
-
▼ Why ?
-
▼ 스택 (Stack)
-
스택(Stack) ?
-
스택(Stack)의 연산
-
스택(Stack)은 언제 사용하는 것이 좋을까?
-
▼ 큐 (Queue)
-
큐 (Queue) ?
-
큐(Queue)의 연산
-
큐(Queue)의 접근
-
큐(Queue)는 언제 사용하는 것이 좋을까 ?
-
▼ 정렬 (Sort)
-
오름차순 정렬 - Arrays.sort()
-
내림차순 정렬 - Arrays.sort()
-
ArrayList 정렬 - Collections.sort()
-
▼ 그리디(Greedy; 탐욕) 알고리즘
-
그리디 알고리즘 (Greedy Algorithm) ?
-
그리디 알고리즘은 언제 쓸까 ?
▼ Why ?
이제 스택, 큐, 정렬, 그리고 그리디 알고리즘을 활용하는 문제를 풀어보려고 한다. 그 전에 일단 스택, 큐, 정렬에 대한 개념을 간단하게 정리해보고(좀 더 자세한 내용은 "[JAVA] 컬렉션 프레임웍 ( Collections Framework )" 참고), 그리디 알고리즘이 무엇인지 공부해보려고 한다.
▼ 스택 (Stack)
스택(Stack) ?
- 한 쪽 끝에서만 자료를 넣고 뺄 수 있는 LIFO(Last In Fisrt Out) 형식의 자료구조이다
스택(Stack)의 연산
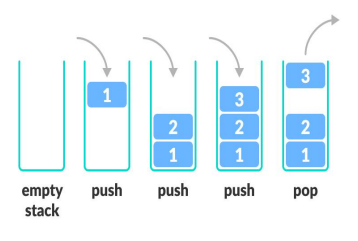
- Object push(Object item) : 객체(item) 하나를 Stack의 가장 위에 추가
- Object pop() : Stack에서 가장 위에 저장된 객체를 반환하고 삭제
- Object peek() : Stack의 가장 위에 있는 객체를 반환 (삭제 X)
- boolean empty() : Stack이 비어있으면 true를 반환
( Collection interface에 정의돼 있는 ' boolean isEmpty() ' 같은 메서드들은 하위 interface(List, Queue, Set)를 구현한 class들도 사용 가능하다 )
- Stack에서 pop(), peek()을 하기 전에 emtpy()로 Stack이 비어있는지 먼저 체크하자
( 비어있는데 해당 작업을 수행하면 에러 발생 )
➜ 보통 ' while(!stack.empty()) ' 로 많이 체크한다
- Stack에서 pop(), peek()을 하기 전에 emtpy()로 Stack이 비어있는지 먼저 체크하자
Stack (Java SE 19 & JDK 19) (oracle.com)
Stack (Java SE 19 & JDK 19)
Type Parameters: E - Type of component elements All Implemented Interfaces: Serializable, Cloneable, Iterable , Collection , List , RandomAccess public class Stack extends Vector The Stack class represents a last-in-first-out (LIFO) stack of objects. It ex
docs.oracle.com
스택(Stack)은 언제 사용하는 것이 좋을까?
- 짝꿍(Pair)의 개념으로 자신의 짝을 찾을 때 ( ex. 이웃한 게 충돌해서 사라지는 경우)
- 입력에 괄호()가 있을 때
▼ 큐 (Queue)
큐 (Queue) ?
- 한 쪽 끝에서 자료가 삽입되고, 반대쪽 끝에서 자료가 삭제되는 FIFO(First In First Out) 형식의 자료구조
- 데이터를 꺼낼 때 항상 처음 위치(index)의 데이터를 삭제하므로, 삽입/삭제가 쉬운 LinkedList로 구현하는 것이 적합하다
➜ Java에선 Queue를 interface로만 정의해놓고 Stack처럼 별도의 class를 제공하지 않는다
➜ 대신 Queue interface를 구현한 여러 class들이 있는데 그 중에 하나가 LinkedList class !
Queue<Integer> queue = new LinkedList<>();
큐(Queue)의 연산
- boolean offer(Object o) : Queue에 데이터를 삽입하고, 성공하면 true, 실패하면 false를 반환
( boolean add(Object o) : 같은 기능이지만, 저장공간이 부족하면 IllegalStateException 발생 ) - Object poll() : Queue에서 가장 앞에 있는 객체를 꺼내서 반환 (삭제 O)
( Object remove() : 같은 기능이지만, NoSuchElementException 발생 )
큐(Queue)의 접근
- E peek() : 첫 번째 데이터 반환
- Iterator iterator() : 데이터를 지우지 않고 순회할 경우에 사용
Iterator<Integer> iter = pq.iterator();
while(iter.hasNext()) {
Integer i = iter.next();
System.out.print(i + " ");
}
Queue (Java SE 19 & JDK 19) (oracle.com)
Queue (Java SE 19 & JDK 19)
Type Parameters: E - the type of elements held in this queue All Superinterfaces: Collection , Iterable All Known Subinterfaces: BlockingDeque , BlockingQueue , Deque , TransferQueue All Known Implementing Classes: AbstractQueue, ArrayBlockingQueue, ArrayD
docs.oracle.com
큐(Queue)는 언제 사용하는 것이 좋을까 ?
- 너비우선탐색(BFS)에 많이 사용한다 ! ( 단독으로 나오면 난이도가 상당히 높을 수 있다 )
- 자료가 원형(순환) 구조를 이루 때
▼ 정렬 (Sort)
오름차순 정렬 - Arrays.sort()
int[] nums = {1, 5, 3, 4};
Arrays.sort(nums);- ' sort() ' 메서드는 클래스 메서드이기 때문에, ' Arrays.sort() ' 처럼 instance 없이 바로 호출 가능하다
- ' Arrays.sort() ' 메서드의 기본 정렬조건은 오름차순인데, 그 이유는 Arrays class에 아래처럼 오름차순을 기준으로 구현돼 있기 때문이다
public static void sort(int[] a) {
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}
- 따라서, 정수형 배열(int[], long[], etc.), char[], T[], 즉 기본형(Primitive) 배열은 모두 ' Arrays.sort() ' 메서드만으로 오름차순 정렬이 가능하다
내림차순 정렬 - Arrays.sort()
int[] nums = new int[]{1, 3, 5, 2};
Integer[] boxedNums = Arrays.stream(nums).boxed().toArray(Integer[]::new);
Arrays.sort(boxedNums, Collections.reverseOrder()); // OK
Arrays.sort(boxedNums, (a, b) -> b - a); // OK
// Arrays.sort(nums, Collections.reverseOrder()); // Error
// Arrays.sort(nums, (a, b) -> b - a); // Error
// 음수의 끝지점은 잘 정렬이 안된다 (-2147483645정도까지만 정렬)- stream을 사용하면 가독성이 좋아지는 대신 속도가 for문에 비해 매우 느려서 웬만하면 for문을 사용하자 !
- 기본 정렬 기준(오름차순)이 아니라 다른 기준으로 정렬할 때엔, ' Arrays.sort() ' 로 정렬하려는 대상은 기본형 배열이 아닌 객체 배열이나 2차원 배열이어야 한다는 것을 기억하자
➙ 정렬하려는 대상이 ' int[] ' 처럼 기본형(Primitive) 타입의 배열이라면(String은 기본형 타입 X), 이를 Object class의 하위 class인 Wrapper class 타입으로 변환(stream 이용)하여 매개변수로 전달해줘야 한다
또는, Collections class 타입으로 변환시켜 ' Collections.sort() ' 를 이용하는 방법도 있다
( 오름차순 정렬의 경우엔 기본형(Primitive) 타입의 배열을 받는 ' sort() ' 메서드가 따로 제공되기 때문에 가능했던 것 )
// Arrays
static <T> void sort(T[] a, Comparator<? super T> c)
( sort() 관련 참고 ) [Algorithm] Arrays.sort(), Collection.sort() (+ 참조 지역성, cache) — Uykm_Note (tistory.com)
[Algorithm] Arrays.sort(), Collection.sort() (+ 참조 지역성, cache)
▼ Why ? " [PCCP] 문자열과 해시함수 [4] " 를 풀면서 정렬하여 해결하는 방식을 생각하다가 ' Arrays.sort() ' 와 ' Collection.sort() ' 의 차이는 알아두는 것이 좋을 것 같아 찾아보게 되었다 ▼ Arrays.sort()
ukym-tistory.tistory.com
( stream 관련 참고 ) https://velog.io/@kyy00n/JAVA-Stream
[JAVA] Stream
익'스트림' 자바 ꉂꉂ(ᵔᗜᵔ*)
velog.io
- 오름차순과 달리 내림차순 같이 특별한 정렬 조건에 따라 정렬해야 할 때엔, Comparator를 구현한 class 내에서 ' compare() ' 메서드를 원하는 기준으로 오버라이딩(Overriding)해준 것을, 즉 비교 방법을 ' Arrays.sort() ' 의 매개변수에 제공해줘야 한다
- 보통 Comparator interface를 구현할 때는 익명 객체(익명 클래스)와 람다식을 이용해서 간단하게 ' compare() '메서드를 오버라이딩 해준다
➙ 람다식을 이용하여 Comparator를 구현해준 경우에 정렬 기준을 추가하고 싶다면 아래처럼 삼항 연산자를 이용하자
( 좌표를 정렬하는 예시 코드이다 )
- 보통 Comparator interface를 구현할 때는 익명 객체(익명 클래스)와 람다식을 이용해서 간단하게 ' compare() '메서드를 오버라이딩 해준다
// nums : 기본형(Primitive) 2차원 배열
// [x, y]에서 x값에 의한 오름차순을 하되 x값이 같은 경우는 y값에 따라 내림차순한다.
Arrays.sort(nums, (a, b) -> a[0] == b[0] ? b[1] - [1] : a[0] - b[0]);
- 사실, 내림차순도 자주 사용되는 정렬기준이기 때문에 Java에서 미리 제공을 해주는데,
Comparator interface의 정의된 ' compareTo() ' 메서드를 오버라이딩 해주지 않아도 ' sort() ' 메서드의 매개변수에 ' Collections.reverseOrder() ' 를 비교 방법으로 전달해주면 내림차순 정렬이 가능하긴 하다
( 리스트를 반대로 뒤집어주는 ' Collections.reverse() ' 메서드도 제공 )
( Comparable, Comparator 관련 참고 ) [JAVA] 컬렉션 프레임웍 ( Collections Framework ) — Uykm_Note (tistory.com)
[JAVA] 컬렉션 프레임웍 ( Collections Framework )
🌑 컬렉션 프레임웍 (Collections Framework) ✔️ Collections Framework의 핵심 interface 🔸 Vector · Hashtable과 같은 기존의 Collections class들 대신 ArrayList · HashMap 을 사용하자 기존의 Collections class들은 호환을
ukym-tistory.tistory.com
ArrayList 정렬 - Collections.sort()
- 좌표 [x, y]에서 x값을 기준으로 한 오름차순 정렬
ArrayList<int[]> list = new ArrayList<>();
for(int[] x : meetings){
list.add(new int[]{x[0], 1});
list.add(new int[]{x[1], 2});
}
// list.sort((a, b) -> a[0] - b[0]);
Collections.sort(list, (a, b) -> a[0] - b[0]);
- Collections class에선 내림차순 정렬(reverseOrder())은 제공하지 않지만, 리스트를 반대로 뒤집어주는 ' Collections.reverse() ' 메서드는 제공해준다
▼ 그리디(Greedy; 탐욕) 알고리즘
그리디 알고리즘 (Greedy Algorithm) ?
- 선택의 순간마다 당장 눈앞에 보이는 최고의 상황만을 쫓아 최종적인 해답에 도달하는 알고리즘 !
➙ 즉, 그때그때 제일 좋은 것만 선택하는 알고리즘이다 ! - 보통 정렬(sort)과 연관되어 있는 경우가 많다
그리디 알고리즘은 언제 쓸까 ?
- 그리디 알고리즘에 반례가 되는 경우(Edge case)를 테스트 해보고 성공하면 그리디 알고리즘으로 해결하는 문제이다 !
아래처럼 그리디 알고리즘 관련 문제인 것 같아도 아닌 경우가 있으니, 반례(Edge case)를 찾아보는 연습 필요 ! - 예시 문제
일렬로 놓여 있는 숫자 카드에서 왼쪽 맨 끝과 오른쪽 맨 끝 카드 중 하나를 가져가는 방식으로 4개의 카드를 가져갔을 때 가져간 카드의 숫자 합의 최댓값은?
➙ 이 문제는 그리디 알고리즘으로 해결하는 문제인가 ?
문제만 보면 그리디 알고리즘으로 해결할 수 있는 문제같다고 착각..
하지만, Edge case인 ' [2, 3, 4, 7, 2, 1, 5] ' 에 그리디 알고리즘을 적용시켜보면, ' 2 + 3 + 4 + 7 = 16 ' 가 아닌 ' 5 + 2 + 3 + 4 = 14 ' 가 최대값이라는 결과가 나오게 된다
➙ 이처럼 Edge case를 테스트해봤을 때 올바른 결과 나오지 않는다면, 그리디 알고리즘으로 해결하는 문제가 아니다 ! - 최적해(최대, 최솟값)을 구할 때 그리디 알고리즘으로 해결할 수도 있다
- 입력이 정렬되어 있으면 그리디 알고리즘 관련 문제일 확률이 높다
▼ Why ?
이제 스택, 큐, 정렬, 그리고 그리디 알고리즘을 활용하는 문제를 풀어보려고 한다. 그 전에 일단 스택, 큐, 정렬에 대한 개념을 간단하게 정리해보고(좀 더 자세한 내용은 "[JAVA] 컬렉션 프레임웍 ( Collections Framework )" 참고), 그리디 알고리즘이 무엇인지 공부해보려고 한다.
▼ 스택 (Stack)
스택(Stack) ?
- 한 쪽 끝에서만 자료를 넣고 뺄 수 있는 LIFO(Last In Fisrt Out) 형식의 자료구조이다
스택(Stack)의 연산
- Object push(Object item) : 객체(item) 하나를 Stack의 가장 위에 추가
- Object pop() : Stack에서 가장 위에 저장된 객체를 반환하고 삭제
- Object peek() : Stack의 가장 위에 있는 객체를 반환 (삭제 X)
- boolean empty() : Stack이 비어있으면 true를 반환
( Collection interface에 정의돼 있는 ' boolean isEmpty() ' 같은 메서드들은 하위 interface(List, Queue, Set)를 구현한 class들도 사용 가능하다 )
- Stack에서 pop(), peek()을 하기 전에 emtpy()로 Stack이 비어있는지 먼저 체크하자
( 비어있는데 해당 작업을 수행하면 에러 발생 )
➜ 보통 ' while(!stack.empty()) ' 로 많이 체크한다
- Stack에서 pop(), peek()을 하기 전에 emtpy()로 Stack이 비어있는지 먼저 체크하자
Stack (Java SE 19 & JDK 19) (oracle.com)
Stack (Java SE 19 & JDK 19)
Type Parameters: E - Type of component elements All Implemented Interfaces: Serializable, Cloneable, Iterable , Collection , List , RandomAccess public class Stack extends Vector The Stack class represents a last-in-first-out (LIFO) stack of objects. It ex
docs.oracle.com
스택(Stack)은 언제 사용하는 것이 좋을까?
- 짝꿍(Pair)의 개념으로 자신의 짝을 찾을 때 ( ex. 이웃한 게 충돌해서 사라지는 경우)
- 입력에 괄호()가 있을 때
▼ 큐 (Queue)
큐 (Queue) ?
- 한 쪽 끝에서 자료가 삽입되고, 반대쪽 끝에서 자료가 삭제되는 FIFO(First In First Out) 형식의 자료구조
- 데이터를 꺼낼 때 항상 처음 위치(index)의 데이터를 삭제하므로, 삽입/삭제가 쉬운 LinkedList로 구현하는 것이 적합하다
➜ Java에선 Queue를 interface로만 정의해놓고 Stack처럼 별도의 class를 제공하지 않는다
➜ 대신 Queue interface를 구현한 여러 class들이 있는데 그 중에 하나가 LinkedList class !
Queue<Integer> queue = new LinkedList<>();
큐(Queue)의 연산
- boolean offer(Object o) : Queue에 데이터를 삽입하고, 성공하면 true, 실패하면 false를 반환
( boolean add(Object o) : 같은 기능이지만, 저장공간이 부족하면 IllegalStateException 발생 ) - Object poll() : Queue에서 가장 앞에 있는 객체를 꺼내서 반환 (삭제 O)
( Object remove() : 같은 기능이지만, NoSuchElementException 발생 )
큐(Queue)의 접근
- E peek() : 첫 번째 데이터 반환
- Iterator iterator() : 데이터를 지우지 않고 순회할 경우에 사용
Iterator<Integer> iter = pq.iterator();
while(iter.hasNext()) {
Integer i = iter.next();
System.out.print(i + " ");
}
Queue (Java SE 19 & JDK 19) (oracle.com)
Queue (Java SE 19 & JDK 19)
Type Parameters: E - the type of elements held in this queue All Superinterfaces: Collection , Iterable All Known Subinterfaces: BlockingDeque , BlockingQueue , Deque , TransferQueue All Known Implementing Classes: AbstractQueue, ArrayBlockingQueue, ArrayD
docs.oracle.com
큐(Queue)는 언제 사용하는 것이 좋을까 ?
- 너비우선탐색(BFS)에 많이 사용한다 ! ( 단독으로 나오면 난이도가 상당히 높을 수 있다 )
- 자료가 원형(순환) 구조를 이루 때
▼ 정렬 (Sort)
오름차순 정렬 - Arrays.sort()
int[] nums = {1, 5, 3, 4};
Arrays.sort(nums);- ' sort() ' 메서드는 클래스 메서드이기 때문에, ' Arrays.sort() ' 처럼 instance 없이 바로 호출 가능하다
- ' Arrays.sort() ' 메서드의 기본 정렬조건은 오름차순인데, 그 이유는 Arrays class에 아래처럼 오름차순을 기준으로 구현돼 있기 때문이다
public static void sort(int[] a) {
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}
- 따라서, 정수형 배열(int[], long[], etc.), char[], T[], 즉 기본형(Primitive) 배열은 모두 ' Arrays.sort() ' 메서드만으로 오름차순 정렬이 가능하다
내림차순 정렬 - Arrays.sort()
int[] nums = new int[]{1, 3, 5, 2};
Integer[] boxedNums = Arrays.stream(nums).boxed().toArray(Integer[]::new);
Arrays.sort(boxedNums, Collections.reverseOrder()); // OK
Arrays.sort(boxedNums, (a, b) -> b - a); // OK
// Arrays.sort(nums, Collections.reverseOrder()); // Error
// Arrays.sort(nums, (a, b) -> b - a); // Error
// 음수의 끝지점은 잘 정렬이 안된다 (-2147483645정도까지만 정렬)- stream을 사용하면 가독성이 좋아지는 대신 속도가 for문에 비해 매우 느려서 웬만하면 for문을 사용하자 !
- 기본 정렬 기준(오름차순)이 아니라 다른 기준으로 정렬할 때엔, ' Arrays.sort() ' 로 정렬하려는 대상은 기본형 배열이 아닌 객체 배열이나 2차원 배열이어야 한다는 것을 기억하자
➙ 정렬하려는 대상이 ' int[] ' 처럼 기본형(Primitive) 타입의 배열이라면(String은 기본형 타입 X), 이를 Object class의 하위 class인 Wrapper class 타입으로 변환(stream 이용)하여 매개변수로 전달해줘야 한다
또는, Collections class 타입으로 변환시켜 ' Collections.sort() ' 를 이용하는 방법도 있다
( 오름차순 정렬의 경우엔 기본형(Primitive) 타입의 배열을 받는 ' sort() ' 메서드가 따로 제공되기 때문에 가능했던 것 )
// Arrays
static <T> void sort(T[] a, Comparator<? super T> c)
( sort() 관련 참고 ) [Algorithm] Arrays.sort(), Collection.sort() (+ 참조 지역성, cache) — Uykm_Note (tistory.com)
[Algorithm] Arrays.sort(), Collection.sort() (+ 참조 지역성, cache)
▼ Why ? " [PCCP] 문자열과 해시함수 [4] " 를 풀면서 정렬하여 해결하는 방식을 생각하다가 ' Arrays.sort() ' 와 ' Collection.sort() ' 의 차이는 알아두는 것이 좋을 것 같아 찾아보게 되었다 ▼ Arrays.sort()
ukym-tistory.tistory.com
( stream 관련 참고 ) https://velog.io/@kyy00n/JAVA-Stream
[JAVA] Stream
익'스트림' 자바 ꉂꉂ(ᵔᗜᵔ*)
velog.io
- 오름차순과 달리 내림차순 같이 특별한 정렬 조건에 따라 정렬해야 할 때엔, Comparator를 구현한 class 내에서 ' compare() ' 메서드를 원하는 기준으로 오버라이딩(Overriding)해준 것을, 즉 비교 방법을 ' Arrays.sort() ' 의 매개변수에 제공해줘야 한다
- 보통 Comparator interface를 구현할 때는 익명 객체(익명 클래스)와 람다식을 이용해서 간단하게 ' compare() '메서드를 오버라이딩 해준다
➙ 람다식을 이용하여 Comparator를 구현해준 경우에 정렬 기준을 추가하고 싶다면 아래처럼 삼항 연산자를 이용하자
( 좌표를 정렬하는 예시 코드이다 )
- 보통 Comparator interface를 구현할 때는 익명 객체(익명 클래스)와 람다식을 이용해서 간단하게 ' compare() '메서드를 오버라이딩 해준다
// nums : 기본형(Primitive) 2차원 배열
// [x, y]에서 x값에 의한 오름차순을 하되 x값이 같은 경우는 y값에 따라 내림차순한다.
Arrays.sort(nums, (a, b) -> a[0] == b[0] ? b[1] - [1] : a[0] - b[0]);
- 사실, 내림차순도 자주 사용되는 정렬기준이기 때문에 Java에서 미리 제공을 해주는데,
Comparator interface의 정의된 ' compareTo() ' 메서드를 오버라이딩 해주지 않아도 ' sort() ' 메서드의 매개변수에 ' Collections.reverseOrder() ' 를 비교 방법으로 전달해주면 내림차순 정렬이 가능하긴 하다
( 리스트를 반대로 뒤집어주는 ' Collections.reverse() ' 메서드도 제공 )
( Comparable, Comparator 관련 참고 ) [JAVA] 컬렉션 프레임웍 ( Collections Framework ) — Uykm_Note (tistory.com)
[JAVA] 컬렉션 프레임웍 ( Collections Framework )
🌑 컬렉션 프레임웍 (Collections Framework) ✔️ Collections Framework의 핵심 interface 🔸 Vector · Hashtable과 같은 기존의 Collections class들 대신 ArrayList · HashMap 을 사용하자 기존의 Collections class들은 호환을
ukym-tistory.tistory.com
ArrayList 정렬 - Collections.sort()
- 좌표 [x, y]에서 x값을 기준으로 한 오름차순 정렬
ArrayList<int[]> list = new ArrayList<>();
for(int[] x : meetings){
list.add(new int[]{x[0], 1});
list.add(new int[]{x[1], 2});
}
// list.sort((a, b) -> a[0] - b[0]);
Collections.sort(list, (a, b) -> a[0] - b[0]);
- Collections class에선 내림차순 정렬(reverseOrder())은 제공하지 않지만, 리스트를 반대로 뒤집어주는 ' Collections.reverse() ' 메서드는 제공해준다
▼ 그리디(Greedy; 탐욕) 알고리즘
그리디 알고리즘 (Greedy Algorithm) ?
- 선택의 순간마다 당장 눈앞에 보이는 최고의 상황만을 쫓아 최종적인 해답에 도달하는 알고리즘 !
➙ 즉, 그때그때 제일 좋은 것만 선택하는 알고리즘이다 ! - 보통 정렬(sort)과 연관되어 있는 경우가 많다
그리디 알고리즘은 언제 쓸까 ?
- 그리디 알고리즘에 반례가 되는 경우(Edge case)를 테스트 해보고 성공하면 그리디 알고리즘으로 해결하는 문제이다 !
아래처럼 그리디 알고리즘 관련 문제인 것 같아도 아닌 경우가 있으니, 반례(Edge case)를 찾아보는 연습 필요 ! - 예시 문제
일렬로 놓여 있는 숫자 카드에서 왼쪽 맨 끝과 오른쪽 맨 끝 카드 중 하나를 가져가는 방식으로 4개의 카드를 가져갔을 때 가져간 카드의 숫자 합의 최댓값은?
➙ 이 문제는 그리디 알고리즘으로 해결하는 문제인가 ?
문제만 보면 그리디 알고리즘으로 해결할 수 있는 문제같다고 착각..
하지만, Edge case인 ' [2, 3, 4, 7, 2, 1, 5] ' 에 그리디 알고리즘을 적용시켜보면, ' 2 + 3 + 4 + 7 = 16 ' 가 아닌 ' 5 + 2 + 3 + 4 = 14 ' 가 최대값이라는 결과가 나오게 된다
➙ 이처럼 Edge case를 테스트해봤을 때 올바른 결과 나오지 않는다면, 그리디 알고리즘으로 해결하는 문제가 아니다 ! - 최적해(최대, 최솟값)을 구할 때 그리디 알고리즘으로 해결할 수도 있다
- 입력이 정렬되어 있으면 그리디 알고리즘 관련 문제일 확률이 높다