍 (Collections Framework) ✔️ Collections Framework의 핵심 interface 🔸 Vector · Hashtable과 같은 기존의 Collections class들 대신 ArrayList · HashMap 을 사용하자 기존의 Collections class들은 호환을
ukym-tistory.tistory.com
🔹 변환 - map()
- 스트림 요소에서 원하는 필드만 뽑아내거나 특정 형태로 변환해야 할 때 사용 !
- ' filter ' 처럼 하나의 스트림에 여러 번 적용 가능
Stream<R> map(Function<? superT, ? extends R> mapper)
// studentStream.map(Student::getName); // 아래와 같은 동작
studentStream.map(s -> s.getName()); // Stream<Student> => Stream<String>
.map(String::toUpperCase) // 모두 대문자로 변환
🔹 조회 - peek()
- ' forEach() - 최종 연산 ' 와 달리 요소를 소모하지 않고 요소를 조회
➜ 중간 연산에 대한 결과를 확인하는 용도로 사용
studentStream.map(s -> s.getName())
.peek(System.out::println) // 이렇게 중간 연산결과 확인 가능
// .peek(s -> System.out.println(s))
🔹 mapToInt(), mapToLong(), mapToDouble()
- ' map() ' 은 연산 결과로 Stream<T> 타입의 스트림을 반환하는데,
타입 T가 기본형일 경우엔 애초부터 ' mapToA() ' 를 사용해 기본형 스트림으로 변환하여 반환하자
IntStream mapToInt(ToIntFunction<? super T> mapper) // ToAFunction<? super T> : T (입력) ➜ A (출력)
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper)
LongStream mapToLong(ToLongFunction<? super T> mapper)
studentStream.map(Student::getTotalScore) // Stream<Integer> 반환
studentStream.mapToInt(Student::getTotalScore) // IntStream 반환
- ' mapToA() ' 의 장점은 ?
- Auto-boxing & Unboxing을 할 필요가 없어서 효율적이다
- ' count() ' 만 지원하는 Stream<T>와 달리 IntStream과 같은 기본형(Primitive) 스트림은 숫자를 다루는데 편리한 메서드들을 제공한다
- Auto-boxing & Unboxing을 할 필요가 없어서 효율적이다
최종 연산 메서드 ( Stream에 있는 ' max() ' 와 ' min() ' 은 매개변수로 Comparator를 지정해야 한다 )
int sum() // 스트림의 모든 요소의 총합
OptionalDouble average() // sum() / (double)count()
OptionalInt max() // 스트림 요소중 제일 큰 값
OptionalInt min() // 스트림 요소 중 제일 작은 값
➜ 최종 연산이기 때문에, ' summaryStatistics() ' 메서드 제공
// LongStream, DoubleStream도 아래와 같은 연산 메서드 제공
IntSummaryStatistics stat = studentStream.mapToInt(Student::getTotalScore)
.summaryStatistics();
long totalCount = stat.getCount();
long totalScore = stat.getSum();
double avgScore = stat.getAverage();
int minScore = stat.getMin();
int maxScore = stat.getMax();
int totalScore = students.mapToInt(Student::getTotalScore)
.sum(); // 이렇게 따로도 가능
OptionalDouble average = students.mapToInt(Student::getTotalScore)
.average(); // 평균이 0인 경우도 있을 수 있다🔻 스트림의 요소가 하나도 없을 때엔 count()나 sum()은 0을 반환하면 되지만, 다른 연산 메서드들은 그럴 수 없다
➜ 그래서 OptionalDouble을 반환하는 것 ( Optional class들에 대해선 뒤에 정리 )
- ' mapToInt() ' 와 함께 자주 사용되는 메서드
- Integer::parseInt()
➜ 파라미터로 받은 문자열(String)을 정수 값(int)으로 파싱(=변환) 후 반환 - Integer::intValue()
➜ 파라미터로 받은 Integer 타입 객체를 기본형 타입(int)인 정수 값으로 반환 - Integer::valueOf()
➜ 파라미터로 받은 문자열(String)이나 정수 값(int)을 Wrapper 클래스 타입(Integer)의 객체로 변환 후 반환
ex) new Integer(Integer.parseInt("127")); ➜ 반환값
- Integer::parseInt()
mapToInt(Integer::parseInt) // Stream<String> ➜ IntStream
mapToInt(Integer::intValue) // Stream<Integer> ➜ IntStream
mapToInt(Integer::valueOf) // Stream<Integer> ➜ IntStream (Error)🔻 'mapToInt(Integer::valueOf)' 를 사용할 때 에러가 발생하는 이유 ?
➜ mapToInt()는 기본형 타입으로 매핑(변환)하여 기본형 스트림으로 반환해주는 메서드인데, valueOf()는 문자열이나 기본형 값을 객체로 변환(Boxing)시켜주는 것이라 충돌이 발생하기 때문이다 !
- 반대로 기본형(Primitive) 스트림을 Stream<T>로 변환할 때 ➜ mapToObj()
기본형(Primitive) 스트림을 Stream<Primitive Type>로 변환할 때 ➜ boxed()
🔹 flatMap() - Steam<T[]> ➜ Stream<T>
- 스트림의 요소가 배열이거나 ' map() ' 으로 변환된 스트림의 요소가 배열인 경우,
즉 스트림의 타입이 Stream<T[]>인 경우, Stream<T>로 다루는 것이 편리할 때가 있다
➜ 이때 ' flatMap() ' 사용
String[] lines = {
"I am hungry",
"I want a Chicken!"
}
// "I" "am" "hungry" "I" "want" "a" "Chicken!" 와 같은 스트림을 원한다
Stream<String> linesStream = Arrays.stream(lines); // "I am hungry", "I want a Chicken!"
Stream<String[]> arraysStream = linesStream.map(line -> line.split(" ")); // (1)
// ["I", "am", "hungry"], ["I", "want", "a", "Chicken!"]
// 스트림 안에 스트림이 있는 형태
Stream<Stream<String>> wrongStream = arraysStream.map(s -> Arrays.stream(s)); // (2)
// = arraysStream.map(Arrays::stream);
// 아래줄은 (1), (2) 코드를 압축한 코드
// = linesStream.map(line -> Stream.of(line.split(" ")))
// 원하는 형태의 스트림으로 변환
Stream<String> correctStream = arraysStream.flatMap(s -> Arrays.stream(s)); // (3)
// = arraysStream.flatMap(Arrays::stream);
// 아래줄은 (1), (3) 코드를 압축한 코드
// = linesStream.map(line -> Stream.of(line.split(" ")))
- Stream<Stream<T>> ➜ Stream<T>
: 드물지만, 스트림을 요소로 하는 스트림을 하나의 스트림으로 합칠 때도 사용
Stream<String> oneStream = wrongStream.flatMap(s -> Arrays.stream(s))
// = wrongStream.flatMap(Arrays::stream)
✔️ Optional<T> & OptionalInt
🔹 Optional<T> ?
- Optional<T>는 지네릭 클래스로 'T타입의 객체'를 감싸는 Wrapper class이다
➜ Optional 타입의 객체에는 모든 타입의 참조변수를 담을 수 있다 - 최종 연산의 결과는 그냥 반환하는 것보다 Optional 객체에 담아서 반환하자
➜ if문 없이도 Optional class의 메서드를 이용해 반환된 결과가 null이 아닌지 간단히 체크할 수 있다
( NullPointerException이 방지 )
public final class Optional<T> {
private final T value; // T 타입의 참조변수
...
}
Optional (Java SE 10 & JDK 10 ) (oracle.com)
Optional (Java SE 10 & JDK 10 )
If a value is present, returns the result of applying the given Optional-bearing mapping function to the value, otherwise returns an empty Optional. This method is similar to map(Function), but the mapping function is one whose result is already an Optiona
docs.oracle.com
🔹 Optional 객체 생성
- 매개변수로 받을 참조변수의 값이 null일 가능성이 있다면, of 대신 ofNullable() 사용 !
( of() : 매개변수의 값이 null이면 NPE 발생 )
String object = "string";
Optional<String> optional = Optional.of(object);
// = Optional.of("string");
// = Optional.of(new String(string))'
Optional<String> optional = Optional.ofNullable(object);
- Optional<>타입의 참조변수 초기화
- null로 초기화
- ' empty() ' 로 초기화
Optional<String> optVal = null;
Optional<String> optVal = Optional<String>.empty(); // 빈 객체로 초기화 (지향)
🔹 Optional 객체의 값 가져오기
T orElseGet(Supplier<? extends T> other)
T orElseThrow(Supplier<? extends X> exceptionSupplier) // 람다식을 매개변수로 제공 가능
String s = optional.get(); // 만약 value가 null이면 NoSuchElementException 예외 발생
String s = optional.orElse(""); // value == null ? "": value
String s = optional.orElseGet(String::new); // () -> new String()
String s = optional.orElseThrow(NullPointException::new); // () -> new NullPointException
- Optional 객체도 ' filter() ', ' map() ', ' flatMap() ' 사용 가능
➜ Optional 객체의 값이 null이면, 이 메서드들은 아무 작업도 수행 X
int result Optional.of("531")
.filter(x -> x.length > 0)
.map(Integer::parseInt)
.orElse(-1); // result = 531
int result Optional.of("")
.filter(x -> x.length > 0) // null이 된다
.map(Integer::parseInt) // 아무 작업도 수행 X
.orElse(-1); // result = -1
- isPresent() - Optional 객체의 값이 null이면 false, 아니면 true 반환
➜ Optional<T>를 반환하는 최종 연산과 잘 어울린다
( Optional<T>를 반환하는 최종 연산은 몇 개 없다 )
ex. findAny(), findFirst(), max(Comparator<? super T> comparator), min(Comparator comparator), reduce(BinaryOperator<T> accumulator)
Boolean isPresent(Consumer<T> block) // 람다식을 매개변수에 제공 가능
if(Optional.ofNullable(object).isPresent()) { // if(object != null) {
System.out.println(object);
}
// 이처럼 간단히 바꿀 수 있다
Optional.ofNullable(object).isPresent(() -> System.out.println(object));
🔹 OptionalInt, OptionalLong, OptionalDouble
- IntStream과 같은 기본형 스트림은 Optional도 기본형을 값으로 하는 OptionalInt, OptionalLong, OptionalDouble을 반환 !
( 반환 타입이 Optional<T>가 아니라는 것을 제외하고는 Stream에 정의된 것과 유사하다 )
ex. OptionalDouble average()
| Optional class | 값을 반환하는 메서드 | 설명 |
| Optional<T> | T get() | Optinal 객체에 저장된 값을 가져온다 |
| OptionalA | getAsA | A자리 - Int, Long, Double 반환 값의 타입은 A |
- OptionalInt 객체에 저장된 값이 없는 것과 0이 저장된 것은 구분 가능하다
( Optional 객체의 경우 null을 저장하면 비어있는 것과 동일하게 취급 )
OptionalInt opt = OptionalInt.of(0); // OptionalInt에 0을 저장
OptionalInt opt2 = OptionalInt.empty(); // int의 기본값은 0이므로 빈 객체(OptionalInt.empty())에 저장되는 값은 0이다
Optional opt3 = Optional.ofNullable(null);
Optional opt4 = Optional.empty();
opt.equals(opt2); // false
opt3.equals(op4); // true
// OptionalInt class
public final class OptionalInt {
...
private final boolean isPresent; // 값이 저장돼 있으면 true
private final int value; // int 타입의 변수
...
}
✔️ 스트림의 최종 연산
🔹 forEach()
- peek()과 달리 스트림의 요소를 소모하는 최종 연산
void forEach(Consumer<? super T> action) // 람다식 사용 가능
🔹 조건 검사 - allMatch(), anyMatch(), noneMatch(), findFirst(), findAny()
- 스트림 요소에 대해 지정된 조건에 모든 요소가 일치(allMatch)하는지, 일부가 일치(anyMatch)하는지, 어떤 요소도 일치하지 않는지(findAny) 확인하는 데 사용하는 메서드
➜ 모두 매개변수로 Predicate를 요구하며, 반환 타입은 boolean이다
// 총점이 100 이하인 학생이 있는지 확인
stuStream.anyMatch(s -> s.getTotalScore() <= 100)
- findFirst() ➜ 스트림의 요소 중에서 조건에 일치하는 첫 번째 것을 반환 ( 주로 ' filter() ' 와 함께 사용 )
- findAny() ➜ 병렬 스트림의 경우 findFirst() 대신에 사용
( 스트림의 요소가 없을 때는 비어있는 Optional 객체를 반환 )
Optional<Student> stu = stuStream.filter(s -> s.getTotalScore() <= 100).findFirst();
Optional<Student> stu = parallelStream.filter(s -> s.getTotalScore() <= 100).findAny();
🔹 통계 정보 얻기 - count(), sum(), average(), max(), min()
- IntStream과 같은 기본형 스트림이 아닌 경우엔 통계와 관련된 메서드는 3개밖에 없다 ( 잘 사용 X )
➜ 대부분 기본형 스트림으로 변환하거나, ' reduce() ' 나 ' collect() ' 를 사용해서 통계 정보를 얻는다
long count()
Optional<T> max(Comparator<? super T> comparator)
Optional<T> min(Comparator<? super T> comparator)
🔹 리듀싱 - reduce()
- 스트림의 요소를 줄어나가면서 연산을 수행하고 최종결과를 반환
➜ 매개변수의 타입이 BinaryOperator<T>인 이유 ( 처음 두 요소를 가지고 연산한 결과 + 다음 요소 .. )
➜ 초기값(identity)과 어떤 연산(BinaryOperator)으로 스트림의 요소를 줄여나갈 것인지 생각하며 사용하면 된다
Optional<T> reduce(BinaryOperator<T> accumulator)
T reduce(Tidentity, BinaryOperator<T> accumulator)
// combiner는 병렬 스트림에 의해 처리된 결과를 합칠 때 사용하는 매개변수
U reduce(U identity, BiFunction<U, T, U. accumulator, BinaryOperator<U> combiner)
- ' max() ' 와 ' min() ' 의 경우, 초기값이 필요없어 Optimal<T>를 반환하는 매개변수 하나짜리 ' reduce() ' 를 사용하자
// 반환 타입 T (int)
int count = intStream.reduce(0, (a, b) -> a + 1);
int sum = intStream.reduce(0, (a, b) -> a + b);
// 반환 타입 : OptionalInt
OptionalInt max = intStream.reduce((a, b) -> a > b ? a : b); // intStream.reduce(Integer::max)
OptionalInt max = intStream.reduce((a, b) -> a < b ? a : b); // intStream.reduce(Integer::min)
✔️ collect()
🔹 collect() ?
- 스트림의 요소를 수집하는 최종 연산 중 하나이다
➜ 어떻게 수집할 것인가에 대한 방법을 정의한 것이 컬렉터(Collector) 인터페이스
Collectors class
- Collector interface를 구현한 class
- 다양한 종류의 컬렉터를 반환하는 static 메서드를 갖고 있다 )
- ' collect() ' 는 매개변수의 타입이 Collector이다
➜ 매개변수가 Collector interface를 구현한 class의 객체이어야 한다는 의미
( sort()할 때, Comparator가 필요한 느낌 )
Object collect(Collector collector)
Object collect(Supplier supplier, BiConsumer accumulator, BiConsumer combiner)
➜ 매개변수가 3개인 ' collect() ' 는 간단히 람다식으로 수집할 때 사용하기 편리하다
🔹 스트림 ➜ 컬렌션 or 배열
- toList(), toSet(), toMap(), toCollection(), toArray()
- List나 Set이 아닌 특정 컬렉션을 지정하고 싶을 땐,
' toCollection() 에 해당 컬렉션의 생성자 참조를 매개변수로 넣어주면 된다
List<String> names = studentStream.map(s -> s.getName())
.collect(Collectors.toList());
ArrayList<String> list = names.stream()
.collect(toCollection(ArrayList::new));
- Map은 객체의 어떤 필드를 키와 값으로 사용할지 지정해주면 된다
// 요소의 타입이 Person인 스트림에서 사람의 이름을 key로, Person의 객체를 value로 저장
Map<String, Student> map = personStream.collect(Collectors.toMap(p -> p.getName(), p -> p));🔻 항등 함수를 의미하는 ' p -> p ' 대신 Function.identity() 사용 가능
- 스트림에 저장된 요소들을 ' T[] ' 타입의 배열로 변환
➜ ' toArray() ' 사용
( 단, 해당 타입(Student)의 생성자 참조를 매개변수로 지정해줘야 한다 )
Student[] studentNames = studentStream.toArray(Student::new));
Student[] studentNames = studentStream.toArray(); // Error
Object[] studentNames = studentStream.toArray(); // OK : 지정하지 않으면 'Object[]' 타입으로 반환
🔹 통계 정보 얻기
- counting(), summingA(), averagingA(), maxBy(), minBy()
- A에는 Int, Long, Double이 올 수 있다
- 다른 최종 연산들이 제공하는 통계 정보와 다를 것 없이 똑같다
➜ ' groupingBy() ' 와 함께 사용할 때 필요
// Collectors의 static 메서드를 호출할 때는 'Collectors.'를 생략했다
long count = stuStream.count();
long count = stuStream.collect(counting()); // Collectors. counting()
long totalScore = stuStream.mapToInt(Student::getTotalScore).sum();
long totalScore = stuStream.Collect(summingInt(Student::getTotalScore());
OptionalInt topScore = stuStream.mapToInt(Student::getTotalScore)
.max();
Optional<Student> topStudent = stuStream
.max(Comparator.comparingInt(Student::getTotalScore));
Optional<Student> topStudent = stuStream
.collect(maxBy(Comparator.comparingInt(Student::getTotalScore)));
IntSummaryStatistics stat = stuStream
.mapToInt(Student::getTotalScore).summaryStatistics();
IntSummaryStatistics stat = stuStream
.collect(summarizingInt(Student::getTotalScore));
🔹 리듀싱 - reducing()
- IntStream에는 매개변수 3개짜리 ' collect() ' 만 정의되어 있어,
boxed를 통해 IntStream을 Stream<Integer>로 변환해야 매개변수 1개짜리 ' collect() ' 사용 가능
Collector reducing(BinaryOperator<T> op)
Collector reducing(T identity, BinaryOperator<T> op)
Collector reducing(U identity, Function<T, U> mapper, BinaryOperator<T> op)
long sum == intStream.reduce(0, (a, b) -> a + b);
int grandTotal = stuStream.map(Student::getTotalScore).reduce(0, Integer::sum);
// collect() 사용
long sum == intStream.boxed().collect(reducing(0, (a, b) -> a + b));
int grandTotal = stuStream.collect(reducing(0, Student::getTotalScore, Integer::sum)); // map() + reduce()
🔹 문자열 결합 - joining()
- 문자열 스트림의 모든 요소를 하나의 문자열로 연결해서 반환
➜ 스트림의 요소가 CharSequence의 자손인 경우에만 결합 가능 ( String이나 StringBuffer처럼 )
➜ 따라서, 문자열이 아닌 경우엔 먼저 ' map() ' 을 이용해서 문자열로 변화해줘야 한다 !
studentNames.map(Student::getName).collect(joining()); // A B C ...
// 구분자 지정 가능
studentNames.map(Student::getName).collect(joining(", ")); // A, B, C, ...
// 접두사, 접미사 지정 가능
studentNames.map(Student::getName).collect(joining(", ", "[", "]")); [A, B, C ...]
✔️ 그룹화와 분할 - groupingBy(), partitioningBy()
🔹 그룹화와 분할
- ' collect() ' 를 왜 알아야 하고, 어떤 부분에서 유용한지 알 수 있는 작업이 그룹화와 분할이다
- 그룹화 - groupingBy()
➜ 스트림의 요소를 특정 기준으로 그룹화하는 것을 의미 - 분할 - partitioningBy()
➜ 스트림의 요소를 두 가지(지정된 조건에 일치하는 그룹, 일치하지 않는 그릅)로 분할 - ' groupingBy ' & ' partitioningBy() '
- 차이 - 분류를 Function으로 하는가, Predicate로 하는가
- 스트림을 두 개의 그룹으로 나눠야 한다면 당연히 ' partitioningBy() ' 가 효율적
( 그 외엔 ' groupingByu() ' 를 쓰자 ) - 그룹화와 분할의 결과는 Map에 담겨 반환된다
- 차이 - 분류를 Function으로 하는가, Predicate로 하는가
🔹 분할 - partitioningBy()에 의한 분류
- Predicate로 분류한다
Collector partitioningBy(Predicate predicate)
Collector partitioningBy(Predicate predicate, Collector downstream)
- 기본적인 분할
Map<Boolean, List<Student>> studentByGender = studentStream.collect(partitioningBy(Student::isMale));
List<Student> maleStudent = studentByGender.get(true)
List<Student> femaleStudent = studentByGender.get(false)
- 통계 정보를 이용한 분할
Map<Boolean, Long> stuNumByGender = studentStream.collect(partitioningBy(Student::isMale, counting()));
stuNumByGender.get(true)
stuNumByGender.get(false)
- ' partitioningBy() ' 도 중첩하여 사용 가능하다
// 불합격자를 분류하고, 성별로 또 분류
Map<Boolean, Map<Boolean, List<Student>>> failedStuByGender
= stuStream.collect(
partitioningBy(Student::isMale,
partitioningBy(s -> s.getScore() < 15)
)
);
List<Student> failedMaleStu = failedStuByGender.get(true).get(true);
List<Student> failedFemaleStu = failedStuByGender.get(false).get(true);
- ' collectingAndThen() ' 을 활용하면 'collecting' 을 진행한 후(AndThen) 얻은 결과로 메서드를 하나 더 호출 가능하다
Map<Boolean, Map<Boolean, List<Student>>> failedStuByGender
= stuStream.collect(
partitioningBy(Student::isMale,
// maxBy ➜ 남학생 1등과 여학생 1등을 구한다
// Optional::get
// ➜ maxBy의 반환타입이 Optional<Student>이기 때문에
// ➜ Optional<Student>가 아닌 Student를 반환 결과로 얻는다
collectingAndThen(
maxBy(comparingInt(Student::getScore)), Optional::get
)
)
);
🔹 그룹화 - groupingBy()에 의한 분류
- Function으로 분류
➜ 스트림을 특정 기준으로 그룹화
Collector groupingBy(Function classifier)
Collector groupingBy(Function classifier, Collector downstream)
Collector groupingBy(Function classifer, Supplier mapFactory, Collector downstream)
- ' groupingBy() '로 그룹화를 하면 기본적으로 List<T>에 담긴다 ( toList() 생략 )
➜ toList() 대신 toSet()이나 toCollection(HashSet::new) 사용 가능
( 단, Map의 지네릭 타입도 적절하게 변경해주자 )
Map<Integer, List<Student>> studentByBan = students
.collect(groupingBy(Student::getBan, toList())); // toList() 생략 가능
- ' partitioningBy() ' 처럼 중첩 가능
- ' partitioningBy() ' 처럼 ' collectingAndThen() ' 을 활용하면 'collecting' 을 진행한 후(AndThen) 얻은 결과로 메서드를 하나 더 호출 가능하다
( 변환하는 ' mapping() ' 메서드도 ' collectingAndThen() ' 처럼 사용 가능하다 )
✔️ Collector 구현
🔹 컬렉터를 작성한다는 것 = Collector interface를 구현한다는 것
- 직접 구현해야 하는 메서드는 총 5개인데, ' characteristics() ' 메서드를 제외하면 모두 반환타입이 함수형 인터페이스이다
➜ 즉, 4개의 람다식을 작성하면 되는 것 !
public interface Collector<T, A, R> {
Supplier<A> supplier(); // 작업(수집; collect) 결과를 저장할 공간을 제공
BiConsumer<A, T> accumulator(); // 스트림의 요소를 수집(collect)할 방법을 제공
// 스트림의 요소를 'supplier()'가 제공한 공간에 어떻게 누적할 것인가
BinaryOperator<A> combiner(); // 두 저장공간을 병합할 방법을 제공 (병렬스트림)
// 여러 쓰레드에 의해 처리된 결과를 어떻게 합칠 것인가
Function<A, R> finisher(); // 작업 결과를 최종적으로 변환할 방법을 제공
// 변환이 필요없다면, 항등 함수인 'Function.identity()' 반환
Set<Characteristics> characteristics(); // 컬렉터의 특성이 담긴 Set을 반환
// 컬렉터가 수행하는 작업의 속성에 대한 정보 제공
...
}Characteristics.CONCURRENT ➜ 병렬로 처리할 수 있는 작업
Characteristics.UNORDERED ➜ 스트림의 요소의 순서가 유지될 필요가 없는 작업
Characteristics.IDENTITY_FINISH ➜ 'finisher()'가 항등 함수인 작업
➜ 3가지 속성 중에서 해당하는 것을 Set에 담아서 반환하도록 구현하면 된다
( 아무런 속성도 지정하고 싶지 않으면 비어있는 Set 반환 )
public Set<Characteristics> characteristics() {
return Collections.unmodifableSet(EnumSet.of(
Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED
));
}
// 아무 속성 X
Set<Characteristics> characteristics() {
return Collections.emptySet();
}
- Stream<String>의 모든 문자열을 하나로 결합해서 String으로 반환하는 ConcatCollector
import java.util.*;
import java.util.function.*;
import java.util.stream.*;
class MyCollector {
public static void main(String[] args) {
String[] strArr = { "aaa", "bbb", "ccc" };
Stream<String> strStream = Stream.of(strArr);
String result = strStream.collect(new ConcatCollector());
System.out.println(result);
}
}
class ConcatCollector implements Collector<String, StringBuilder, String> {
@Override
public Supplier<StringBuilder> supplier() { // 저장할 공간 생성
return() -> new StringBuilder();
// return StringBuilder::new;
}
@Override
public BiConsumer<StringBuilder, String> accumulator() { // 수집하여 저장하는 방법
return (sb, s) -> sb.append(s);
// return StringBuilder::apend;
}
@Override
public BinaryOperator<StringBuilder> combiner() { // 두 저장공간(StringBuilder) 결합
return (sb, sb2) -> sb.append(sb2);
// return StringBuilder::append;
}
@Override
public Function<StringBuilder, String> finisher() { // 반환할 타입(String)으로 변환하여 반환
return sb -> sb.toString();
// return StringBuilder::toString;
}
@Override
public Set<Characteristics> characteristics() {
return Collections.emptySet();
}
}aaabbbccc
🌓 스트림(Stream)의 변환
✔️ 스트림(Stream) 간의 변환
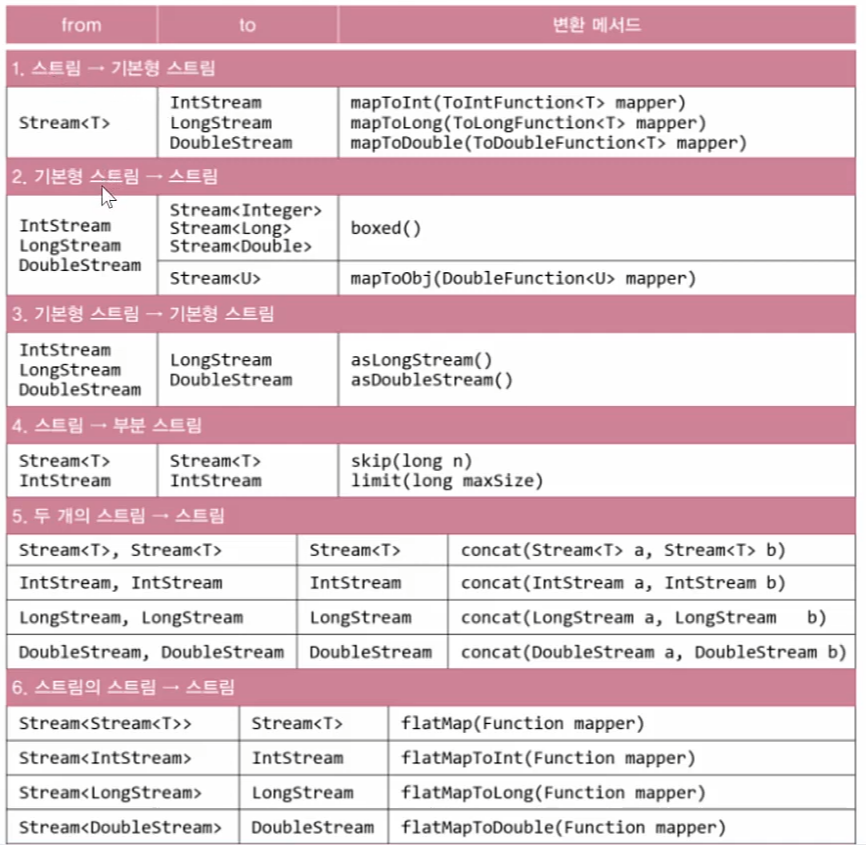
🔹 스트림 변화에 사용되는 메서드를 정리한 표
- 변환 방법은 어렵지 않지만 언제 어떤 메서드를 써야하는지 매번 찾아보기 어렵다

▼ Study📋
☑️ 스트림(Stream)의 중간 연산( ex. peek() )은 스트림의 요소를 소모하지 않지만 (중간 연산의 반환값은 스트림이 때문에, 반환된 스트림을 가지고 이어서 연산 가능), 최종 연산( ex. forEach )은 요소를 소모하여 단 한 번만 가능하다 (최종 연산을 하면 반환값이 스트림이 아니기 때문에, 그 이후엔 해당 스트림을 사용할 수 없다) !
☑️ 값을 반환하기 전에 NULL 체크를 Optional 객체를 자주 이용한다 ( ex. Spring을 다룰 때 )
☑️ 최종 연산 메서드 중에 조건을 검사하는 ' forAny() ' 메서드는 Spring을 다룰 때 많이 쓴다
☑️ Collector class는 그룹화할 때 자주 쓰인다
🌑 람다식 (Lamda expression)
✔️ 람다식 ?
🔹 람다식(Lamda expression) : 메서드를 하나의 '식(expression)'으로 표현한 것
- class, 메서드, 객체 필요 X
➜ 람다식 자체만으로 메서드의 역할을 수행
➜ 즉, 메서드라는 개념보다 '익명 함수(function; 특정 class에 속하지 X)'라고 하는 것이 적절하다 - 쉽게 말하면 메서드를 변수처럼 다룰 수 있게 된다 (반환값, 매개변수)
- 메서드를 변수처럼 다루는 것이 어떻게 가능한가?
(아래 "함수형 인터페이스 - @FunctionalInterface" 관련 내용 참고)
람다식을 참조변수로 다룬다는 것
➜ 메서드를 통해 람다식을 주고받을 수 있다는 의미, 즉 메서드를 변수처럼 주고받는 것이 가능
➜ 사실은 메서드가 아니라 객체(익명 객체 ➟ 람다식)를 주고받는 것이긴 하다
- 메서드를 변수처럼 다루는 것이 어떻게 가능한가?
🔹 람다식 작성은 어떻게 할까 ?
- '익명 함수'답게 메서드 이름과 반환타입 제거
( 반환타입은 추론 가능하기 때문에 제거하는 것 ) - 매개변수 선언부와 몸체{} 사이에 ' -> ' 추가
- 람다식에서 식(expression)의 결과 자체가 반환값일 경우엔, return문을 '식'으로 대신
- '문장(statement)'이 아닌 '식'이므로 끝에 ' ; '을 붙이지 않는다
ex)int max(int a, int b) -> {
returna > b ? a : b;
} - 매개변수의 타입도 추론 가능한 경우엔 생략 가능 ➜ 대부분의 람다식에서 생략
- (1)매개변수가 하나뿐이고 (2)매개변수의 타입이 생략된 경우엔 괄호()도 생략 가능
( () ➜ 매개변수가 없는 경우엔 생략 X ) - (1)몸체{}안의 문장이 하나이고 (2)return문이 아니면 중괄호{}도 생략 가능
// (int a, int b) -> a > b ? a : b
(a, b) -> a > b ? a : b
// int square(int x) { return x * x; }
x -> x * x; // OK
int x -> x * x // Error
✔️ 함수형 인터페이스 (Functional Interface)
🔹 함수형 인터페이스가 왜 필요할까 ?
- 결론부터 말하면, 함수형 인터페이스가 필요한 이유는 람다식을 다루기 위해서이다
- 일단, 람다식은 메서드와 동등한 것이 아닌, 익명 클래스(Anonymous class)의 객체와 동등하다
- 익명 클래스의 객체(람다식)의 메서드 호출 방법
1. 일반적인 객체의 메서드를 호출할 때처럼 참조변수가 필요하다
➜ 즉, 메서드를 호출할 익명 객체를 생성해야 한다
(참조변수의 타입) f = (int a, int b) -> a > b ? a : b;
2. 참조변수의 타입은 ?
➜ 람다식과 동등한 메서드가 정의되어 있는 class나 interface !
interface MyFunction {
// 람다식과 동등한 max() 메서드
public abstract int max(int a, int b);
}
3. 해당 interface를 구현한 익명 클래스의 객체를 생성하고, 익명 객체의 메서드를 호출
MyFunction f = new MyFunction() { // 익명 객체
public int max(int a, int b) {
return a > b ? a : b;
}
};
int bigNum = f.max(5, 3); // 익명 객체의 메서드를 호출𐰸 𐰸
MyFunction f = (int a, int b) -> a > b ? a : b; // 익명 객체를 람다식으로 대체
int big = f.max(5, 3); // 익명 객체의 메서드를 호출
🔻 그렇다면, 람다식으로 익명 객체를 어떻게 대체하는 것일까?
➜ 람다식도 사실 익명 객체이며, 익명 객체의 메서드, 매개변수의 타입과 개수, 반환값이 일치하기 때문이다
- 따라서, 람다식을 interface를 통해 다루기로 결정
➜ 람다식을 다루기 위한 interface를 '함수형 인터페이스 (functional interface)'라 한다 !
🔹 함수형 인터페이스 - @FunctionalInterface
- 함수형 인터페이스에는 하나의 추상 메서드만 정의되어 있어야 한다
( 람다식과 추상 메서드의 1:1 연결을 위해 )
단, static 메서드와 default 메서드의 개수에는 제약 X - 람다식을 이용하면 interface의 메서드를 아래와 같이 간단히 구현 가능
( Comparator interface엔 추상 메서드가 ' compare() ' 메서드 하나만 정의되어 있다 )
List<String> list = Arrays.asList("abc", "aaa", "bbb", "ddd", "aaa");
Collections.sort(list, new Comparator<String>() { // 매개변수로 전달할 익명 객체를 생성하고
// 익명 클래스로 Comparator interface의 추상 메서드 구현
public int compare(String s1, String s2) {
retrun s2.compartTo(s1);
}
);𐰸 𐰸 ( 간단히 구현 )
List<String> list = Arrays.asList("abc", "aaa", "bbb", "ddd", "aaa");
/*
Comparator f = new Comparator<String>() {
public int compare(String s1, String s2) {
retrun s2.compartTo(s1);
}
}
*/
// 위처럼 생성한 익명 객체를 람다식으로 대체하고, 람다식을 참조변수로 다룬다
// Compartor f = (s1, s2) -> s2.compareTo(s1);
// Collecitons.sort(list, f);
// 위의 두 줄의 코드를 한 줄로 줄인 코드
Collections.sort(list, (s1, s2) -> s2.compareTo(s1));
🔻 결국 람다식을 참조변수로 다룬다는 것
➜ 메서드를 통해 람다식을 주고받을 수 있다는 의미, 즉 메서드를 변수처럼 주고받는 것이 가능
➜ 사실은 메서드가 아니라 객체(익명 객체 ➟ 람다식)를 주고받는 것이긴 하다
🔹 함수형 인터페이스 타입의 매개변수와 반환타입
- 아래와 같은 함수형 인터페이스 MyFunction이 있다
@FunctionalInterface
interface MyFunction {
void myMethod();
}
- 어떠한 메서드의 매개변수가 함수형 인터페이스인 MyFunction 타입이다?
➜ 해당 메서드(' aMethod ')의 매개변수는 람다식을 참조하는 참조변수로 지정해야 한다는 의미 !
void aMethod(MyFunction f) {
f.myMethod();
}
// aMethod 메서드 호출
MyFunction f = () -> System.out.println("myMethod()");
aMethod(f);
🔻 참조변수 없이 아래처럼 직접 람다식을 매개변수로 지정하는 것도 가능
aMethod(() -> System.out.println("myMethod()"));
- 메서드의 반환타입이 함수형 인터페이스 타입인 경우
➜ 해당 함수형 인터페이스의 추상 메서드와 동등한 (1)람다식을 가리키는 참조변수를 반환 or (2)람다식을 직접 반환
MyFunction myMethod() {
// (1)
MyFunction f = () -> {};
return f;
// (2)
// return () - {};
}
✔️ 람다식의 타입과 형변환
🔹 람다식의 타입 ≠ 함수형 인터페이스의 타입
- 함수형 인터페이스 타입의 참조변수로 람다식을 참조할 수 있는 것일 뿐, 타입이 같다는 착각 X
( 람다식은 익명 객체이지만, 사실 익명 객체도 타입이 있긴 하다. 컴파일러가 임의로 정해 알 수 없는 것일 뿐 )
➜ 아래처럼 형변환이 필요한 이유
// 'interface MyFunction { void method(); }'가 정의되었다고 가정
MyFunction f = (MyFunction) (() -> {}); // 형변환 생략 가능
- 람다식은 오직 함수형 인터페이스로만 형변환 가능
➜ 람다식도 객체이지만, Object class 타입으로는 형변환 불가능
➜ 굳이 하고 싶다면? 아래처럼 함수형 인터페이스 타입으로 먼저 형변환을 해줘야 한다
Object obj = (Object)(MyFunction)(() -> {});
String str = ((Object)(MyFunction)(() -> {})).toString();
✔️ 외부 변수를 참조하는 람다식
🔹 람다식도 익명 객체처럼 외부 변수에 접근 가능
- 람다식도 익명객체, 즉 익명 클래스의 instance이므로 익명 클래스에서의 규칙과 동일한 규칙에 따라 외부에 선언된 변수에 접근 가능하다
- 람다식 내에서 참조하는 지역변수(메서드 영역)는 ' final ' 이 붙지 않아도 상수로 간주한다
- 하지만, instance 변수는 람다식 내에서 참조하고 있어도 변경을 허용한다
@FunctionalInterface
interface MyFunction {
void myMethod();
}
class Outer {
int val = 10; // Outer.this.val
class Inner {
int val = 20; // this.val
void method(int i) { // void method(final int i) {
int val = 30; // final int val = 30;
// i = 10; // Error.. 상수이기 때문에 변경 X
MyFunction f = () -> {
System.out.println(i);
System.out.println(val);
System.out.println(++this.val); // 변경 OK
System.out.println(++Outer.this.val); // 변경 OK
};
f.myMethod();
}
}
}
- 지역변수와 같은 이름의 람다식 매개변수는 허용 X
MyFunction f = (i) -> { // Error
✔️ java.util.function package
🔹 java.util.function package에 미리 정의되어 있는 함수형 인터페이스 ?
- 대부분의 메서드는 타입이 비슷하기 때문에 미리 정의하여 사용해도 문제 X
- 매번 새로운 함수형 인터페이스를 정의 X
➜ 이 패키지에 정의되어 있는 함수형 인터페이스를 활용하자
( 메서드 이름 통일, 재사용성과 유지보수성 증가 )
🔹 자주 쓰이는 가장 기본적인 함수형 인터페이스
java.lang.Runnable
- void run()
Supplier<T>
- T get()
Consumer<T>
- void accept(T t)
Function<T, R>
- 일반적인 함수
- R apply(T t)
Predicate<T>
- 조건식을 람다식으로 표현하는데 사용
- boolean test(T t)
- Predicate는 Function의 변형으로, 반환타입이 boolean이라는 것만 다르다
Predicate<String> isEmptyStr = s -> s.length() == 0;
String s = "";
if(isEmptyStrt.test(s))
System.out.println("This is an empty String.");
- 사용 예제 코드
public static void main(String[] args) {
Function<Integer, Integer> f = i -> i/10*10; // i의 일의 자리 제거
List<Integer> list = new ArrayList>();
// list에 값을 넣어주는 코드 생략
List<Intger> newList = doSomething(f, list);
System.out.println(newList);
}
static <T> List<T> doSomething(Function<T, T> f, List<T> list) {
List<T> newList = new ArrayList<T>(list.size());
for(T i : list) {
newList.add(f.apply(i));
}
return newList;
}
🔹 매개변수가 두 개인 함수형 인터페이스 - 접두사 'Bi'가 붙는다
BiConsumer<T, U>
- void accept(T t, U u)
BiPredicate<T, U>
- boolean test(T t, U u)
BiFunction<T, U, R>
- R apply(T t, U u)
- 이 이상의 매개변수를 갖는 함수형 인터페이스가 필요하다면 직접 만들어야 한다
🔹 UnaryOperator & BinaryOperator (Function의 또다른 변형)
UnaryOperator<T>
- Function의 자손 interface
- T apply(T t)
BinaryOperator <T>
- BiFunction의 자손 interface
- T apply(T t, T t)
🔹 컬렉션 프레임워크 & 함수형 인터페이스
Collection
- 조건에 맞는 요소를 삭제
- void replaceAll(Predicate<E> filter)
List
- 모든 요소를 변환하여 대체
- void replaceAll(UnaryOperator<E> operator)
Iterable
- 모든 요소에 작업 action을 수행
- void forEach(Consumer<T> action)
Map
- V compute(K key, BiFunction<K, V, V> f) ➜ 지정된 키의 값에 작업 f 수행
- V computIfAbsent(K key, Function<K, V> f) ➜ 키가 없으면 작업 f 수행 후 추가
- V computeIfPresent(K key, BiFunction<K, V, V> f) ➜ 지정된 키가 있을 때, 작업 f 수행
- V merge(K key, V value, BiFunction<V, V, V> f) ➜ 모든 요소에 병합작업 f 수행
- void forEach(BiConsumer<K, V> action) ➜ 모든 요소에 작업 action 수행
- void replaceAll(BiFunction<K, V, V> f) ➜ 모든 요소에 치환작업 f 수행
- 사용 예제 코드
// map의 모든 요소를 {k, v}의 형식으로 출력
map.forEach((k, v) -> System.out.print("{" + k + ", " + v + "}"));
🔹 기본형을 사용하는 함수형 인터페이스
DoubleToIntFunction
- AToBFunction ➜ 입력이 A타입, 출력이 B타입
- int applyAsInt(double d)
ToIntFunction<T>
- ToBFuntion ➜ 입력은 지네릭 타입, 출력이 B타입
- int applyAsInt(T value)
IntFunction<R>
- AFunction ➜ 입력은 A타입, 출력은 지네릭 타입
- R apply(T t, U u)
ObjIntConsumer<T>
- ObjAFUnction ➜ 입력은 T, A타입이고, 출력은 없다
- void accept(T t, U u)
- 사용 코드 예제
public static void main(String[] args) {
IntUnaryOperator op = i -> i/10*10; // i의 일의 자리 제거
int[] arr = new int[10];
// arr에 값을 넣어주는 코드 생략
int[] newArr = doSomething(op, arr);
System.out.println(newArr);
}
static int[] doSomething(IntUnaryOperator op, int[] arr) {
int[] newArr = new int[arr.length];
for(int i = 0; i < newArr.length; i++) {
newList[i] = op.applyAsInt(arr[i]); // apply()가 아님에 주의
}
return newArr;
}
🔻 아래처럼 IntUnaryOperator가 아닌 Function을 사용할 경우 에러 발생
Function f = (i) -> i/10*10;𐰸 𐰸 ( 매개변수 i와 반환타입을 지정해주면 OK )
// 매개변수 타입은 Integer, 반환타입은 Integer
Function<Integer, Integer> f = (i) -> i/10*10;
// 매개변수 타입은 int, 반환타입은 Integer
// IntFunction<Integer> f = (i) -> i/10*10;
🔻근데 왜 IntToIntFuction(AToBFunction ➜ 입력은 A타입, 출력은 B타입)은 없을까?
➜ UnaryOperator가 그 역할을 하기 때문이다 !
➜ 매개변수의 타입과 반환타입이 일치할 때는 "사용 코드 예제"처럼 Function 대신 UnaryOperator를 사용하는 것이 좋다
✔️ 람다식 합성
🔹 람다식 합성 ?
- 수학에서 두 함수를 합성해서 하나의 새로운 함수를 만들어내듯이,
두 람다식을 합성해서 새로운 람다식을 만들 수 있다 - Function의 합성과 Predicate의 결합을 통해 람다식의 합성에 대해 알아보자
🔹 Function의 합성 & Predicate의 결합
- java.util.function 패키지의 함수형 인터페이스에는 추상메서드 외에도 default 메서드와 static 메서드가 정의되어 있다
( 함수형 인터페이스에선 defaut 메서드와 static 메서드의 개수엔 제약 X ) - 함수형 인터페이스의 메서드들은 대부분 유사하기 때문에, Function과 Predicate interface에 정의된 메서드만 살펴봐도 응용 가능하다
🔹 Function의 합성
- Function interface에 정의되어 있는 메서드 (default, static)
- default <V> Function<T, V> andThen(Function<? super R, ? extends V> after)
- default <V> Function<V, R> compose(Function<? super V, ? extends T> before)
- static <T> Function<T, T> identity()
( Function interface는 반드시 두 개의 타입을 지정해줘야 해서 타입이 같아도 Function<T>가 아닌 Function<T, T> 라 써야 한다 )
- 두 Function의 합성은 어느 함수를 먼저 적용하느냐에 따라 달라진다
함수 f, g가 있을 때,
- f.andThen(g) ➜ 함수 f를 먼저 적용한 다음, 함수 g를 적용
- f.compose(g) ➜ 반대로 적용
andThen()
- default <V> Function<T, V> andThen(Function<? super R, ? extends V> after)
Function<String, Integer> f = (s) -> Integer.parseInt(s, 16); // 함수 f : 문자열 ➜ 숫자
Function<Integer, String> g = (i) -> Integer.toBinaryString(i); // 함수 s : 숫자 ➜ 문자열
Function<String, String> h = f.andThen(g);
System.out.println(h.apply("FF")); // "FF" -> 255 -> "1111111"
compose()
- default <V> Function<V, R> compose(Function<? super V, ? extends T> before)
Function<Integer, String> f = (i) -> Integer.toBinaryString(i); // 함수 f : 숫자 ➜ 문자열
Function<String, Integer> s = (s) -> Integer.parseInt(s, 16); // 함수 s : 문자열 ➜ 숫자
Function<String, String> h = f.compose(g);
System.outprintln(h.apply(2)); // 2 -> "10" -> 16
identity()
- static <T> Function<T, T> identity()
- 쉽게 말하면, 항등 함수( f(x) = x )이다
( map()으로 변환작업할 때처럼, 변함없이 그대로 처리하고자 할 때 사용 )
Function<String, String> f = x -> x;
// Function<String, String> f = Function.idenetity(); // 위와 동일
System.out.println(f.apply("AAA"));AAA
🔹 Predicate의 결합
- Predicate interface에 정의되어 있는 메서드 (static, default)
- default Predicate<T> and(Predicate<? super T> other)
- default Predicate<T> or(Predicate<? super T> other)
- default Predicate<T> negate()
(Predicate의 끝에 붙이면 조건식 전체가 부정이 된다) - static <T> Predicate<T> isEqual(Object targetRef)
- 여러 조건식을 논리연산자(&&, ||, !)으로 연결해서 하나의 식을 구성하는 것처럼,
' and() ', ' or() ', ' negate() '로 연결해서 하나의 새로운 Predicate로 결합
Predicate<Integer> p = i -> i < 100;
Predicate<Integer> q = i -> i < 200;
Predicate<Integer> r = i -> i i%2 == 0;
Predicate<Integer> notP = p.negate(); // i >= 100
Predicate<Integer> all = notP.and(q.or(r)); // 100 <= i && (i < 200 || i%2 == 0)
// 람다식을 직접 넣어도 된다
Predicate<Integer> all = notP.and(i -> i < 200).or(i -> i%2 == 0);
isEqual
- 두 대상을 비교하는 Predicate를 만들 때 사용
2개의 매개변수 (2개의 비교대상) ➜ (1) isEqual() (2) test()
// Predicate<String> p = Predicate.isEqual(str1);
// boolean result = p.test(str2); // str1과 str2가 같은지 비교하여 결과를 반환
boolean result = Predicate.isEqual(str1).test(str2)
✔️ 람다식을 더 간결하게 표현하는 방법
🔹 메서드 참조
- 람다식이 하나의 메서드만 호출하는 경우에 가능
- 람다식을 static 변수처럼 다룰 수 있게 해준다
1. static메서드 혹은 instance메서드를 참조하는 방법
➜ ' 클래스이름::메서드이름 ' or ' 참조변수::메서드이름 '
BiFunction<String, String, Boolean> f = (s1, s2) -> s1.equals(s2);
/* 이 람다식을 메서드로 표현하면
String isSame(St s) { // 메서드 이름은 의미 X
return s1.equals(s2);
}
*/𐰸 𐰸 ( isSame() 메서드는 사실 하는 일이 X ➜ 'String.equals()'를 직접 호출하자 )
BiFunction<String, String, Boolean> f = String::equals; // 메서드 참조🔻 생략된 부분은 컴파일러가 알아낼 수 있다
( (1)좌변의 Function interface에 지정된 지네릭 타입과 (2)parseInt 메서드의 선언부로부터 )
➜ (1)String 타입인 두 개의 매개변수를 받고, (2)Boolean 타입의 결과값을 반환하는구나
2. 특정 객체의 instance메서드 참조
- 이미 생성된 객체의 메서드를 람다식에서 사용하는 경우
➜ class 이름 대신 그 객체의 참조변수를 적어줘야 한다
MyClass obj = new MyClass();
Function<String, Boolean> f = (x) -> obj.equals(x); // 람다식
Function<String, Boolean> f2 = obj::equals; // 메서드 참조3. 생성자의 메서드 참조
- 생성자를 호출하는 람다식도 메서드 참조로 변환할 수 있다
Supplier<MyClass> s = () -> new MyClass(); // 람다식
Supplier<MyClass> s = MyClass::new; // 메서드 참조
- 매개변수가 있는 생성자라면?
➜ 생성자의 매개변수의 개수에 따라 알맞은 함수형 인터페이스를 써주거나, 알맞은 인터페이스가 없다면 새로운 함수형 인터페이스를 정의해줘야 한다
Function<Integer, MyClass> f = (i) -> new MyClass(i); // 람다식
Function<Integer, MyClass> f = MyClass::new; // 메서드 참조🔻 생성자의 매개변수가 1개이니까 그에 맞는 함수형 인터페이스인 Function을 사용
- 배열을 생성할 때엔?
Function<Integer, int[]> f = x -> new int[x]; // 람다식
Function<Integer, int[]> f2 = int[]::new; // 메서드 참조
🌒 스트림 (Stream)
✔️ 스트림 (Stream) ?
🔹 스트림 (Stream)
- 스트림(Stream)을 왜 만들었을까?
- 컬렉션이나 배열의 데이터를 for문과 Iterator로 다루는 것은 코드도 길어져 가독성이 떨어지며, 재사용성도 떨어진다
- 데이터 소스마다 다른 방식으로 다뤄야 한다
( ex. List를 정렬할 때는 ' Collections.sort() ' 를, 배열을 정렬할 때는 ' Arrays.sort() ' 를 사용해야 한다 )
- 다양한 데이터 소스(배열, 컬렉션, 파일, etc.)들을 모두 같은 방식으로 다룰 수 있다
➜ 배열과 List에 대한 Stream을 생성하고 같은 방식으로 정렬하는 과정
String[] array = {"a", "b", "c"};
List<String> list = Arrays.asList(arrays);
Stream<String> streamArray = Arrays.stream(array);
Stream<String> streamList = list.stream();
streamArray.sorted() // Arrays.sort(array)
streamList.sorted() // Collections.sort(list)
🔹 스트림의 특징
- 스트림은 데이터 소스를 변경하지 않는다
// 정렬된 결과를 List에 담아서 반환
List<String> sortedList = strList.sorted().collect(Collectors.toList());
- 스트림은 일회용이다
➜ Iterator처럼 스트림도 한 번 사용하면 닫혀서 사용할 수 없다
- 스트림은 작업을 내부 반복으로 처리한다
( 내부 반복이란, 반복문을 메서드 내부에 숨길 수 있다는 의미 )
/*
for(String str : strList)
System.out.println(str)
*/
stream.forEach(System.out::println);
✔️ 스트림(Stream)의 연산 ?
🔹 스트림 연산
- 스트림에 정의된 메서드 중에서 데이터 소스를 다루는 작업을 수행하는 것을 말한다
- 중간 연산
➜ 연산 결과(반환 값)이 스트림인 연산. 스트림에 연속해서 중간 연산할 수 있다 - 최종 연산
➜ 연산 결과(반환 값)이 스트림 X. 스트림의 요소를 소모하므로 단 한 번만 가능하다
- 중간 연산
- 스트림 연산 메서드
Stream (Java SE 20 & JDK 20) (oracle.com)
Stream (Java SE 20 & JDK 20)
Type Parameters: T - the type of the stream elements All Superinterfaces: AutoCloseable, BaseStream > A sequence of elements supporting sequential and parallel aggregate operations. The following example illustrates an aggregate operation using Stream and
docs.oracle.com
- 지연된 연산
➜ 스트림 연산에서 한 가지 중요한 점이 최종 연산이 수행되기 전까지는 중간 연산이 수행되지 않는다는 것, 즉 최종 연산이 수행되기 전까지 중간 연산은 지연된다는 것이다
( 중간 연산이 호출되는 것은 단지 어떤 작업을 수행해야지 지정해주는 것일 뿐 )
- 기본형을 다루는 스트림 (IntStream, LongStream, DoubleStream)
➜ 요소의 타입이 T인 스트림은 기본적으로 Stream<T>이지만, ' 오토박싱 & 언박싱 (Auto-boxing & Unboxing) ' 으로 인한 비효율을 줄이기 위해 데이터 소스의 요소를 기본형으로 다루는 스트림이 따로 제공된다
( ex. Stream<Integer> 대신 IntStream을 사용하는 것이 효율적 )
- 병렬 스트림
➜ 병렬 스트림은 내부적으로 fork&join Framework를 이용해 자동적으로 연산을 병렬로 수행하기 때문에 병렬 처리가 쉽다
int sum = strStream.parallel() // parallel() : strStream을 병렬 스트림으로 전환
.mapToInt(s -> s.length())
.sum();
// sequential() : parallel()을 호출한 것을 취소할 때만 사용 (병렬 작업 취소)
✔️ 스트림 생성
🔹 컬렉션 ➜ 스트림
- 컬렌션의 최고 조상인 Collection class에 ' stream() ' 이 이미 정의되어 있다
// 해당 컬렉션을 소스로 하는 스트림을 반환
Stream<T> Collection.stream()
- List로부터 스트림을 생성
List<Integer> list = Arrays.toList(1, 2, 3, 4, 5);
Stream<Integer> intStream = list.stream();
// forEach() 지정된 작업을 스트림의 모든 요소에 대해 수행
intStream.forEach(System.out::println);
intStream.forEach(System.out::println); // 최종 연산이기에 스트림이 이미 닫혀 Error 발생
🔹 배열 ➜ 스트림
- Stream과 Arrays class에 static 메서드로 정의되어 있다
Stream<T> Stream.of(T... values) // 가변 인자 (variable argument) : 매개 변수의 개수가 동적
Stream<T> Stream.of(T[])
Stream<T> Arrays.stream(T[])
Stream<T> Arrays.stream(T[] array, int startInclusive, int endExclusive)// 기본형 배열을 소스로 하는 스트림 생성 메서드
IntStream IntStream.of(int... value)
IntStream IntStream.of(int[])
IntStream Arrays.stream(int[])
IntStream Arrays.stream(int[] array, int startInclusive, int endExclusive)
- 문자열 배열 ➜ 스트림 / 기본형 배열 ➜ 스트림
// 문자열을 소스로 하는 스트림을 생성하는 바법
Stream<String> strStream = Stream.of("a", "b", "c"); // 가변 인자
// = Arrays.stream(new String[]){"a", "b", "c"});
// 기본형 배열(int[])을 소스로 하는 스트림을 생성하는 방법
IntStream intStream = IntStream.of(new int[]{1, 2, 3});
// = Arrays.stream(new int[]){1, 2, 3});
🔹 특정 범위의 정수 ➜ 스트림
- IntStream과 LongStream은 지정된 범위의 연속된 정수를 스트림으로 생성해서 반환하는 ' range() ', ' rangeClosed() ' 메서드를 갖고 있다
IntStream Stream = IntStream.range(1, 5); // 1, 2, 3, 4
IntStream Stream = IntStream.rangeClosed(1, 5); // 1, 2, 3, 4, 5➜ int보다 큰 범위의 스트림은 LongStream으로 생성
🔹 난수 ➜ 스트림
- Random class에는 난수로 이루어진 '무한 스트림'을 반환하는 인스턴스 메서드들이 있다
( ints(), longs(), doubles() )
➜ ' limit() ' 을 이용해 스트림의 크기를 제한해줘야 한다
IntStream intStream = new Random.ints().limit(5) // 5개의 랜덤 int
// 유한 스트림 생성, limit() 필요 X
// = new Random.ints(5, 1, 10) // [1, 10) 범위의 난수 5개를 가진 스트림 반환
// IntStream ints(int begin, int end)
// IntStream ints(long streamSize, int begin, int end)
🔹 람다식 ➜ 스트림
- ' iterate() ' 와 ' generate() ' 는 람다식을 매개변수로 받아서, 이 람다식에 의해 계산되는 값들을 요소로 하는 무한 스트림을 생성
static <T> Stream<T> iterate(T seed, UnaryOperator<T> f)
static <T> Stream<T> generate(Supplier<T> s) // 매개변수가 없는 람다식만 허용
1. ' iterate() ' 는 seed 값으로 지정된 값부터 람다식 f에 의해 계산된 결과를 다시 seed 값으로 해서 계산을 반복
Stream.iterate(0, n -> n + 2) // 0, 2, 4, 6 ...
2. ' generate() ' 는 ' iterate() ' 와 달리, 이전 결과를 이용해서 다음 요소 계산 X
// [0, 1)사이의 수(double)를 가진 무한 스트림
Stream<Double> randomStream = Stream.generate(Math::random)
- 단, ' iterate() ' 와 ' generate() ' 에 의해 생성된 스트림은 기본형(Primitive) 스트림 타입의 참조변수로 다룰 수 없다 !
( 굳이 필요하면, ' mapToInt() ' 같은 메서드로 변환을 해주면 된다 )
IntStream evenStream = Stream.iterate(0, n -> n + 2).mapToInt(Integer::valueOf);
Stream<Integer> stream = evenSteram.boxed(); // IntStream -> Stream<Integer>
🔹 파일 ➜ 스트림
- java.nio.file.Files에서 제공
list() : 지정된 디렉토리(dir)에 있는 파일의 목록을 소스로 하는 스트림을 생성하여 반환
Stream<Path> Files.list(Path dir)
lines() : 파일의 한 행(line)을 요소(행 단위)로 하는 스트림을 생성
( 파일 뿐만 아니라 다른 입력 대상으로부터도 읽어올 수 있다 )
// BufferedReadar class
Stream<String> Files.lines(Path path)
Stream<String> Files.lines(Path path, Charset cs)
Stream<String> lines()
🔹 빈 스트림
- 스트림에 연산을 수행한 결과 하나도 없을 때, null보다 빈 스트림을 반환하는 것이 좋다
Stream.empty(); // 빈 스트림을 생성해서 반환
emptyStream.count(); // 0; 스트림 내 요소의 개수를 반환
🔹 두 스트림의 연결
- Stream.conat() - 연결하려는 두 스트림의 요소는 같은 타입(ex. String)이어야 한다
Stream<String> stringStream = Stream.concat(strStream1, strStream2);
✔️ 스트림(Stream)의 중간 연산
🔹 스트림 자르기 - skip(), limit()
- Stream class에 정의된 skip(), limit()
Stream<T> skip(long n)
Stream<T> limit(long maxSize)
- 기본형 스트림 class(ex. IntStream)에도 skip(), limit이 정의돼 있다
➜ 반환 타입이 기본형 스트림 ( 매개변수의 타입은 똑같이 long )
// IntStream
intStream.skip(3) // 4번째 요소부터
.limit(5) // 5개로 제한 (4~8번째 요소)
🔹 스트림의 요소 필터링 - filter(), distinct()
Stream<T> distinct()
Stream<T> filter(Predicate<? super T> predicate)- distinct() : 중복된 요소 제거
- filter() : 주어진 조건(Predicate)에 맞지 않는 요소를 걸러낸다
➜ 매개변수로 Predicate 말고도 boolean 타입의 값을 반환하는 람다식도 사용 가능
➜ 다른 조건으로 ' filter() ' 를 여러 번 호출 가능
stream.distinct() // 중복제거
.filter(i -> i % 2 == 0) // 짝수만 남기기
🔹 스트림 정렬 - sorted()
- sorted()
Stream<T> sorted()
Stream<T> sorted(Comparator<? super T> comparator)
➜ Comparator나 int 값을 반환하는 람다식으로 정렬 기준을 지정하여 정렬한다
➜ 별도로 지정해주지 않으면, 요소의 ' 기본 정렬 기준(Comparble) ' 으로 정렬
( 단, 스트림의 요소가 Comparable을 구현한 class(ex. String)가 아니면 예외 발생 )
// 문자열 스트림을 String에 정의된 기본 정렬(사전순)로 정렬 후 출력
Stream<String> strStream = Stream.of("dd", "aaa", "CC", "cc", "b");
strStream.sorted().forEach(System.out::print); // CCaaabccdd
- Comparator interface에 있는 static, default 메서드들을 활용하여 정렬을 쉽게 하자 !
comparing()
(1) 스트림의 요소가 Comparable을 구현한 경우 기본 정렬 기준으로 정렬
(2) 그렇지 않았다면, 추가적인 매개변수로 ' 정렬 기준 (Comparator) '을 따로 지정해줘야 한다
( 비교대상이 기본형(Primitive)인 경우, ' comparingInt() ' 와 같은 메서드를 사용해서 효율적(Auto-boxing & Unboxing 하여 따로 변환해줄 필요 X)으로 정렬하자 )
thenComparing() : 정렬 조건을 추가할 때 사용
thenComparing(Comparator<T> other)
thenComparing(Function<T, U> keyExtractor) // T (입력) ➜ U (출력)
thenComparing(Function<T, U> keyExtractor, Comparator<U> keyComp)
// 학생의 성적을 반별 오름차순, 성적별 내림차순으로 정렬하여 출력
// main메서드
// studentStream : Student class의 instance들을 담은 스트림의 참조변수
// Stream<Student> studentStream = Stream of(
new Student("신민규", 1, 900),
...
);
studentStream.sorted(Comparator.comparing(Student::getBan) // 반별 정렬
.thenComparing(Comparator.naturalOrder()) // (1) 기본 정렬 (성적별 내림차순)
// .thenComparing(Student::getTotalScore, (a, b) -> b - a) // (2)
.forEach(System.out::println);
// Student class : (1) Comparable을 구현
class Student {
String name;
int ban;
int totalScore;
...
// 성적별 내림차순을 기본 정렬 기준으로 한다
public int compareTo(Student s) {
return s.totalScore - this.totalScore;
}
}
( Comparator의 메서드 참고 )
Comparator (Java SE 20 & JDK 20) (oracle.com)
Comparator (Java SE 20 & JDK 20)
Type Parameters: T - the type of objects that may be compared by this comparator All Known Implementing Classes: Collator, RuleBasedCollator Functional Interface: This is a functional interface and can therefore be used as the assignment target for a lambd
docs.oracle.com
( Comparable과 Comparator 차이 관련 내용 참고 )
[JAVA] 컬렉션 프레임웍 ( Collections Framework ) — Uykm_Note (tistory.com)
[JAVA] 컬렉션 프레임웍 ( Collections Framework )
🌑 컬렉션 프레임웍 (Collections Framework) ✔️ Collections Framework의 핵심 interface 🔸 Vector · Hashtable과 같은 기존의 Collections class들 대신 ArrayList · HashMap 을 사용하자 기존의 Collections class들은 호환을
ukym-tistory.tistory.com
🔹 변환 - map()
- 스트림 요소에서 원하는 필드만 뽑아내거나 특정 형태로 변환해야 할 때 사용 !
- ' filter ' 처럼 하나의 스트림에 여러 번 적용 가능
Stream<R> map(Function<? superT, ? extends R> mapper)
// studentStream.map(Student::getName); // 아래와 같은 동작
studentStream.map(s -> s.getName()); // Stream<Student> => Stream<String>
.map(String::toUpperCase) // 모두 대문자로 변환
🔹 조회 - peek()
- ' forEach() - 최종 연산 ' 와 달리 요소를 소모하지 않고 요소를 조회
➜ 중간 연산에 대한 결과를 확인하는 용도로 사용
studentStream.map(s -> s.getName())
.peek(System.out::println) // 이렇게 중간 연산결과 확인 가능
// .peek(s -> System.out.println(s))
🔹 mapToInt(), mapToLong(), mapToDouble()
- ' map() ' 은 연산 결과로 Stream<T> 타입의 스트림을 반환하는데,
타입 T가 기본형일 경우엔 애초부터 ' mapToA() ' 를 사용해 기본형 스트림으로 변환하여 반환하자
IntStream mapToInt(ToIntFunction<? super T> mapper) // ToAFunction<? super T> : T (입력) ➜ A (출력)
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper)
LongStream mapToLong(ToLongFunction<? super T> mapper)
studentStream.map(Student::getTotalScore) // Stream<Integer> 반환
studentStream.mapToInt(Student::getTotalScore) // IntStream 반환
- ' mapToA() ' 의 장점은 ?
- Auto-boxing & Unboxing을 할 필요가 없어서 효율적이다
- ' count() ' 만 지원하는 Stream<T>와 달리 IntStream과 같은 기본형(Primitive) 스트림은 숫자를 다루는데 편리한 메서드들을 제공한다
- Auto-boxing & Unboxing을 할 필요가 없어서 효율적이다
최종 연산 메서드 ( Stream에 있는 ' max() ' 와 ' min() ' 은 매개변수로 Comparator를 지정해야 한다 )
int sum() // 스트림의 모든 요소의 총합
OptionalDouble average() // sum() / (double)count()
OptionalInt max() // 스트림 요소중 제일 큰 값
OptionalInt min() // 스트림 요소 중 제일 작은 값
➜ 최종 연산이기 때문에, ' summaryStatistics() ' 메서드 제공
// LongStream, DoubleStream도 아래와 같은 연산 메서드 제공
IntSummaryStatistics stat = studentStream.mapToInt(Student::getTotalScore)
.summaryStatistics();
long totalCount = stat.getCount();
long totalScore = stat.getSum();
double avgScore = stat.getAverage();
int minScore = stat.getMin();
int maxScore = stat.getMax();
int totalScore = students.mapToInt(Student::getTotalScore)
.sum(); // 이렇게 따로도 가능
OptionalDouble average = students.mapToInt(Student::getTotalScore)
.average(); // 평균이 0인 경우도 있을 수 있다🔻 스트림의 요소가 하나도 없을 때엔 count()나 sum()은 0을 반환하면 되지만, 다른 연산 메서드들은 그럴 수 없다
➜ 그래서 OptionalDouble을 반환하는 것 ( Optional class들에 대해선 뒤에 정리 )
- ' mapToInt() ' 와 함께 자주 사용되는 메서드
- Integer::parseInt()
➜ 파라미터로 받은 문자열(String)을 정수 값(int)으로 파싱(=변환) 후 반환 - Integer::intValue()
➜ 파라미터로 받은 Integer 타입 객체를 기본형 타입(int)인 정수 값으로 반환 - Integer::valueOf()
➜ 파라미터로 받은 문자열(String)이나 정수 값(int)을 Wrapper 클래스 타입(Integer)의 객체로 변환 후 반환
ex) new Integer(Integer.parseInt("127")); ➜ 반환값
- Integer::parseInt()
mapToInt(Integer::parseInt) // Stream<String> ➜ IntStream
mapToInt(Integer::intValue) // Stream<Integer> ➜ IntStream
mapToInt(Integer::valueOf) // Stream<Integer> ➜ IntStream (Error)🔻 'mapToInt(Integer::valueOf)' 를 사용할 때 에러가 발생하는 이유 ?
➜ mapToInt()는 기본형 타입으로 매핑(변환)하여 기본형 스트림으로 반환해주는 메서드인데, valueOf()는 문자열이나 기본형 값을 객체로 변환(Boxing)시켜주는 것이라 충돌이 발생하기 때문이다 !
- 반대로 기본형(Primitive) 스트림을 Stream<T>로 변환할 때 ➜ mapToObj()
기본형(Primitive) 스트림을 Stream<Primitive Type>로 변환할 때 ➜ boxed()
🔹 flatMap() - Steam<T[]> ➜ Stream<T>
- 스트림의 요소가 배열이거나 ' map() ' 으로 변환된 스트림의 요소가 배열인 경우,
즉 스트림의 타입이 Stream<T[]>인 경우, Stream<T>로 다루는 것이 편리할 때가 있다
➜ 이때 ' flatMap() ' 사용
String[] lines = {
"I am hungry",
"I want a Chicken!"
}
// "I" "am" "hungry" "I" "want" "a" "Chicken!" 와 같은 스트림을 원한다
Stream<String> linesStream = Arrays.stream(lines); // "I am hungry", "I want a Chicken!"
Stream<String[]> arraysStream = linesStream.map(line -> line.split(" ")); // (1)
// ["I", "am", "hungry"], ["I", "want", "a", "Chicken!"]
// 스트림 안에 스트림이 있는 형태
Stream<Stream<String>> wrongStream = arraysStream.map(s -> Arrays.stream(s)); // (2)
// = arraysStream.map(Arrays::stream);
// 아래줄은 (1), (2) 코드를 압축한 코드
// = linesStream.map(line -> Stream.of(line.split(" ")))
// 원하는 형태의 스트림으로 변환
Stream<String> correctStream = arraysStream.flatMap(s -> Arrays.stream(s)); // (3)
// = arraysStream.flatMap(Arrays::stream);
// 아래줄은 (1), (3) 코드를 압축한 코드
// = linesStream.map(line -> Stream.of(line.split(" ")))
- Stream<Stream<T>> ➜ Stream<T>
: 드물지만, 스트림을 요소로 하는 스트림을 하나의 스트림으로 합칠 때도 사용
Stream<String> oneStream = wrongStream.flatMap(s -> Arrays.stream(s))
// = wrongStream.flatMap(Arrays::stream)
✔️ Optional<T> & OptionalInt
🔹 Optional<T> ?
- Optional<T>는 지네릭 클래스로 'T타입의 객체'를 감싸는 Wrapper class이다
➜ Optional 타입의 객체에는 모든 타입의 참조변수를 담을 수 있다 - 최종 연산의 결과는 그냥 반환하는 것보다 Optional 객체에 담아서 반환하자
➜ if문 없이도 Optional class의 메서드를 이용해 반환된 결과가 null이 아닌지 간단히 체크할 수 있다
( NullPointerException이 방지 )
public final class Optional<T> {
private final T value; // T 타입의 참조변수
...
}
Optional (Java SE 10 & JDK 10 ) (oracle.com)
Optional (Java SE 10 & JDK 10 )
If a value is present, returns the result of applying the given Optional-bearing mapping function to the value, otherwise returns an empty Optional. This method is similar to map(Function), but the mapping function is one whose result is already an Optiona
docs.oracle.com
🔹 Optional 객체 생성
- 매개변수로 받을 참조변수의 값이 null일 가능성이 있다면, of 대신 ofNullable() 사용 !
( of() : 매개변수의 값이 null이면 NPE 발생 )
String object = "string";
Optional<String> optional = Optional.of(object);
// = Optional.of("string");
// = Optional.of(new String(string))'
Optional<String> optional = Optional.ofNullable(object);
- Optional<>타입의 참조변수 초기화
- null로 초기화
- ' empty() ' 로 초기화
Optional<String> optVal = null;
Optional<String> optVal = Optional<String>.empty(); // 빈 객체로 초기화 (지향)
🔹 Optional 객체의 값 가져오기
T orElseGet(Supplier<? extends T> other)
T orElseThrow(Supplier<? extends X> exceptionSupplier) // 람다식을 매개변수로 제공 가능
String s = optional.get(); // 만약 value가 null이면 NoSuchElementException 예외 발생
String s = optional.orElse(""); // value == null ? "": value
String s = optional.orElseGet(String::new); // () -> new String()
String s = optional.orElseThrow(NullPointException::new); // () -> new NullPointException
- Optional 객체도 ' filter() ', ' map() ', ' flatMap() ' 사용 가능
➜ Optional 객체의 값이 null이면, 이 메서드들은 아무 작업도 수행 X
int result Optional.of("531")
.filter(x -> x.length > 0)
.map(Integer::parseInt)
.orElse(-1); // result = 531
int result Optional.of("")
.filter(x -> x.length > 0) // null이 된다
.map(Integer::parseInt) // 아무 작업도 수행 X
.orElse(-1); // result = -1
- isPresent() - Optional 객체의 값이 null이면 false, 아니면 true 반환
➜ Optional<T>를 반환하는 최종 연산과 잘 어울린다
( Optional<T>를 반환하는 최종 연산은 몇 개 없다 )
ex. findAny(), findFirst(), max(Comparator<? super T> comparator), min(Comparator comparator), reduce(BinaryOperator<T> accumulator)
Boolean isPresent(Consumer<T> block) // 람다식을 매개변수에 제공 가능
if(Optional.ofNullable(object).isPresent()) { // if(object != null) {
System.out.println(object);
}
// 이처럼 간단히 바꿀 수 있다
Optional.ofNullable(object).isPresent(() -> System.out.println(object));
🔹 OptionalInt, OptionalLong, OptionalDouble
- IntStream과 같은 기본형 스트림은 Optional도 기본형을 값으로 하는 OptionalInt, OptionalLong, OptionalDouble을 반환 !
( 반환 타입이 Optional<T>가 아니라는 것을 제외하고는 Stream에 정의된 것과 유사하다 )
ex. OptionalDouble average()
| Optional class | 값을 반환하는 메서드 | 설명 |
| Optional<T> | T get() | Optinal 객체에 저장된 값을 가져온다 |
| OptionalA | getAsA | A자리 - Int, Long, Double 반환 값의 타입은 A |
- OptionalInt 객체에 저장된 값이 없는 것과 0이 저장된 것은 구분 가능하다
( Optional 객체의 경우 null을 저장하면 비어있는 것과 동일하게 취급 )
OptionalInt opt = OptionalInt.of(0); // OptionalInt에 0을 저장
OptionalInt opt2 = OptionalInt.empty(); // int의 기본값은 0이므로 빈 객체(OptionalInt.empty())에 저장되는 값은 0이다
Optional opt3 = Optional.ofNullable(null);
Optional opt4 = Optional.empty();
opt.equals(opt2); // false
opt3.equals(op4); // true
// OptionalInt class
public final class OptionalInt {
...
private final boolean isPresent; // 값이 저장돼 있으면 true
private final int value; // int 타입의 변수
...
}
✔️ 스트림의 최종 연산
🔹 forEach()
- peek()과 달리 스트림의 요소를 소모하는 최종 연산
void forEach(Consumer<? super T> action) // 람다식 사용 가능
🔹 조건 검사 - allMatch(), anyMatch(), noneMatch(), findFirst(), findAny()
- 스트림 요소에 대해 지정된 조건에 모든 요소가 일치(allMatch)하는지, 일부가 일치(anyMatch)하는지, 어떤 요소도 일치하지 않는지(findAny) 확인하는 데 사용하는 메서드
➜ 모두 매개변수로 Predicate를 요구하며, 반환 타입은 boolean이다
// 총점이 100 이하인 학생이 있는지 확인
stuStream.anyMatch(s -> s.getTotalScore() <= 100)
- findFirst() ➜ 스트림의 요소 중에서 조건에 일치하는 첫 번째 것을 반환 ( 주로 ' filter() ' 와 함께 사용 )
- findAny() ➜ 병렬 스트림의 경우 findFirst() 대신에 사용
( 스트림의 요소가 없을 때는 비어있는 Optional 객체를 반환 )
Optional<Student> stu = stuStream.filter(s -> s.getTotalScore() <= 100).findFirst();
Optional<Student> stu = parallelStream.filter(s -> s.getTotalScore() <= 100).findAny();
🔹 통계 정보 얻기 - count(), sum(), average(), max(), min()
- IntStream과 같은 기본형 스트림이 아닌 경우엔 통계와 관련된 메서드는 3개밖에 없다 ( 잘 사용 X )
➜ 대부분 기본형 스트림으로 변환하거나, ' reduce() ' 나 ' collect() ' 를 사용해서 통계 정보를 얻는다
long count()
Optional<T> max(Comparator<? super T> comparator)
Optional<T> min(Comparator<? super T> comparator)
🔹 리듀싱 - reduce()
- 스트림의 요소를 줄어나가면서 연산을 수행하고 최종결과를 반환
➜ 매개변수의 타입이 BinaryOperator<T>인 이유 ( 처음 두 요소를 가지고 연산한 결과 + 다음 요소 .. )
➜ 초기값(identity)과 어떤 연산(BinaryOperator)으로 스트림의 요소를 줄여나갈 것인지 생각하며 사용하면 된다
Optional<T> reduce(BinaryOperator<T> accumulator)
T reduce(Tidentity, BinaryOperator<T> accumulator)
// combiner는 병렬 스트림에 의해 처리된 결과를 합칠 때 사용하는 매개변수
U reduce(U identity, BiFunction<U, T, U. accumulator, BinaryOperator<U> combiner)
- ' max() ' 와 ' min() ' 의 경우, 초기값이 필요없어 Optimal<T>를 반환하는 매개변수 하나짜리 ' reduce() ' 를 사용하자
// 반환 타입 T (int)
int count = intStream.reduce(0, (a, b) -> a + 1);
int sum = intStream.reduce(0, (a, b) -> a + b);
// 반환 타입 : OptionalInt
OptionalInt max = intStream.reduce((a, b) -> a > b ? a : b); // intStream.reduce(Integer::max)
OptionalInt max = intStream.reduce((a, b) -> a < b ? a : b); // intStream.reduce(Integer::min)
✔️ collect()
🔹 collect() ?
- 스트림의 요소를 수집하는 최종 연산 중 하나이다
➜ 어떻게 수집할 것인가에 대한 방법을 정의한 것이 컬렉터(Collector) 인터페이스
Collectors class
- Collector interface를 구현한 class
- 다양한 종류의 컬렉터를 반환하는 static 메서드를 갖고 있다 )
- ' collect() ' 는 매개변수의 타입이 Collector이다
➜ 매개변수가 Collector interface를 구현한 class의 객체이어야 한다는 의미
( sort()할 때, Comparator가 필요한 느낌 )
Object collect(Collector collector)
Object collect(Supplier supplier, BiConsumer accumulator, BiConsumer combiner)
➜ 매개변수가 3개인 ' collect() ' 는 간단히 람다식으로 수집할 때 사용하기 편리하다
🔹 스트림 ➜ 컬렌션 or 배열
- toList(), toSet(), toMap(), toCollection(), toArray()
- List나 Set이 아닌 특정 컬렉션을 지정하고 싶을 땐,
' toCollection() 에 해당 컬렉션의 생성자 참조를 매개변수로 넣어주면 된다
List<String> names = studentStream.map(s -> s.getName())
.collect(Collectors.toList());
ArrayList<String> list = names.stream()
.collect(toCollection(ArrayList::new));
- Map은 객체의 어떤 필드를 키와 값으로 사용할지 지정해주면 된다
// 요소의 타입이 Person인 스트림에서 사람의 이름을 key로, Person의 객체를 value로 저장
Map<String, Student> map = personStream.collect(Collectors.toMap(p -> p.getName(), p -> p));🔻 항등 함수를 의미하는 ' p -> p ' 대신 Function.identity() 사용 가능
- 스트림에 저장된 요소들을 ' T[] ' 타입의 배열로 변환
➜ ' toArray() ' 사용
( 단, 해당 타입(Student)의 생성자 참조를 매개변수로 지정해줘야 한다 )
Student[] studentNames = studentStream.toArray(Student::new));
Student[] studentNames = studentStream.toArray(); // Error
Object[] studentNames = studentStream.toArray(); // OK : 지정하지 않으면 'Object[]' 타입으로 반환
🔹 통계 정보 얻기
- counting(), summingA(), averagingA(), maxBy(), minBy()
- A에는 Int, Long, Double이 올 수 있다
- 다른 최종 연산들이 제공하는 통계 정보와 다를 것 없이 똑같다
➜ ' groupingBy() ' 와 함께 사용할 때 필요
// Collectors의 static 메서드를 호출할 때는 'Collectors.'를 생략했다
long count = stuStream.count();
long count = stuStream.collect(counting()); // Collectors. counting()
long totalScore = stuStream.mapToInt(Student::getTotalScore).sum();
long totalScore = stuStream.Collect(summingInt(Student::getTotalScore());
OptionalInt topScore = stuStream.mapToInt(Student::getTotalScore)
.max();
Optional<Student> topStudent = stuStream
.max(Comparator.comparingInt(Student::getTotalScore));
Optional<Student> topStudent = stuStream
.collect(maxBy(Comparator.comparingInt(Student::getTotalScore)));
IntSummaryStatistics stat = stuStream
.mapToInt(Student::getTotalScore).summaryStatistics();
IntSummaryStatistics stat = stuStream
.collect(summarizingInt(Student::getTotalScore));
🔹 리듀싱 - reducing()
- IntStream에는 매개변수 3개짜리 ' collect() ' 만 정의되어 있어,
boxed를 통해 IntStream을 Stream<Integer>로 변환해야 매개변수 1개짜리 ' collect() ' 사용 가능
Collector reducing(BinaryOperator<T> op)
Collector reducing(T identity, BinaryOperator<T> op)
Collector reducing(U identity, Function<T, U> mapper, BinaryOperator<T> op)
long sum == intStream.reduce(0, (a, b) -> a + b);
int grandTotal = stuStream.map(Student::getTotalScore).reduce(0, Integer::sum);
// collect() 사용
long sum == intStream.boxed().collect(reducing(0, (a, b) -> a + b));
int grandTotal = stuStream.collect(reducing(0, Student::getTotalScore, Integer::sum)); // map() + reduce()
🔹 문자열 결합 - joining()
- 문자열 스트림의 모든 요소를 하나의 문자열로 연결해서 반환
➜ 스트림의 요소가 CharSequence의 자손인 경우에만 결합 가능 ( String이나 StringBuffer처럼 )
➜ 따라서, 문자열이 아닌 경우엔 먼저 ' map() ' 을 이용해서 문자열로 변화해줘야 한다 !
studentNames.map(Student::getName).collect(joining()); // A B C ...
// 구분자 지정 가능
studentNames.map(Student::getName).collect(joining(", ")); // A, B, C, ...
// 접두사, 접미사 지정 가능
studentNames.map(Student::getName).collect(joining(", ", "[", "]")); [A, B, C ...]
✔️ 그룹화와 분할 - groupingBy(), partitioningBy()
🔹 그룹화와 분할
- ' collect() ' 를 왜 알아야 하고, 어떤 부분에서 유용한지 알 수 있는 작업이 그룹화와 분할이다
- 그룹화 - groupingBy()
➜ 스트림의 요소를 특정 기준으로 그룹화하는 것을 의미 - 분할 - partitioningBy()
➜ 스트림의 요소를 두 가지(지정된 조건에 일치하는 그룹, 일치하지 않는 그릅)로 분할 - ' groupingBy ' & ' partitioningBy() '
- 차이 - 분류를 Function으로 하는가, Predicate로 하는가
- 스트림을 두 개의 그룹으로 나눠야 한다면 당연히 ' partitioningBy() ' 가 효율적
( 그 외엔 ' groupingByu() ' 를 쓰자 ) - 그룹화와 분할의 결과는 Map에 담겨 반환된다
- 차이 - 분류를 Function으로 하는가, Predicate로 하는가
🔹 분할 - partitioningBy()에 의한 분류
- Predicate로 분류한다
Collector partitioningBy(Predicate predicate)
Collector partitioningBy(Predicate predicate, Collector downstream)
- 기본적인 분할
Map<Boolean, List<Student>> studentByGender = studentStream.collect(partitioningBy(Student::isMale));
List<Student> maleStudent = studentByGender.get(true)
List<Student> femaleStudent = studentByGender.get(false)
- 통계 정보를 이용한 분할
Map<Boolean, Long> stuNumByGender = studentStream.collect(partitioningBy(Student::isMale, counting()));
stuNumByGender.get(true)
stuNumByGender.get(false)
- ' partitioningBy() ' 도 중첩하여 사용 가능하다
// 불합격자를 분류하고, 성별로 또 분류
Map<Boolean, Map<Boolean, List<Student>>> failedStuByGender
= stuStream.collect(
partitioningBy(Student::isMale,
partitioningBy(s -> s.getScore() < 15)
)
);
List<Student> failedMaleStu = failedStuByGender.get(true).get(true);
List<Student> failedFemaleStu = failedStuByGender.get(false).get(true);
- ' collectingAndThen() ' 을 활용하면 'collecting' 을 진행한 후(AndThen) 얻은 결과로 메서드를 하나 더 호출 가능하다
Map<Boolean, Map<Boolean, List<Student>>> failedStuByGender
= stuStream.collect(
partitioningBy(Student::isMale,
// maxBy ➜ 남학생 1등과 여학생 1등을 구한다
// Optional::get
// ➜ maxBy의 반환타입이 Optional<Student>이기 때문에
// ➜ Optional<Student>가 아닌 Student를 반환 결과로 얻는다
collectingAndThen(
maxBy(comparingInt(Student::getScore)), Optional::get
)
)
);
🔹 그룹화 - groupingBy()에 의한 분류
- Function으로 분류
➜ 스트림을 특정 기준으로 그룹화
Collector groupingBy(Function classifier)
Collector groupingBy(Function classifier, Collector downstream)
Collector groupingBy(Function classifer, Supplier mapFactory, Collector downstream)
- ' groupingBy() '로 그룹화를 하면 기본적으로 List<T>에 담긴다 ( toList() 생략 )
➜ toList() 대신 toSet()이나 toCollection(HashSet::new) 사용 가능
( 단, Map의 지네릭 타입도 적절하게 변경해주자 )
Map<Integer, List<Student>> studentByBan = students
.collect(groupingBy(Student::getBan, toList())); // toList() 생략 가능
- ' partitioningBy() ' 처럼 중첩 가능
- ' partitioningBy() ' 처럼 ' collectingAndThen() ' 을 활용하면 'collecting' 을 진행한 후(AndThen) 얻은 결과로 메서드를 하나 더 호출 가능하다
( 변환하는 ' mapping() ' 메서드도 ' collectingAndThen() ' 처럼 사용 가능하다 )
✔️ Collector 구현
🔹 컬렉터를 작성한다는 것 = Collector interface를 구현한다는 것
- 직접 구현해야 하는 메서드는 총 5개인데, ' characteristics() ' 메서드를 제외하면 모두 반환타입이 함수형 인터페이스이다
➜ 즉, 4개의 람다식을 작성하면 되는 것 !
public interface Collector<T, A, R> {
Supplier<A> supplier(); // 작업(수집; collect) 결과를 저장할 공간을 제공
BiConsumer<A, T> accumulator(); // 스트림의 요소를 수집(collect)할 방법을 제공
// 스트림의 요소를 'supplier()'가 제공한 공간에 어떻게 누적할 것인가
BinaryOperator<A> combiner(); // 두 저장공간을 병합할 방법을 제공 (병렬스트림)
// 여러 쓰레드에 의해 처리된 결과를 어떻게 합칠 것인가
Function<A, R> finisher(); // 작업 결과를 최종적으로 변환할 방법을 제공
// 변환이 필요없다면, 항등 함수인 'Function.identity()' 반환
Set<Characteristics> characteristics(); // 컬렉터의 특성이 담긴 Set을 반환
// 컬렉터가 수행하는 작업의 속성에 대한 정보 제공
...
}Characteristics.CONCURRENT ➜ 병렬로 처리할 수 있는 작업
Characteristics.UNORDERED ➜ 스트림의 요소의 순서가 유지될 필요가 없는 작업
Characteristics.IDENTITY_FINISH ➜ 'finisher()'가 항등 함수인 작업
➜ 3가지 속성 중에서 해당하는 것을 Set에 담아서 반환하도록 구현하면 된다
( 아무런 속성도 지정하고 싶지 않으면 비어있는 Set 반환 )
public Set<Characteristics> characteristics() {
return Collections.unmodifableSet(EnumSet.of(
Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED
));
}
// 아무 속성 X
Set<Characteristics> characteristics() {
return Collections.emptySet();
}
- Stream<String>의 모든 문자열을 하나로 결합해서 String으로 반환하는 ConcatCollector
import java.util.*;
import java.util.function.*;
import java.util.stream.*;
class MyCollector {
public static void main(String[] args) {
String[] strArr = { "aaa", "bbb", "ccc" };
Stream<String> strStream = Stream.of(strArr);
String result = strStream.collect(new ConcatCollector());
System.out.println(result);
}
}
class ConcatCollector implements Collector<String, StringBuilder, String> {
@Override
public Supplier<StringBuilder> supplier() { // 저장할 공간 생성
return() -> new StringBuilder();
// return StringBuilder::new;
}
@Override
public BiConsumer<StringBuilder, String> accumulator() { // 수집하여 저장하는 방법
return (sb, s) -> sb.append(s);
// return StringBuilder::apend;
}
@Override
public BinaryOperator<StringBuilder> combiner() { // 두 저장공간(StringBuilder) 결합
return (sb, sb2) -> sb.append(sb2);
// return StringBuilder::append;
}
@Override
public Function<StringBuilder, String> finisher() { // 반환할 타입(String)으로 변환하여 반환
return sb -> sb.toString();
// return StringBuilder::toString;
}
@Override
public Set<Characteristics> characteristics() {
return Collections.emptySet();
}
}aaabbbccc
🌓 스트림(Stream)의 변환
✔️ 스트림(Stream) 간의 변환
🔹 스트림 변화에 사용되는 메서드를 정리한 표
- 변환 방법은 어렵지 않지만 언제 어떤 메서드를 써야하는지 매번 찾아보기 어렵다